 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards LLM-based Root Cause Analysis of Hardware Design Failures
Jul 09, 2025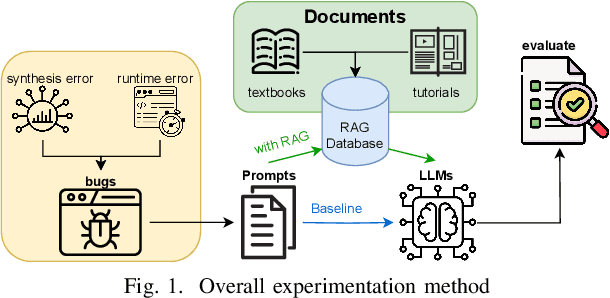


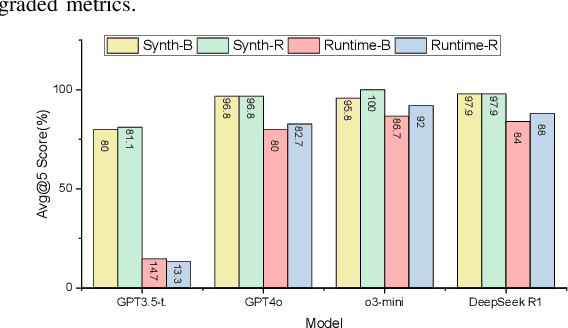
With advances in large language models (LLMs), new opportunities have emerged to develop tools that support the digital hardware design process. In this work, we explore how LLMs can assist with explaining the root cause of design issues and bugs that are revealed during synthesis and simulation, a necessary milestone on the pathway towards widespread use of LLMs in the hardware design process and for hardware security analysis. We find promising results: for our corpus of 34 different buggy scenarios, OpenAI's o3-mini reasoning model reached a correct determination 100% of the time under pass@5 scoring, with other state of the art models and configurations usually achieving more than 80% performance and more than 90% when assisted with retrieval-augmented generation.
Explaining EDA synthesis errors with LLMs
Apr 07, 2024
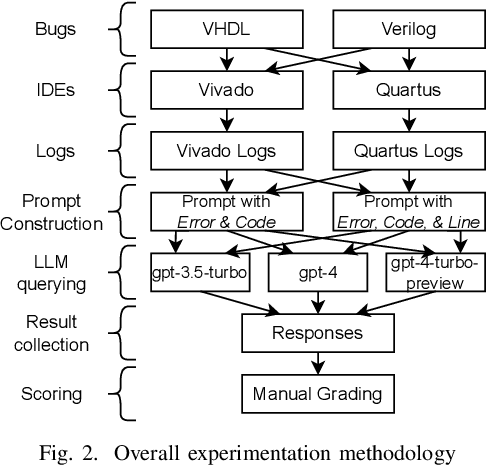


Training new engineers in digital design is a challenge, particularly when it comes to teaching the complex electronic design automation (EDA) tooling used in this domain. Learners will typically deploy designs in the Verilog and VHDL hardware description languages to Field Programmable Gate Arrays (FPGAs) from Altera (Intel) and Xilinx (AMD) via proprietary closed-source toolchains (Quartus Prime and Vivado, respectively). These tools are complex and difficult to use -- yet, as they are the tools used in industry, they are an essential first step in this space. In this work, we examine how recent advances in artificial intelligence may be leveraged to address aspects of this challenge. Specifically, we investigate if Large Language Models (LLMs), which have demonstrated text comprehension and question-answering capabilities, can be used to generate novice-friendly explanations of compile-time synthesis error messages from Quartus Prime and Vivado. To perform this study we generate 936 error message explanations using three OpenAI LLMs over 21 different buggy code samples. These are then graded for relevance and correctness, and we find that in approximately 71% of cases the LLMs give correct & complete explanations suitable for novice learners.
A Continuously Growing Dataset of Sentential Paraphrases
Aug 01, 2017
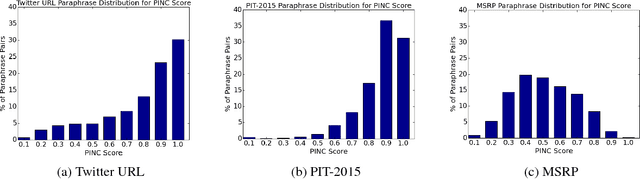
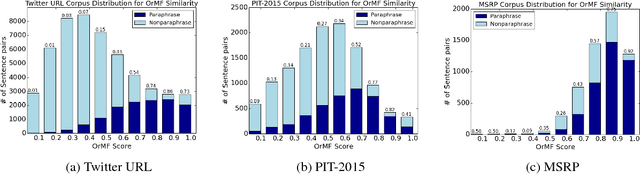

A major challenge in paraphrase research is the lack of parallel corpora. In this paper, we present a new method to collect large-scale sentential paraphrases from Twitter by linking tweets through shared URLs. The main advantage of our method is its simplicity, as it gets rid of the classifier or human in the loop needed to select data before annotation and subsequent application of paraphrase identification algorithms in the previous work. We present the largest human-labeled paraphrase corpus to date of 51,524 sentence pairs and the first cross-domain benchmarking for automatic paraphrase identification. In addition, we show that more than 30,000 new sentential paraphrases can be easily and continuously captured every month at ~70% precision, and demonstrate their utility for downstream NLP tasks through phrasal paraphrase extraction. We make our code and data freely available.
KNET: A General Framework for Learning Word Embedding using Morphological Knowledge
Sep 05, 2014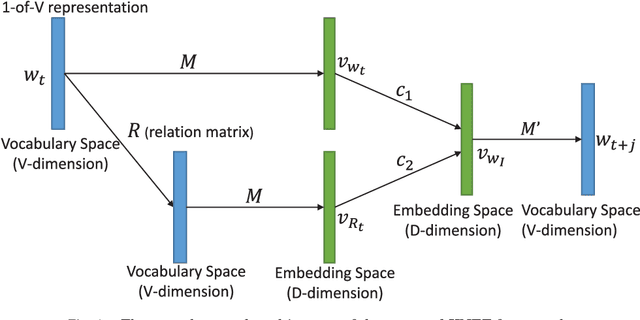
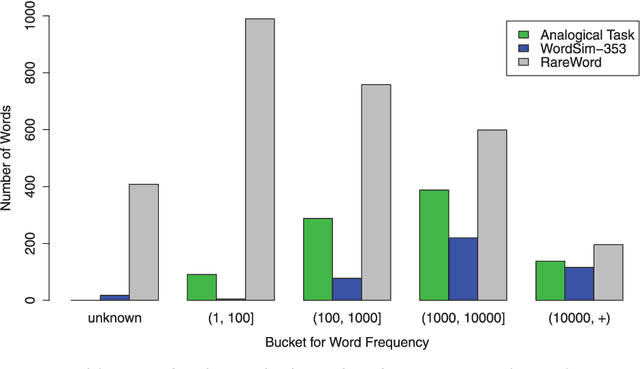

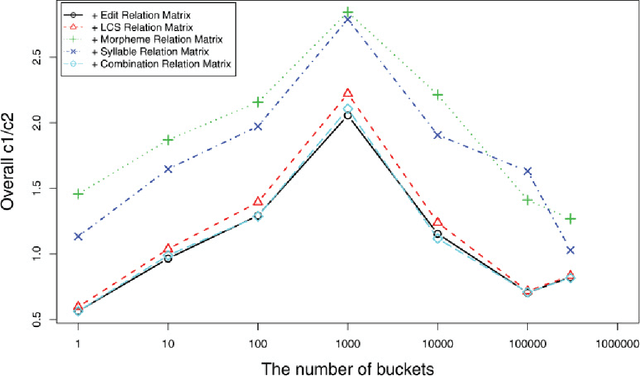
Neural network techniques are widely applied to obtain high-quality distributed representations of words, i.e., word embeddings, to address text mining, information retrieval, and natural language processing tasks. Recently, efficient methods have been proposed to learn word embeddings from context that captures both semantic and syntactic relationships between words. However, it is challenging to handle unseen words or rare words with insufficient context. In this paper, inspired by the study on word recognition process in cognitive psychology, we propose to take advantage of seemingly less obvious but essentially important morphological knowledge to address these challenges. In particular, we introduce a novel neural network architecture called KNET that leverages both contextual information and morphological word similarity built based on morphological knowledge to learn word embeddings. Meanwhile, the learning architecture is also able to refine the pre-defined morphological knowledge and obtain more accurate word similarity. Experiments on an analogical reasoning task and a word similarity task both demonstrate that the proposed KNET framework can greatly enhance the effectiveness of word embeddings.