 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI in Archival Science -- A Systematic Review
Oct 07, 2024The rapid expansion of records creates significant challenges in management, including retention and disposition, appraisal, and organization. Our study underscores the benefits of integrating artificial intelligence (AI) within the broad realm of archival science. In this work, we start by performing a thorough analysis to understand the current use of AI in this area and identify the techniques employed to address challenges. Subsequently, we document the results of our review according to specific criteria. Our findings highlight key AI driven strategies that promise to streamline record-keeping processes and enhance data retrieval efficiency. We also demonstrate our review process to ensure transparency regarding our methodology. Furthermore, this review not only outlines the current state of AI in archival science and records management but also lays the groundwork for integrating new techniques to transform archival practices. Our research emphasizes the necessity for enhanced collaboration between the disciplines of artificial intelligence and archival science.
Decoding Large-Language Models: A Systematic Overview of Socio-Technical Impacts, Constraints, and Emerging Questions
Sep 25, 2024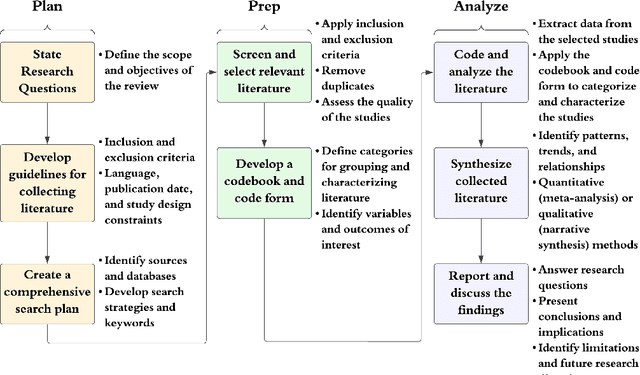

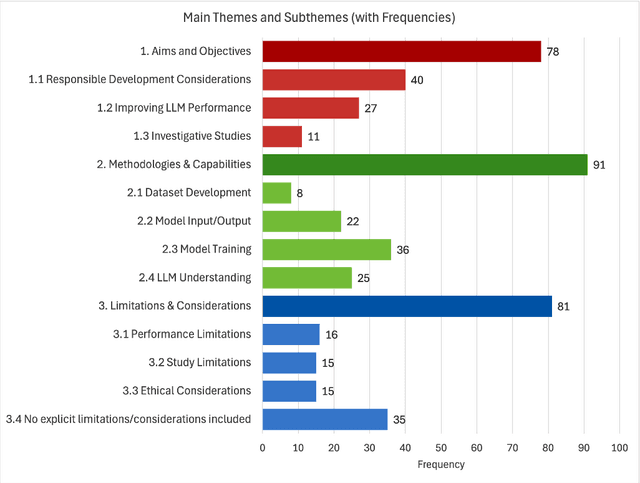
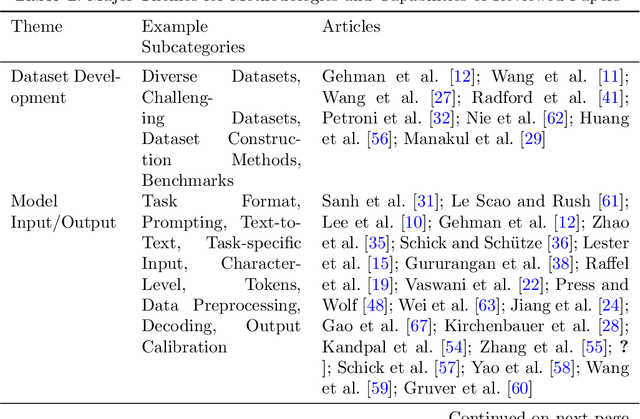
There have been rapid advancements in the capabilities of large language models (LLMs) in recent years, greatly revolutionizing the field of natural language processing (NLP) and artificial intelligence (AI) to understand and interact with human language. Therefore, in this work, we conduct a systematic investigation of the literature to identify the prominent themes and directions of LLM developments, impacts, and limitations. Our findings illustrate the aims, methodologies, limitations, and future directions of LLM research. It includes responsible development considerations, algorithmic improvements, ethical challenges, and societal implications of LLM development. Overall, this paper provides a rigorous and comprehensive overview of current research in LLM and identifies potential directions for future development. The article highlights the application areas that could have a positive impact on society along with the ethical considerations.
Toward Connecting Speech Acts and Search Actions in Conversational Search Tasks
May 08, 2023Conversational search systems can improve user experience in digital libraries by facilitating a natural and intuitive way to interact with library content. However, most conversational search systems are limited to performing simple tasks and controlling smart devices. Therefore, there is a need for systems that can accurately understand the user's information requirements and perform the appropriate search activity. Prior research on intelligent systems suggested that it is possible to comprehend the functional aspect of discourse (search intent) by identifying the speech acts in user dialogues. In this work, we automatically identify the speech acts associated with spoken utterances and use them to predict the system-level search actions. First, we conducted a Wizard-of-Oz study to collect data from 75 search sessions. We performed thematic analysis to curate a gold standard dataset -- containing 1,834 utterances and 509 system actions -- of human-system interactions in three information-seeking scenarios. Next, we developed attention-based deep neural networks to understand natural language and predict speech acts. Then, the speech acts were fed to the model to predict the corresponding system-level search actions. We also annotated a second dataset to validate our results. For the two datasets, the best-performing classification model achieved maximum accuracy of 90.2% and 72.7% for speech act classification and 58.8% and 61.1%, respectively, for search act classification.
"Don't Downvote A\$\$\$\$\$\$s!!": An Exploration of Reddit's Advice Communities
Sep 19, 2021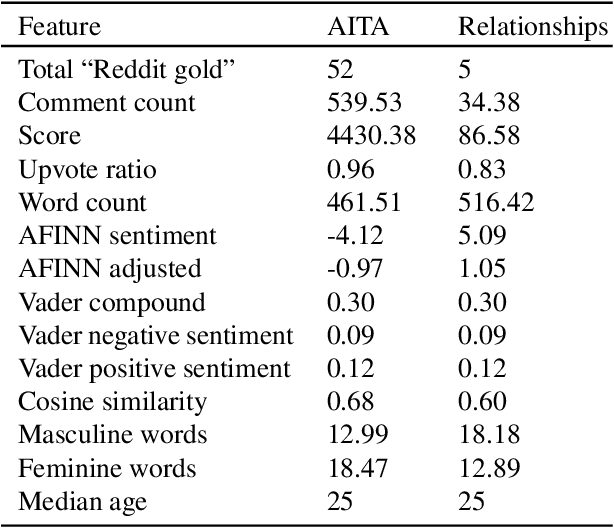
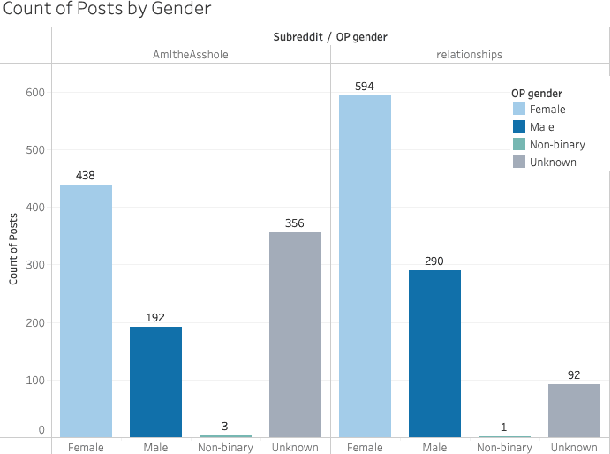
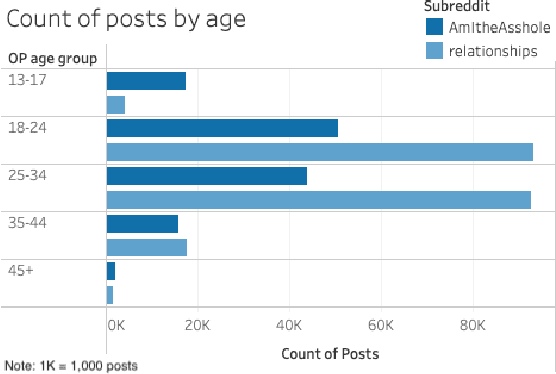
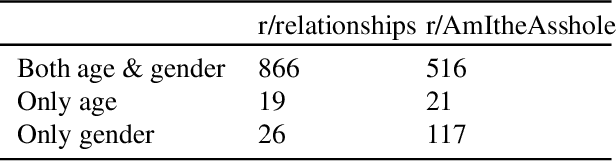
Advice forums are a crowdsourced way to reinforce cultural norms and moral behavior. Sites like Reddit contain massive amounts of natural language human interaction, with rules and norms unique to each individual subreddit community. To explore this data, we created a dataset with top 1000 posts from each of two such forums, r/AmItheAsshole and r/relationships, and extracted natural language features including sentiment, similarity, word frequency, and demographics using both algorithmic and manual methods. Further, we developed a method to extract demographic information from the subreddits, examined how the post authors' self-disclosures reflect the unique communities in which their posts are shared, and discussed how the authors' language use choices might be related to broader social patterns. We observed some differences between the subreddits in terms of word frequency, demographics disclosure, and gendered language. In general, both subreddits had more female posters than male, and posters tended to use more words about their opposite gender than the same. Gender-diverse posters were uncommon. Implications for future research include a more careful, inclusive focus on identity and disclosure and how that interacts with advice-seeking behavior in online communities.
Exploring the Ideal Depth of Neural Network when Predicting Question Deletion on Community Question Answering
Dec 08, 2019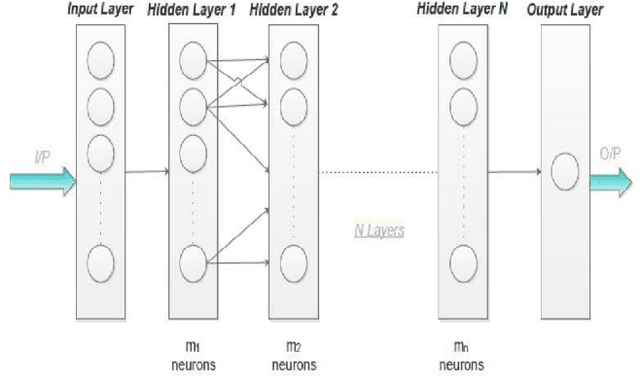
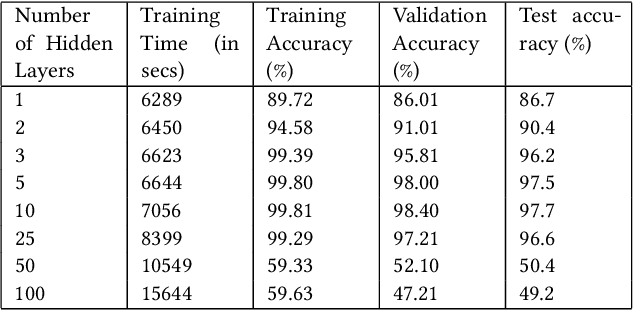
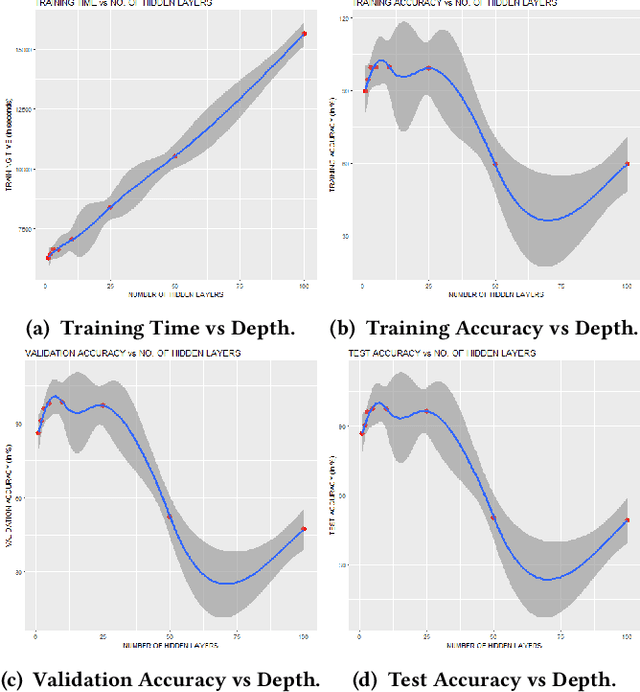

In recent years, Community Question Answering (CQA) has emerged as a popular platform for knowledge curation and archival. An interesting aspect of question answering is that it combines aspects from natural language processing, information retrieval, and machine learning. In this paper, we have explored how the depth of the neural network influences the accuracy of prediction of deleted questions in question-answering forums. We have used different shallow and deep models for prediction and analyzed the relationships between number of hidden layers, accuracy, and computational time. The results suggest that while deep networks perform better than shallow networks in modeling complex non-linear functions, increasing the depth may not always produce desired results. We observe that the performance of the deep neural network suffers significantly due to vanishing gradients when large number of hidden layers are present. Constantly increasing the depth of the model increases accuracy initially, after which the accuracy plateaus, and finally drops. Adding each layer is also expensive in terms of the time required to train the model. This research is situated in the domain of neural information retrieval and contributes towards building a theory on how deep neural networks can be efficiently and accurately used for predicting question deletion. We predict deleted questions with more than 90\% accuracy using two to ten hidden layers, with less accurate results for shallower and deeper architectures.
Determining sentiment in citation text and analyzing its impact on the proposed ranking index
Jul 05, 2017
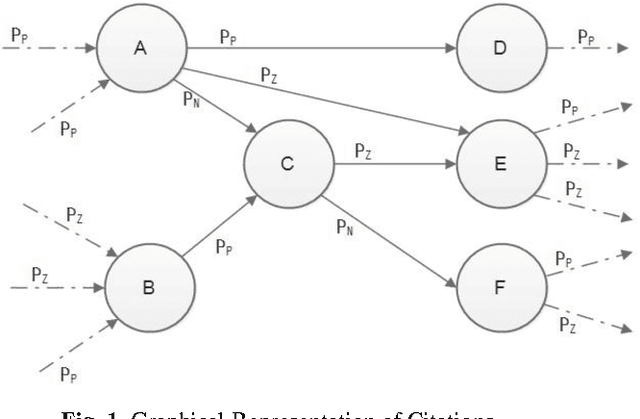

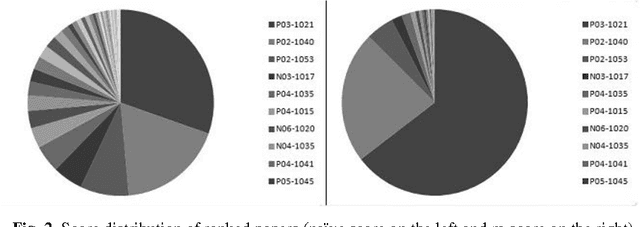
Whenever human beings interact with each other, they exchange or express opinions, emotions, and sentiments. These opinions can be expressed in text, speech or images. Analysis of these sentiments is one of the popular research areas of present day researchers. Sentiment analysis, also known as opinion mining tries to identify or classify these sentiments or opinions into two broad categories - positive and negative. In recent years, the scientific community has taken a lot of interest in analyzing sentiment in textual data available in various social media platforms. Much work has been done on social media conversations, blog posts, newspaper articles and various narrative texts. However, when it comes to identifying emotions from scientific papers, researchers have faced some difficulties due to the implicit and hidden nature of opinion. By default, citation instances are considered inherently positive in emotion. Popular ranking and indexing paradigms often neglect the opinion present while citing. In this paper, we have tried to achieve three objectives. First, we try to identify the major sentiment in the citation text and assign a score to the instance. We have used a statistical classifier for this purpose. Secondly, we have proposed a new index (we shall refer to it hereafter as M-index) which takes into account both the quantitative and qualitative factors while scoring a paper. Thirdly, we developed a ranking of research papers based on the M-index. We also try to explain how the M-index impacts the ranking of scientific papers.
Sentiment Identification in Code-Mixed Social Media Text
Jul 04, 2017
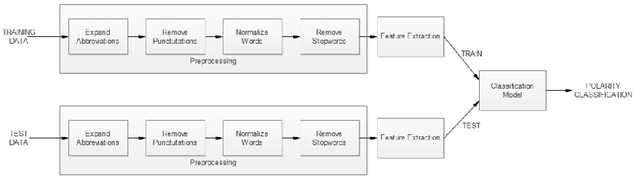
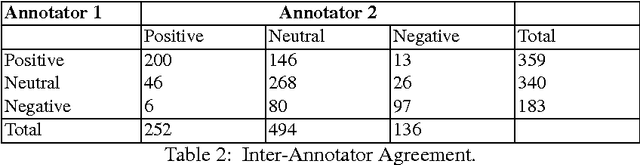
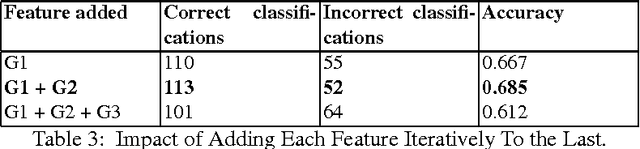
Sentiment analysis is the Natural Language Processing (NLP) task dealing with the detection and classification of sentiments in texts. While some tasks deal with identifying the presence of sentiment in the text (Subjectivity analysis), other tasks aim at determining the polarity of the text categorizing them as positive, negative and neutral. Whenever there is a presence of sentiment in the text, it has a source (people, group of people or any entity) and the sentiment is directed towards some entity, object, event or person. Sentiment analysis tasks aim to determine the subject, the target and the polarity or valence of the sentiment. In our work, we try to automatically extract sentiment (positive or negative) from Facebook posts using a machine learning approach.While some works have been done in code-mixed social media data and in sentiment analysis separately, our work is the first attempt (as of now) which aims at performing sentiment analysis of code-mixed social media text. We have used extensive pre-processing to remove noise from raw text. Multilayer Perceptron model has been used to determine the polarity of the sentiment. We have also developed the corpus for this task by manually labeling Facebook posts with their associated sentiments.
Complexity Metric for Code-Mixed Social Media Text
Jul 04, 2017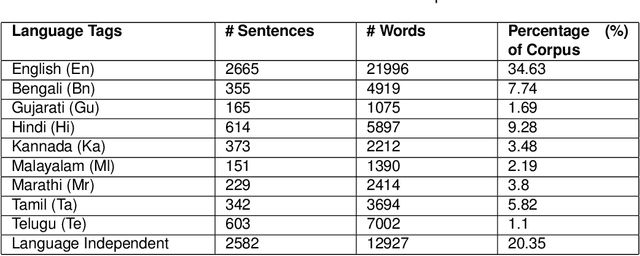
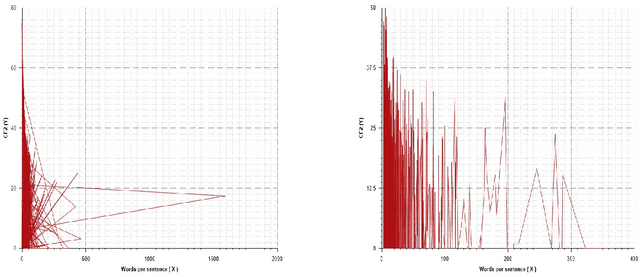

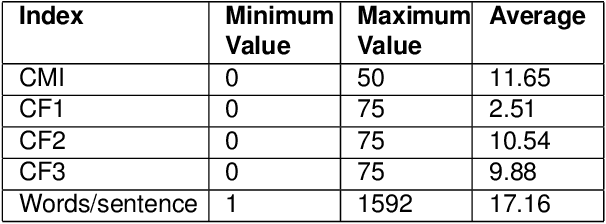
An evaluation metric is an absolute necessity for measuring the performance of any system and complexity of any data. In this paper, we have discussed how to determine the level of complexity of code-mixed social media texts that are growing rapidly due to multilingual interference. In general, texts written in multiple languages are often hard to comprehend and analyze. At the same time, in order to meet the demands of analysis, it is also necessary to determine the complexity of a particular document or a text segment. Thus, in the present paper, we have discussed the existing metrics for determining the code-mixing complexity of a corpus, their advantages, and shortcomings as well as proposed several improvements on the existing metrics. The new index better reflects the variety and complexity of a multilingual document. Also, the index can be applied to a sentence and seamlessly extended to a paragraph or an entire document. We have employed two existing code-mixed corpora to suit the requirements of our study.
Authorship Verification - An Approach based on Random Forest
Jul 29, 2016
Authorship attribution, being an important problem in many areas in-cluding information retrieval, computational linguistics, law and journalism etc., has been identified as a subject of increasingly research interest in the re-cent years. In case of Author Identification task in PAN at CLEF 2015, the main focus was given on cross-genre and cross-topic author verification tasks. We have used several word-based and style-based features to identify the dif-ferences between the known and unknown problems of one given set and label the unknown ones accordingly using a Random Forest based classifier.
Labeling of Query Words using Conditional Random Field
Jul 29, 2016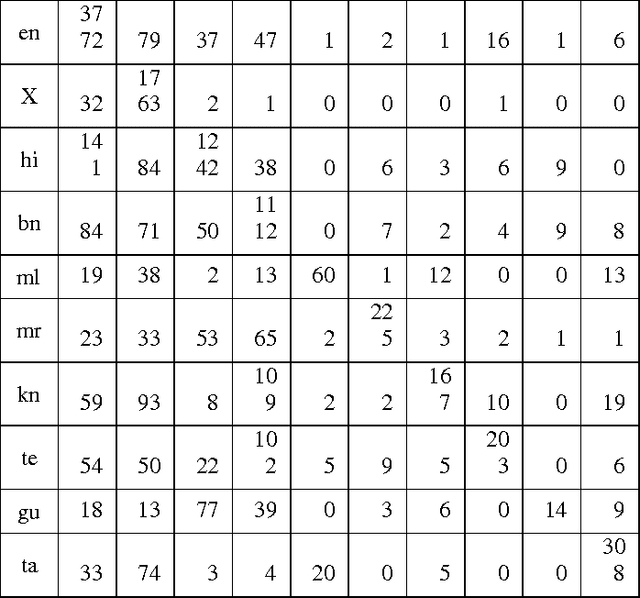
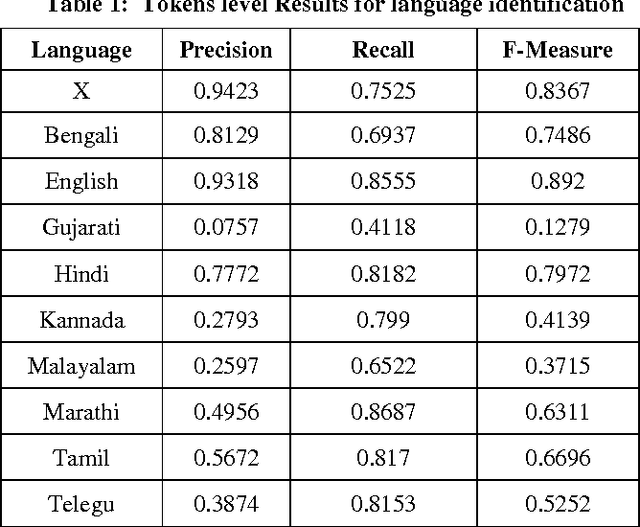

This paper describes our approach on Query Word Labeling as an attempt in the shared task on Mixed Script Information Retrieval at Forum for Information Retrieval Evaluation (FIRE) 2015. The query is written in Roman script and the words were in English or transliterated from Indian regional languages. A total of eight Indian languages were present in addition to English. We also identified the Named Entities and special symbols as part of our task. A CRF based machine learning framework was used for labeling the individual words with their corresponding language labels. We used a dictionary based approach for language identification. We also took into account the context of the word while identifying the language. Our system demonstrated an overall accuracy of 75.5% for token level language identification. The strict F-measure scores for the identification of token level language labels for Bengali, English and Hindi are 0.7486, 0.892 and 0.7972 respectively. The overall weighted F-measure of our system was 0.7498.