 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-Guided Generation of Structured Chest X-Ray Report Using a Pre-trained LLM
Apr 17, 2024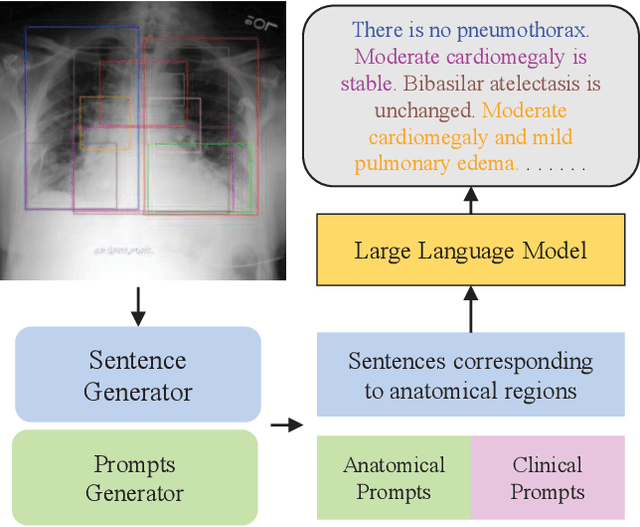
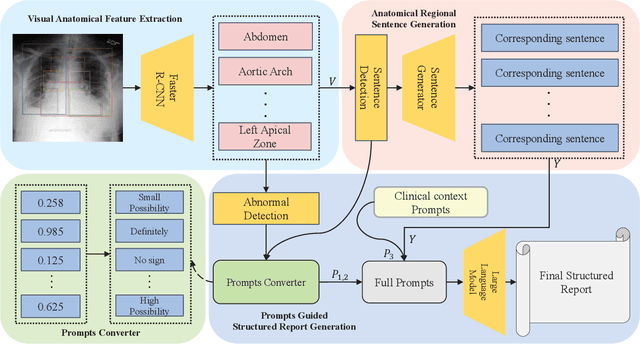
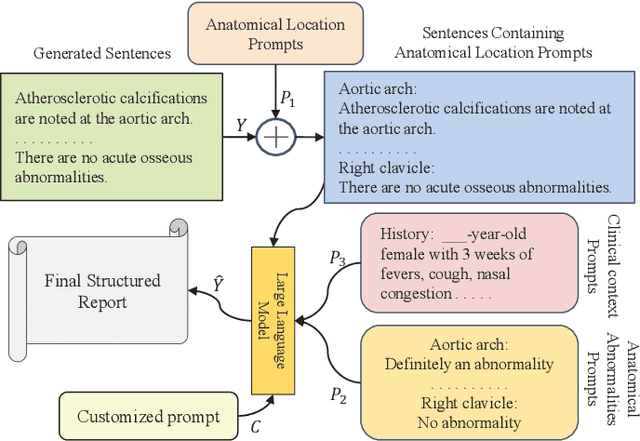

Medical report generation automates radiology descriptions from images, easing the burden on physicians and minimizing errors. However, current methods lack structured outputs and physician interactivity for clear, clinically relevant reports. Our method introduces a prompt-guided approach to generate structured chest X-ray reports using a pre-trained large language model (LLM). First, we identify anatomical regions in chest X-rays to generate focused sentences that center on key visual elements, thereby establishing a structured report foundation with anatomy-based sentences. We also convert the detected anatomy into textual prompts conveying anatomical comprehension to the LLM. Additionally, the clinical context prompts guide the LLM to emphasize interactivity and clinical requirements. By integrating anatomy-focused sentences and anatomy/clinical prompts, the pre-trained LLM can generate structured chest X-ray reports tailored to prompted anatomical regions and clinical contexts. We evaluate using language generation and clinical effectiveness metrics, demonstrating strong performance.
Prompting Explicit and Implicit Knowledge for Multi-hop Question Answering Based on Human Reading Process
Mar 04, 2024Pre-trained language models (PLMs) leverage chains-of-thought (CoT) to simulate human reasoning and inference processes, achieving proficient performance in multi-hop QA. However, a gap persists between PLMs' reasoning abilities and those of humans when tackling complex problems. Psychological studies suggest a vital connection between explicit information in passages and human prior knowledge during reading. Nevertheless, current research has given insufficient attention to linking input passages and PLMs' pre-training-based knowledge from the perspective of human cognition studies. In this study, we introduce a Prompting Explicit and Implicit knowledge (PEI) framework, which uses prompts to connect explicit and implicit knowledge, aligning with human reading process for multi-hop QA. We consider the input passages as explicit knowledge, employing them to elicit implicit knowledge through unified prompt reasoning. Furthermore, our model incorporates type-specific reasoning via prompts, a form of implicit knowledge. Experimental results show that PEI performs comparably to the state-of-the-art on HotpotQA. Ablation studies confirm the efficacy of our model in bridging and integrating explicit and implicit knowledge.
A Deep CNN Architecture with Novel Pooling Layer Applied to Two Sudanese Arabic Sentiment Datasets
Jan 29, 2022Arabic sentiment analysis has become an important research field in recent years. Initially, work focused on Modern Standard Arabic (MSA), which is the most widely-used form. Since then, work has been carried out on several different dialects, including Egyptian, Levantine and Moroccan. Moreover, a number of datasets have been created to support such work. However, up until now, less work has been carried out on Sudanese Arabic, a dialect which has 32 million speakers. In this paper, two new publicly available datasets are introduced, the 2-Class Sudanese Sentiment Dataset (SudSenti2) and the 3-Class Sudanese Sentiment Dataset (SudSenti3). Furthermore, a CNN architecture, SCM, is proposed, comprising five CNN layers together with a novel pooling layer, MMA, to extract the best features. This SCM+MMA model is applied to SudSenti2 and SudSenti3 with accuracies of 92.75% and 84.39%. Next, the model is compared to other deep learning classifiers and shown to be superior on these new datasets. Finally, the proposed model is applied to the existing Saudi Sentiment Dataset and to the MSA Hotel Arabic Review Dataset with accuracies 85.55% and 90.01%.
Viewpoint-aware Progressive Clustering for Unsupervised Vehicle Re-identification
Nov 18, 2020

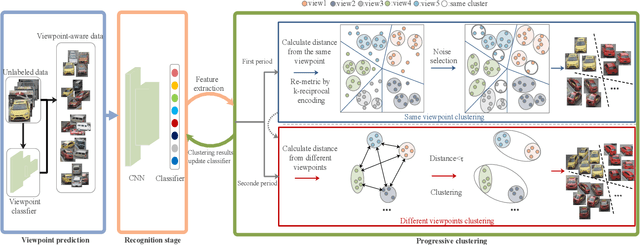
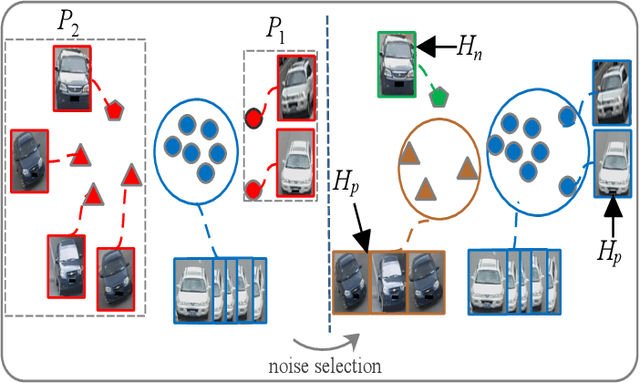
Vehicle re-identification (Re-ID) is an active task due to its importance in large-scale intelligent monitoring in smart cities. Despite the rapid progress in recent years, most existing methods handle vehicle Re-ID task in a supervised manner, which is both time and labor-consuming and limits their application to real-life scenarios. Recently, unsupervised person Re-ID methods achieve impressive performance by exploring domain adaption or clustering-based techniques. However, one cannot directly generalize these methods to vehicle Re-ID since vehicle images present huge appearance variations in different viewpoints. To handle this problem, we propose a novel viewpoint-aware clustering algorithm for unsupervised vehicle Re-ID. In particular, we first divide the entire feature space into different subspaces according to the predicted viewpoints and then perform a progressive clustering to mine the accurate relationship among samples. Comprehensive experiments against the state-of-the-art methods on two multi-viewpoint benchmark datasets VeRi and VeRi-Wild validate the promising performance of the proposed method in both with and without domain adaption scenarios while handling unsupervised vehicle Re-ID.