 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-Guided Generation of Structured Chest X-Ray Report Using a Pre-trained LLM
Apr 17, 2024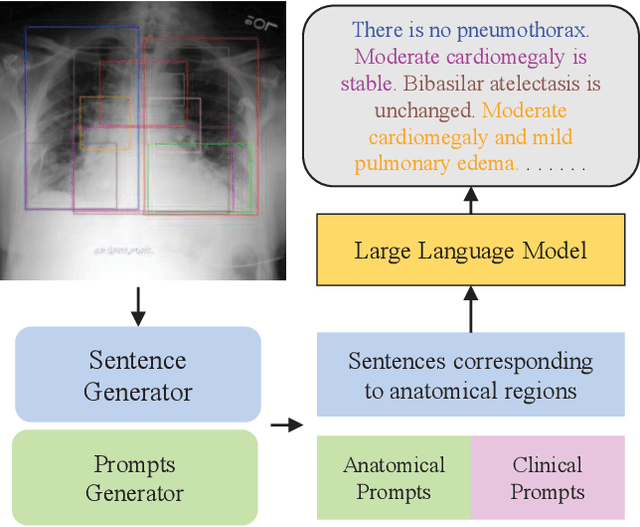
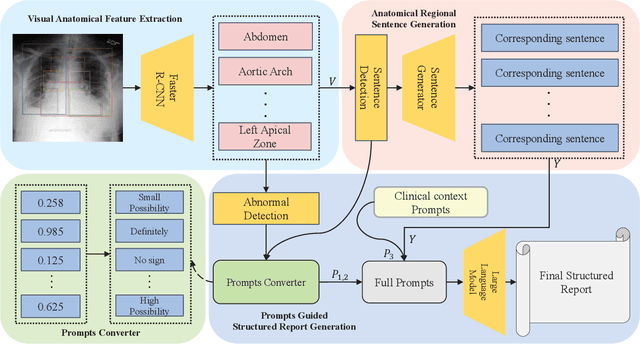
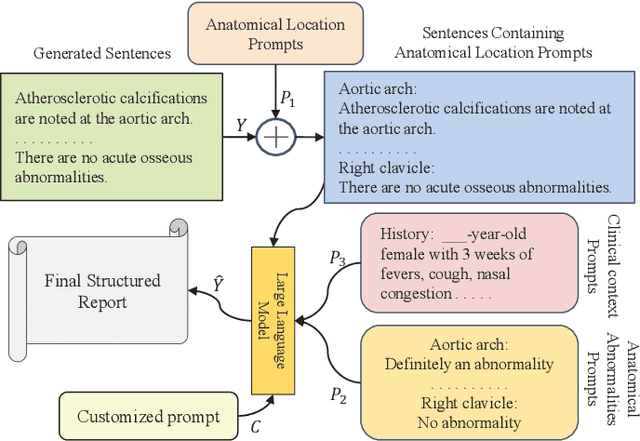

Medical report generation automates radiology descriptions from images, easing the burden on physicians and minimizing errors. However, current methods lack structured outputs and physician interactivity for clear, clinically relevant reports. Our method introduces a prompt-guided approach to generate structured chest X-ray reports using a pre-trained large language model (LLM). First, we identify anatomical regions in chest X-rays to generate focused sentences that center on key visual elements, thereby establishing a structured report foundation with anatomy-based sentences. We also convert the detected anatomy into textual prompts conveying anatomical comprehension to the LLM. Additionally, the clinical context prompts guide the LLM to emphasize interactivity and clinical requirements. By integrating anatomy-focused sentences and anatomy/clinical prompts, the pre-trained LLM can generate structured chest X-ray reports tailored to prompted anatomical regions and clinical contexts. We evaluate using language generation and clinical effectiveness metrics, demonstrating strong performance.
A systematic evaluation of methods for cell phenotype classification using single-cell RNA sequencing data
Oct 01, 2021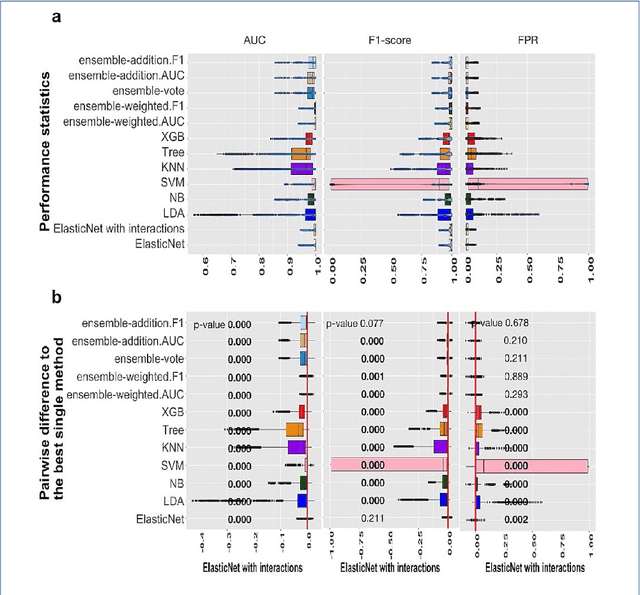
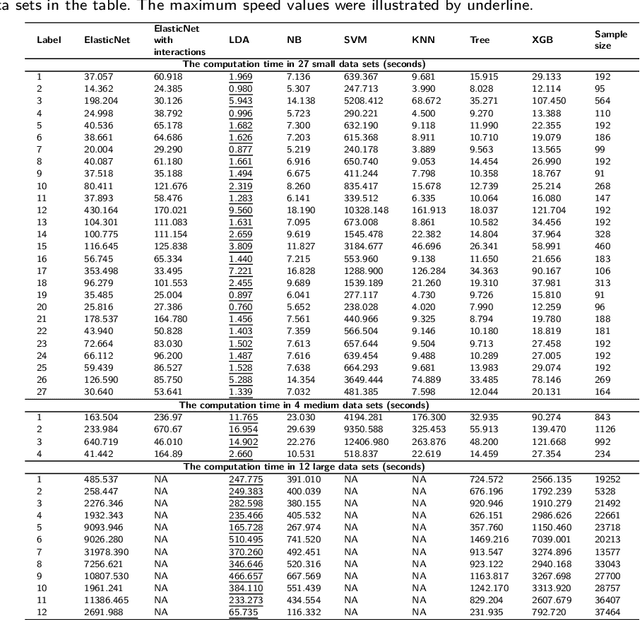
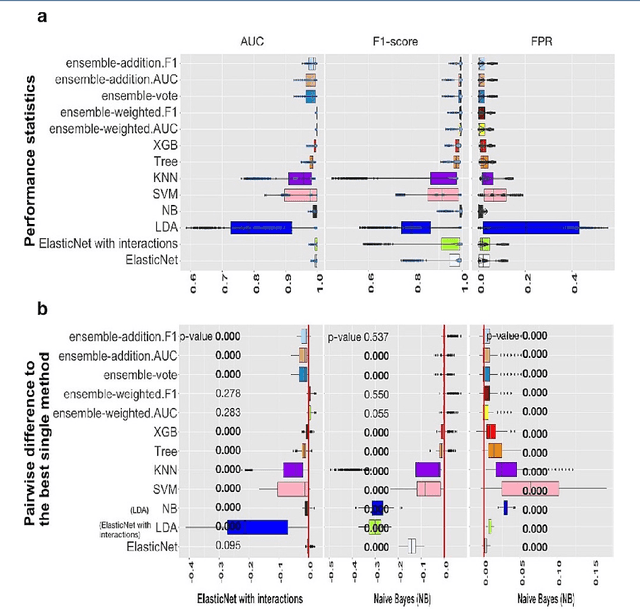
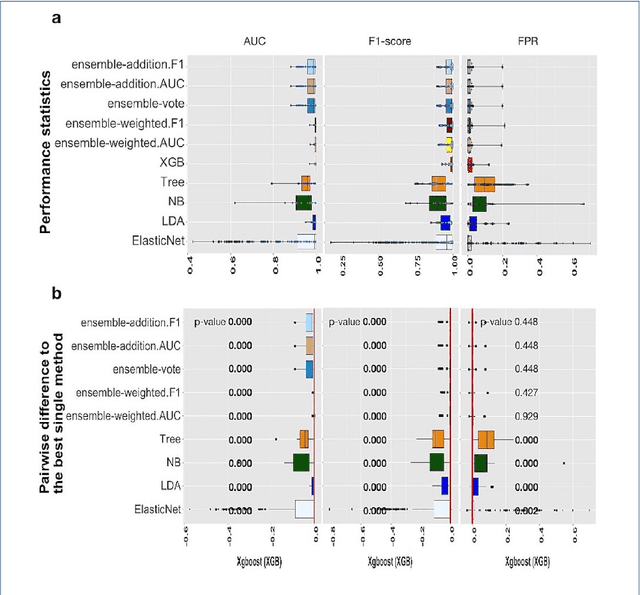
Background: Single-cell RNA sequencing (scRNA-seq) yields valuable insights about gene expression and gives critical information about complex tissue cellular composition. In the analysis of single-cell RNA sequencing, the annotations of cell subtypes are often done manually, which is time-consuming and irreproducible. Garnett is a cell-type annotation software based the on elastic net method. Besides cell-type annotation, supervised machine learning methods can also be applied to predict other cell phenotypes from genomic data. Despite the popularity of such applications, there is no existing study to systematically investigate the performance of those supervised algorithms in various sizes of scRNA-seq data sets. Methods and Results: This study evaluates 13 popular supervised machine learning algorithms to classify cell phenotypes, using published real and simulated data sets with diverse cell sizes. The benchmark contained two parts. In the first part, we used real data sets to assess the popular supervised algorithms' computing speed and cell phenotype classification performance. The classification performances were evaluated using AUC statistics, F1-score, precision, recall, and false-positive rate. In the second part, we evaluated gene selection performance using published simulated data sets with a known list of real genes. Conclusion: The study outcomes showed that ElasticNet with interactions performed best in small and medium data sets. NB was another appropriate method for medium data sets. In large data sets, XGB works excellent. Ensemble algorithms were not significantly superior to individual machine learning methods. Adding interactions to ElasticNet can help, and the improvement was significant in small data sets.
Improving Long Distance Slot Carryover in Spoken Dialogue Systems
Jun 04, 2019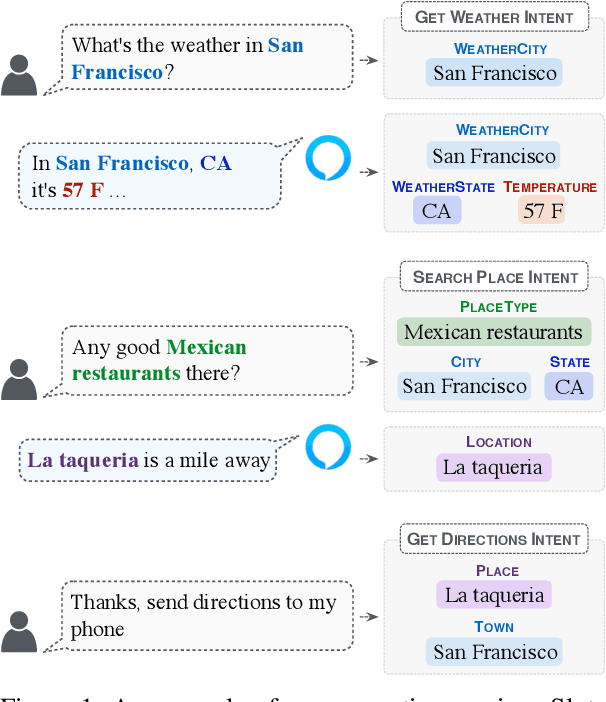
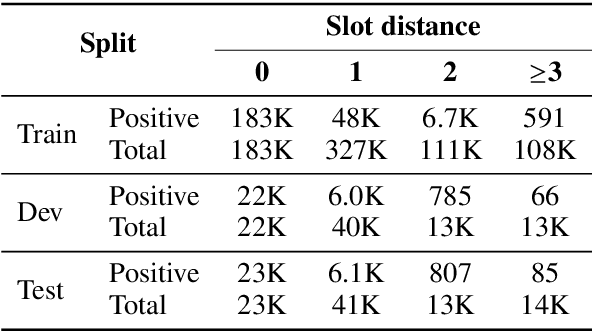

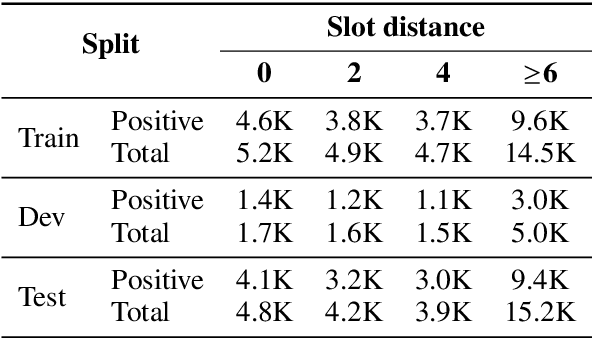
Tracking the state of the conversation is a central component in task-oriented spoken dialogue systems. One such approach for tracking the dialogue state is slot carryover, where a model makes a binary decision if a slot from the context is relevant to the current turn. Previous work on the slot carryover task used models that made independent decisions for each slot. A close analysis of the results show that this approach results in poor performance over longer context dialogues. In this paper, we propose to jointly model the slots. We propose two neural network architectures, one based on pointer networks that incorporate slot ordering information, and the other based on transformer networks that uses self attention mechanism to model the slot interdependencies. Our experiments on an internal dialogue benchmark dataset and on the public DSTC2 dataset demonstrate that our proposed models are able to resolve longer distance slot references and are able to achieve competitive performance.
Network Deconvolution
May 28, 2019
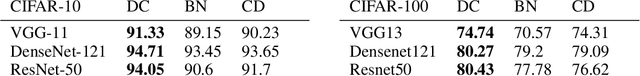
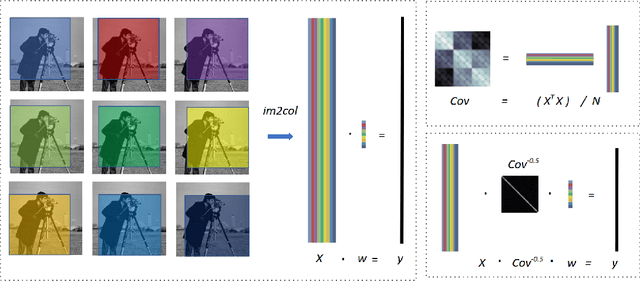

Convolution is a central operation in Convolutional Neural Networks (CNNs), which applies a kernel or mask to overlapping regions shifted across the image. In this work we show that the underlying kernels are trained with highly correlated data, which leads to co-adaptation of model weights. To address this issue we propose what we call network deconvolution, a procedure that aims to remove pixel-wise and channel-wise correlations before the data is fed into each layer. We show that by removing this correlation we are able to achieve better convergence rates during model training with superior results without the use of batch normalization on the CIFAR-10, CIFAR-100, MNIST, Fashion-MNIST datasets, as well as against reference models from "model zoo" on the ImageNet standard benchmark.
A Continuously Growing Dataset of Sentential Paraphrases
Aug 01, 2017
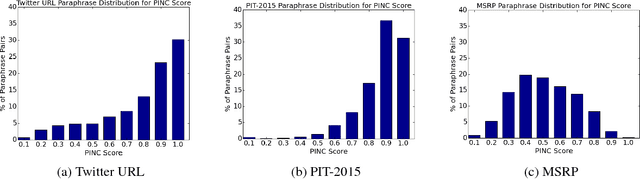
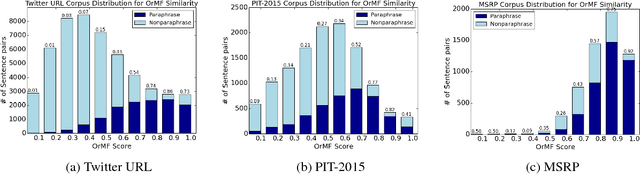

A major challenge in paraphrase research is the lack of parallel corpora. In this paper, we present a new method to collect large-scale sentential paraphrases from Twitter by linking tweets through shared URLs. The main advantage of our method is its simplicity, as it gets rid of the classifier or human in the loop needed to select data before annotation and subsequent application of paraphrase identification algorithms in the previous work. We present the largest human-labeled paraphrase corpus to date of 51,524 sentence pairs and the first cross-domain benchmarking for automatic paraphrase identification. In addition, we show that more than 30,000 new sentential paraphrases can be easily and continuously captured every month at ~70% precision, and demonstrate their utility for downstream NLP tasks through phrasal paraphrase extraction. We make our code and data freely available.
Integrating Lexical and Temporal Signals in Neural Ranking Models for Searching Social Media Streams
Jul 25, 2017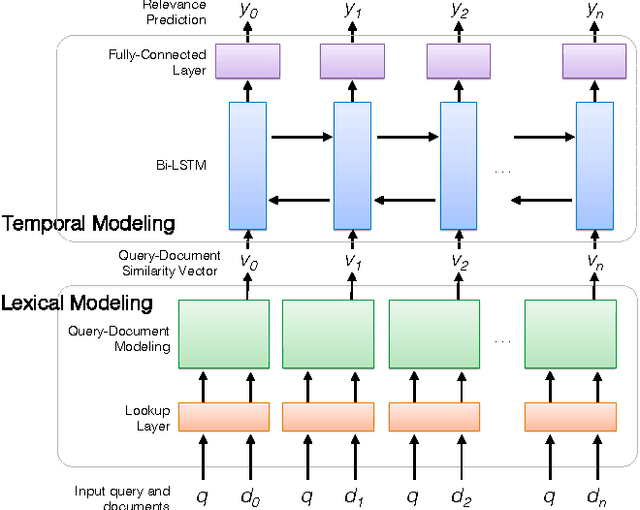
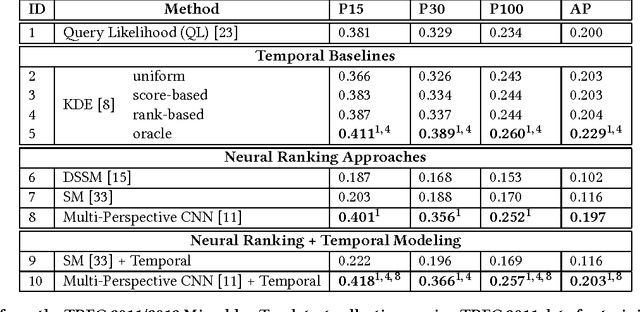
Time is an important relevance signal when searching streams of social media posts. The distribution of document timestamps from the results of an initial query can be leveraged to infer the distribution of relevant documents, which can then be used to rerank the initial results. Previous experiments have shown that kernel density estimation is a simple yet effective implementation of this idea. This paper explores an alternative approach to mining temporal signals with recurrent neural networks. Our intuition is that neural networks provide a more expressive framework to capture the temporal coherence of neighboring documents in time. To our knowledge, we are the first to integrate lexical and temporal signals in an end-to-end neural network architecture, in which existing neural ranking models are used to generate query-document similarity vectors that feed into a bidirectional LSTM layer for temporal modeling. Our results are mixed: existing neural models for document ranking alone yield limited improvements over simple baselines, but the integration of lexical and temporal signals yield significant improvements over competitive temporal baselines.