Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProblems With Evaluation of Word Embeddings Using Word Similarity Tasks
Paper and Code
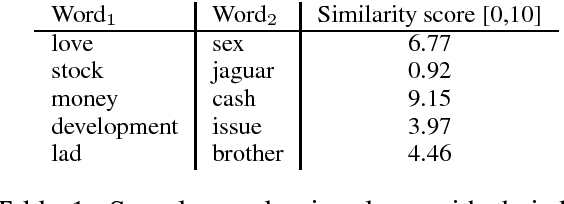
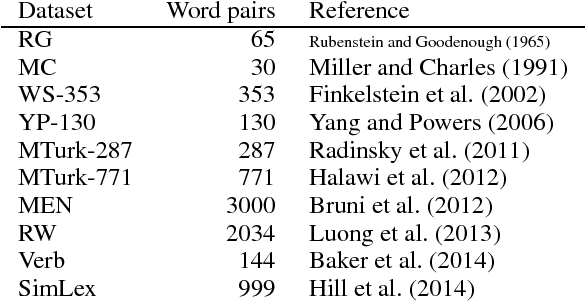
Lacking standardized extrinsic evaluation methods for vector representations of words, the NLP community has relied heavily on word similarity tasks as a proxy for intrinsic evaluation of word vectors. Word similarity evaluation, which correlates the distance between vectors and human judgments of semantic similarity is attractive, because it is computationally inexpensive and fast. In this paper we present several problems associated with the evaluation of word vectors on word similarity datasets, and summarize existing solutions. Our study suggests that the use of word similarity tasks for evaluation of word vectors is not sustainable and calls for further research on evaluation methods.
* The First Workshop on Evaluating Vector Space Representations for NLP
View paper on