 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Ignore Adversarial Attacks
Paper and Code
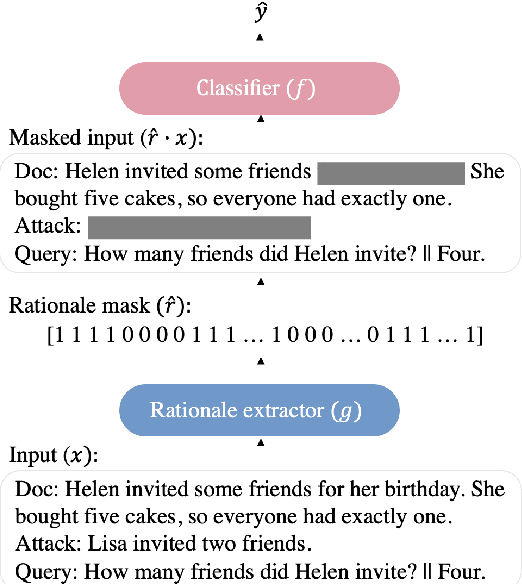
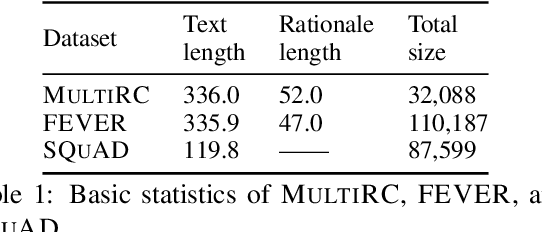

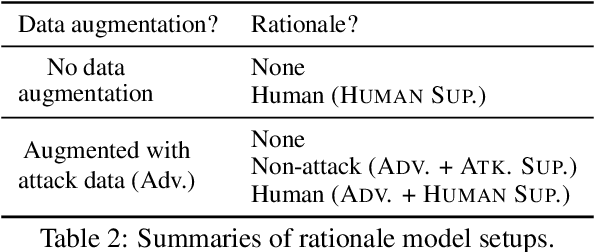
Despite the strong performance of current NLP models, they can be brittle against adversarial attacks. To enable effective learning against adversarial inputs, we introduce the use of rationale models that can explicitly learn to ignore attack tokens. We find that the rationale models can successfully ignore over 90\% of attack tokens. This approach leads to consistent sizable improvements ($\sim$10\%) over baseline models in robustness on three datasets for both BERT and RoBERTa, and also reliably outperforms data augmentation with adversarial examples alone. In many cases, we find that our method is able to close the gap between model performance on a clean test set and an attacked test set and hence reduce the effect of adversarial attacks.