 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYMIR: A new Benchmark Dataset and Model for Arabic Yemeni Music Genre Classification Using Convolutional Neural Networks
Apr 06, 2026Automatic music genre classification is a major task in music information retrieval; however, most current benchmarks and models have been developed primarily for Western music, leaving culturally specific traditions underrepresented. In this paper, we introduce the Yemeni Music Information Retrieval (YMIR) dataset, which contains 1,475 carefully selected audio clips covering five traditional Yemeni genres: Sanaani, Hadhrami, Lahji, Tihami, and Adeni. The dataset was labeled by five Yemeni music experts following a clear and structured protocol, resulting in strong inter-annotator agreement (Fleiss kappa = 0.85). We also propose the Yemeni Music Classification Model (YMCM), a convolutional neural network (CNN)-based system designed to classify music genres from time-frequency features. Using a consistent preprocessing pipeline, we perform a systematic comparison across six experimental groups and five different architectures, resulting in a total of 30 experiments. Specifically, we evaluate several feature representations, including Mel-spectrograms, Chroma, FilterBank, and MFCCs with 13, 20, and 40 coefficients, and benchmark YMCM against standard models (AlexNet, VGG16, MobileNet, and a baseline CNN) under the same experimental conditions. The experimental findings reveal that YMCM is the most effective, achieving the highest accuracy of 98.8% with Mel-spectrogram features. The results also provide practical insights into the relationship between feature representation and model capacity. The findings establish YMIR as a useful benchmark and YMCM as a strong baseline for classifying Yemeni music genres.
Cross-Corpus Multilingual Speech Emotion Recognition: Amharic vs. Other Languages
Jul 20, 2023In a conventional Speech emotion recognition (SER) task, a classifier for a given language is trained on a pre-existing dataset for that same language. However, where training data for a language does not exist, data from other languages can be used instead. We experiment with cross-lingual and multilingual SER, working with Amharic, English, German and URDU. For Amharic, we use our own publicly-available Amharic Speech Emotion Dataset (ASED). For English, German and Urdu we use the existing RAVDESS, EMO-DB and URDU datasets. We followed previous research in mapping labels for all datasets to just two classes, positive and negative. Thus we can compare performance on different languages directly, and combine languages for training and testing. In Experiment 1, monolingual SER trials were carried out using three classifiers, AlexNet, VGGE (a proposed variant of VGG), and ResNet50. Results averaged for the three models were very similar for ASED and RAVDESS, suggesting that Amharic and English SER are equally difficult. Similarly, German SER is more difficult, and Urdu SER is easier. In Experiment 2, we trained on one language and tested on another, in both directions for each pair: Amharic<->German, Amharic<->English, and Amharic<->Urdu. Results with Amharic as target suggested that using English or German as source will give the best result. In Experiment 3, we trained on several non-Amharic languages and then tested on Amharic. The best accuracy obtained was several percent greater than the best accuracy in Experiment 2, suggesting that a better result can be obtained when using two or three non-Amharic languages for training than when using just one non-Amharic language. Overall, the results suggest that cross-lingual and multilingual training can be an effective strategy for training a SER classifier when resources for a language are scarce.
A Deep CNN Architecture with Novel Pooling Layer Applied to Two Sudanese Arabic Sentiment Datasets
Jan 29, 2022Arabic sentiment analysis has become an important research field in recent years. Initially, work focused on Modern Standard Arabic (MSA), which is the most widely-used form. Since then, work has been carried out on several different dialects, including Egyptian, Levantine and Moroccan. Moreover, a number of datasets have been created to support such work. However, up until now, less work has been carried out on Sudanese Arabic, a dialect which has 32 million speakers. In this paper, two new publicly available datasets are introduced, the 2-Class Sudanese Sentiment Dataset (SudSenti2) and the 3-Class Sudanese Sentiment Dataset (SudSenti3). Furthermore, a CNN architecture, SCM, is proposed, comprising five CNN layers together with a novel pooling layer, MMA, to extract the best features. This SCM+MMA model is applied to SudSenti2 and SudSenti3 with accuracies of 92.75% and 84.39%. Next, the model is compared to other deep learning classifiers and shown to be superior on these new datasets. Finally, the proposed model is applied to the existing Saudi Sentiment Dataset and to the MSA Hotel Arabic Review Dataset with accuracies 85.55% and 90.01%.
Kinit Classification in Ethiopian Chants, Azmaris and Modern Music: A New Dataset and CNN Benchmark
Jan 20, 2022



In this paper, we create EMIR, the first-ever Music Information Retrieval dataset for Ethiopian music. EMIR is freely available for research purposes and contains 600 sample recordings of Orthodox Tewahedo chants, traditional Azmari songs and contemporary Ethiopian secular music. Each sample is classified by five expert judges into one of four well-known Ethiopian Kinits, Tizita, Bati, Ambassel and Anchihoye. Each Kinit uses its own pentatonic scale and also has its own stylistic characteristics. Thus, Kinit classification needs to combine scale identification with genre recognition. After describing the dataset, we present the Ethio Kinits Model (EKM), based on VGG, for classifying the EMIR clips. In Experiment 1, we investigated whether Filterbank, Mel-spectrogram, Chroma, or Mel-frequency Cepstral coefficient (MFCC) features work best for Kinit classification using EKM. MFCC was found to be superior and was therefore adopted for Experiment 2, where the performance of EKM models using MFCC was compared using three different audio sample lengths. 3s length gave the best results. In Experiment 3, EKM and four existing models were compared on the EMIR dataset: AlexNet, ResNet50, VGG16 and LSTM. EKM was found to have the best accuracy (95.00%) as well as the fastest training time. We hope this work will encourage others to explore Ethiopian music and to experiment with other models for Kinit classification.
A New Amharic Speech Emotion Dataset and Classification Benchmark
Jan 07, 2022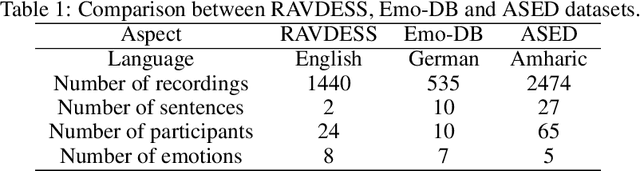
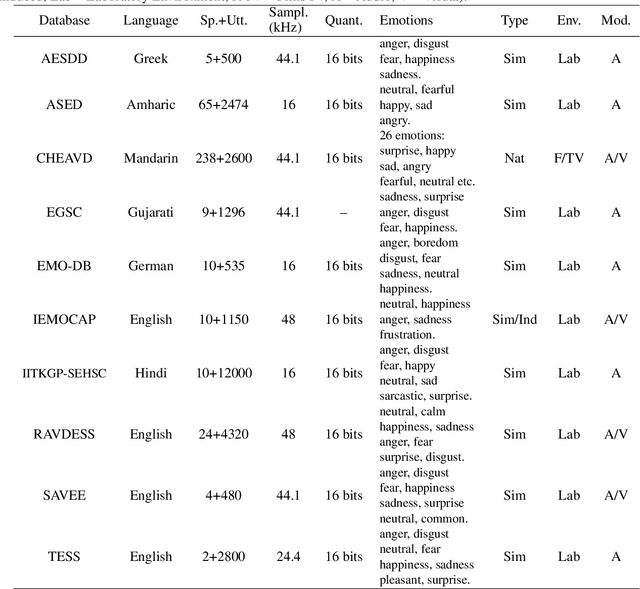


In this paper we present the Amharic Speech Emotion Dataset (ASED), which covers four dialects (Gojjam, Wollo, Shewa and Gonder) and five different emotions (neutral, fearful, happy, sad and angry). We believe it is the first Speech Emotion Recognition (SER) dataset for the Amharic language. 65 volunteer participants, all native speakers, recorded 2,474 sound samples, two to four seconds in length. Eight judges assigned emotions to the samples with high agreement level (Fleiss kappa = 0.8). The resulting dataset is freely available for download. Next, we developed a four-layer variant of the well-known VGG model which we call VGGb. Three experiments were then carried out using VGGb for SER, using ASED. First, we investigated whether Mel-spectrogram features or Mel-frequency Cepstral coefficient (MFCC) features work best for Amharic. This was done by training two VGGb SER models on ASED, one using Mel-spectrograms and the other using MFCC. Four forms of training were tried, standard cross-validation, and three variants based on sentences, dialects and speaker groups. Thus, a sentence used for training would not be used for testing, and the same for a dialect and speaker group. The conclusion was that MFCC features are superior under all four training schemes. MFCC was therefore adopted for Experiment 2, where VGGb and three other existing models were compared on ASED: RESNet50, Alex-Net and LSTM. VGGb was found to have very good accuracy (90.73%) as well as the fastest training time. In Experiment 3, the performance of VGGb was compared when trained on two existing SER datasets, RAVDESS (English) and EMO-DB (German) as well as on ASED (Amharic). Results are comparable across these languages, with ASED being the highest. This suggests that VGGb can be successfully applied to other languages. We hope that ASED will encourage researchers to experiment with other models for Amharic SER.