 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference Learning from Physics-Based Feedback: Tuning Language Models to Design BCC/B2 Superalloys
Nov 15, 2025We apply preference learning to the task of language model-guided design of novel structural alloys. In contrast to prior work that focuses on generating stable inorganic crystals, our approach targets the synthesizeability of a specific structural class: BCC/B2 superalloys, an underexplored family of materials with potential applications in extreme environments. Using three open-weight models (LLaMA-3.1, Gemma-2, and OLMo-2), we demonstrate that language models can be optimized for multiple design objectives using a single, unified reward signal through Direct Preference Optimization (DPO). Unlike prior approaches that rely on heuristic or human-in-the-loop feedback (costly), our reward signal is derived from thermodynamic phase calculations, offering a scientifically grounded criterion for model tuning. To our knowledge, this is the first demonstration of preference-tuning a language model using physics-grounded feedback for structural alloy design. The resulting framework is general and extensible, providing a path forward for intelligent design-space exploration across a range of physical science domains.
Toward Reliable Ad-hoc Scientific Information Extraction: A Case Study on Two Materials Datasets
Jun 08, 2024



We explore the ability of GPT-4 to perform ad-hoc schema based information extraction from scientific literature. We assess specifically whether it can, with a basic prompting approach, replicate two existing material science datasets, given the manuscripts from which they were originally manually extracted. We employ materials scientists to perform a detailed manual error analysis to assess where the model struggles to faithfully extract the desired information, and draw on their insights to suggest research directions to address this broadly important task.
Toward Connecting Speech Acts and Search Actions in Conversational Search Tasks
May 08, 2023Conversational search systems can improve user experience in digital libraries by facilitating a natural and intuitive way to interact with library content. However, most conversational search systems are limited to performing simple tasks and controlling smart devices. Therefore, there is a need for systems that can accurately understand the user's information requirements and perform the appropriate search activity. Prior research on intelligent systems suggested that it is possible to comprehend the functional aspect of discourse (search intent) by identifying the speech acts in user dialogues. In this work, we automatically identify the speech acts associated with spoken utterances and use them to predict the system-level search actions. First, we conducted a Wizard-of-Oz study to collect data from 75 search sessions. We performed thematic analysis to curate a gold standard dataset -- containing 1,834 utterances and 509 system actions -- of human-system interactions in three information-seeking scenarios. Next, we developed attention-based deep neural networks to understand natural language and predict speech acts. Then, the speech acts were fed to the model to predict the corresponding system-level search actions. We also annotated a second dataset to validate our results. For the two datasets, the best-performing classification model achieved maximum accuracy of 90.2% and 72.7% for speech act classification and 58.8% and 61.1%, respectively, for search act classification.
Exploring the Ideal Depth of Neural Network when Predicting Question Deletion on Community Question Answering
Dec 08, 2019
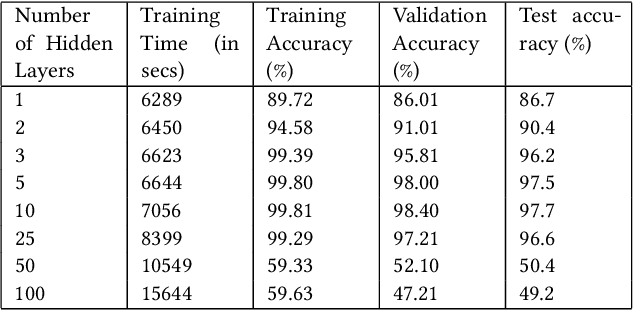
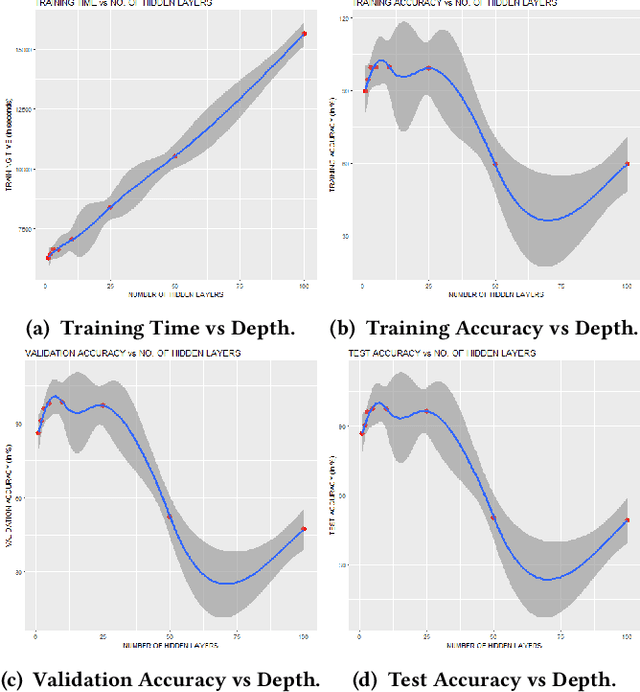

In recent years, Community Question Answering (CQA) has emerged as a popular platform for knowledge curation and archival. An interesting aspect of question answering is that it combines aspects from natural language processing, information retrieval, and machine learning. In this paper, we have explored how the depth of the neural network influences the accuracy of prediction of deleted questions in question-answering forums. We have used different shallow and deep models for prediction and analyzed the relationships between number of hidden layers, accuracy, and computational time. The results suggest that while deep networks perform better than shallow networks in modeling complex non-linear functions, increasing the depth may not always produce desired results. We observe that the performance of the deep neural network suffers significantly due to vanishing gradients when large number of hidden layers are present. Constantly increasing the depth of the model increases accuracy initially, after which the accuracy plateaus, and finally drops. Adding each layer is also expensive in terms of the time required to train the model. This research is situated in the domain of neural information retrieval and contributes towards building a theory on how deep neural networks can be efficiently and accurately used for predicting question deletion. We predict deleted questions with more than 90\% accuracy using two to ten hidden layers, with less accurate results for shallower and deeper architectures.
Sentiment Identification in Code-Mixed Social Media Text
Jul 04, 2017
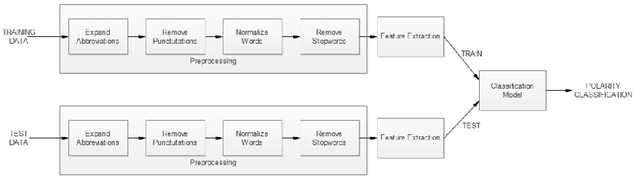
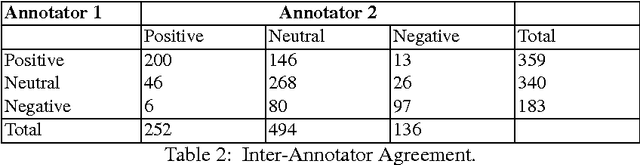
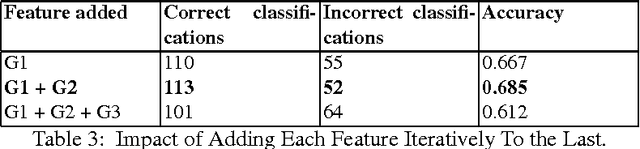
Sentiment analysis is the Natural Language Processing (NLP) task dealing with the detection and classification of sentiments in texts. While some tasks deal with identifying the presence of sentiment in the text (Subjectivity analysis), other tasks aim at determining the polarity of the text categorizing them as positive, negative and neutral. Whenever there is a presence of sentiment in the text, it has a source (people, group of people or any entity) and the sentiment is directed towards some entity, object, event or person. Sentiment analysis tasks aim to determine the subject, the target and the polarity or valence of the sentiment. In our work, we try to automatically extract sentiment (positive or negative) from Facebook posts using a machine learning approach.While some works have been done in code-mixed social media data and in sentiment analysis separately, our work is the first attempt (as of now) which aims at performing sentiment analysis of code-mixed social media text. We have used extensive pre-processing to remove noise from raw text. Multilayer Perceptron model has been used to determine the polarity of the sentiment. We have also developed the corpus for this task by manually labeling Facebook posts with their associated sentiments.
Complexity Metric for Code-Mixed Social Media Text
Jul 04, 2017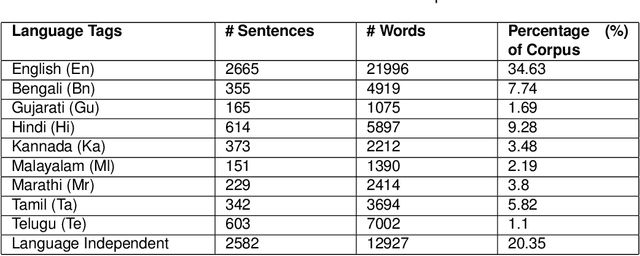

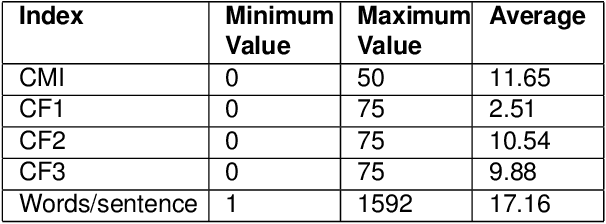
An evaluation metric is an absolute necessity for measuring the performance of any system and complexity of any data. In this paper, we have discussed how to determine the level of complexity of code-mixed social media texts that are growing rapidly due to multilingual interference. In general, texts written in multiple languages are often hard to comprehend and analyze. At the same time, in order to meet the demands of analysis, it is also necessary to determine the complexity of a particular document or a text segment. Thus, in the present paper, we have discussed the existing metrics for determining the code-mixing complexity of a corpus, their advantages, and shortcomings as well as proposed several improvements on the existing metrics. The new index better reflects the variety and complexity of a multilingual document. Also, the index can be applied to a sentence and seamlessly extended to a paragraph or an entire document. We have employed two existing code-mixed corpora to suit the requirements of our study.
Labeling of Query Words using Conditional Random Field
Jul 29, 2016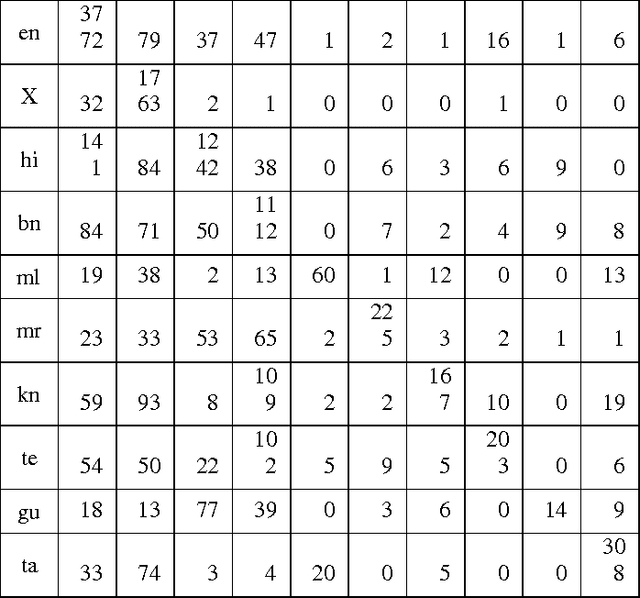
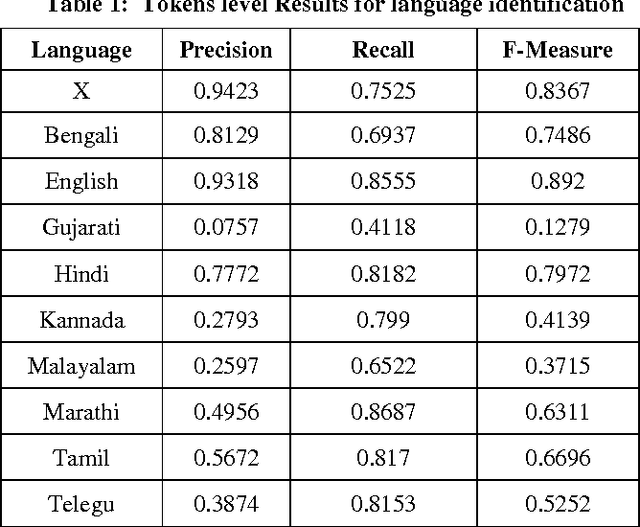

This paper describes our approach on Query Word Labeling as an attempt in the shared task on Mixed Script Information Retrieval at Forum for Information Retrieval Evaluation (FIRE) 2015. The query is written in Roman script and the words were in English or transliterated from Indian regional languages. A total of eight Indian languages were present in addition to English. We also identified the Named Entities and special symbols as part of our task. A CRF based machine learning framework was used for labeling the individual words with their corresponding language labels. We used a dictionary based approach for language identification. We also took into account the context of the word while identifying the language. Our system demonstrated an overall accuracy of 75.5% for token level language identification. The strict F-measure scores for the identification of token level language labels for Bengali, English and Hindi are 0.7486, 0.892 and 0.7972 respectively. The overall weighted F-measure of our system was 0.7498.