 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on Explainable Prediction of Text Complexity: Preliminaries for Text Simplification
Paper and Code
Jul 31, 2020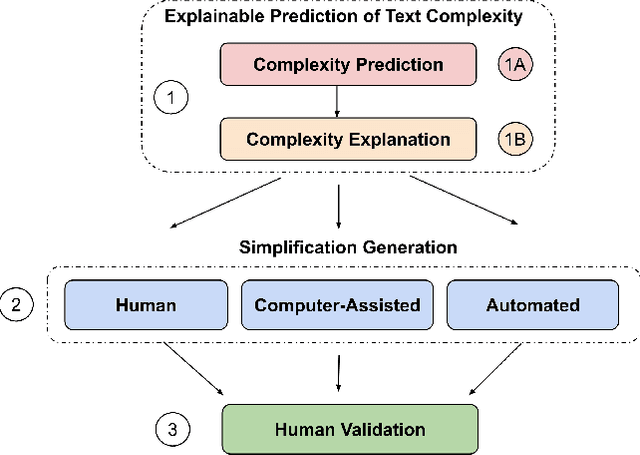
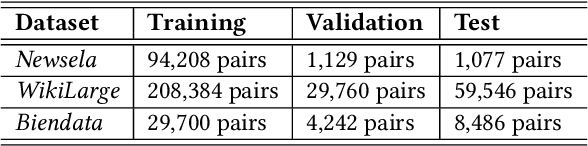

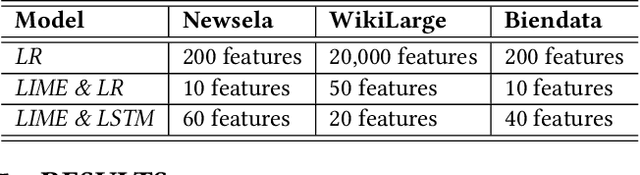
Text simplification is concerned with reducing the language complexity and improving the readability of professional content so that the text is accessible to readers at different ages and educational levels. As a promising practice to improve the fairness and transparency of text information systems, the notion of text simplification has been mixed in existing literature, ranging all the way through assessing the complexity of single words to automatically generating simplified documents. We show that the general problem of text simplification can be formally decomposed into a compact pipeline of tasks to ensure the transparency and explanability of the process. In this paper, we present a systematic analysis of the first two steps in this pipeline: 1) predicting the complexity of a given piece of text, and 2) identifying complex components from the text considered to be complex. We show that these two tasks can be solved separately, using either lexical approaches or the state-of-the-art deep learning methods, or they can be solved jointly through an end-to-end, explainable machine learning predictor. We propose formal evaluation metrics for both tasks, through which we are able to compare the performance of the candidate approaches using multiple datasets from a diversity of domains.