 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabeling of Query Words using Conditional Random Field
Paper and Code
Jul 29, 2016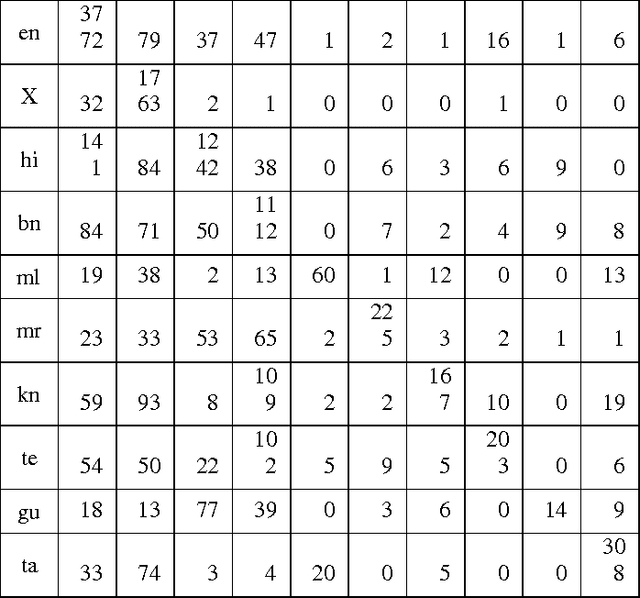
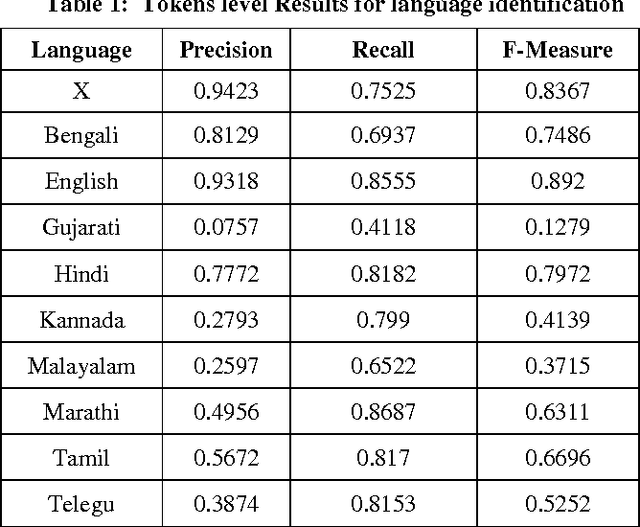

This paper describes our approach on Query Word Labeling as an attempt in the shared task on Mixed Script Information Retrieval at Forum for Information Retrieval Evaluation (FIRE) 2015. The query is written in Roman script and the words were in English or transliterated from Indian regional languages. A total of eight Indian languages were present in addition to English. We also identified the Named Entities and special symbols as part of our task. A CRF based machine learning framework was used for labeling the individual words with their corresponding language labels. We used a dictionary based approach for language identification. We also took into account the context of the word while identifying the language. Our system demonstrated an overall accuracy of 75.5% for token level language identification. The strict F-measure scores for the identification of token level language labels for Bengali, English and Hindi are 0.7486, 0.892 and 0.7972 respectively. The overall weighted F-measure of our system was 0.7498.