 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillScope: A Tool to Predict Fine-Grained Skills Needed to Solve Issues on GitHub
Jan 27, 2025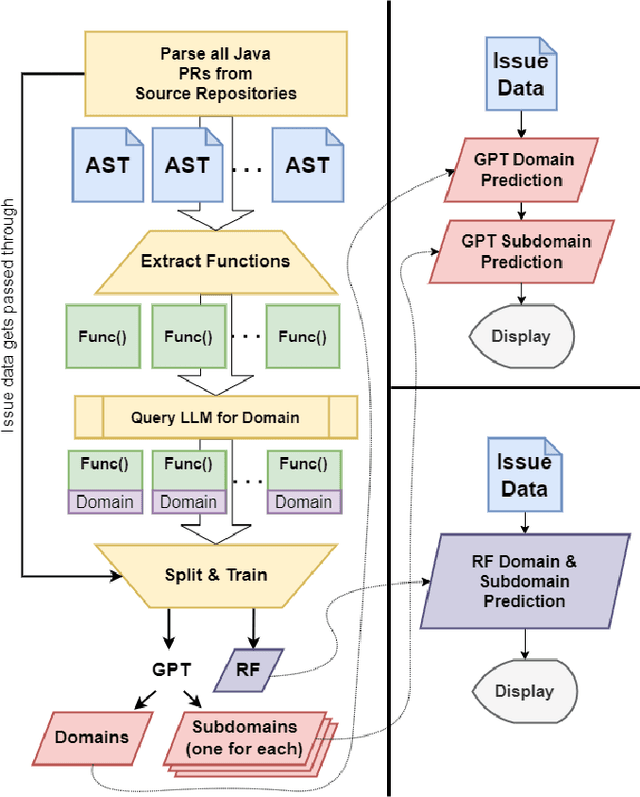
New contributors often struggle to find tasks that they can tackle when onboarding onto a new Open Source Software (OSS) project. One reason for this difficulty is that issue trackers lack explanations about the knowledge or skills needed to complete a given task successfully. These explanations can be complex and time-consuming to produce. Past research has partially addressed this problem by labeling issues with issue types, issue difficulty level, and issue skills. However, current approaches are limited to a small set of labels and lack in-depth details about their semantics, which may not sufficiently help contributors identify suitable issues. To surmount this limitation, this paper explores large language models (LLMs) and Random Forest (RF) to predict the multilevel skills required to solve the open issues. We introduce a novel tool, SkillScope, which retrieves current issues from Java projects hosted on GitHub and predicts the multilevel programming skills required to resolve these issues. In a case study, we demonstrate that SkillScope could predict 217 multilevel skills for tasks with 91% precision, 88% recall, and 89% F-measure on average. Practitioners can use this tool to better delegate or choose tasks to solve in OSS projects.
Applying Large Language Models API to Issue Classification Problem
Jan 09, 2024Effective prioritization of issue reports is crucial in software engineering to optimize resource allocation and address critical problems promptly. However, the manual classification of issue reports for prioritization is laborious and lacks scalability. Alternatively, many open source software (OSS) projects employ automated processes for this task, albeit relying on substantial datasets for adequate training. This research seeks to devise an automated approach that ensures reliability in issue prioritization, even when trained on smaller datasets. Our proposed methodology harnesses the power of Generative Pre-trained Transformers (GPT), recognizing their potential to efficiently handle this task. By leveraging the capabilities of such models, we aim to develop a robust system for prioritizing issue reports accurately, mitigating the necessity for extensive training data while maintaining reliability. In our research, we have developed a reliable GPT-based approach to accurately label and prioritize issue reports with a reduced training dataset. By reducing reliance on massive data requirements and focusing on few-shot fine-tuning, our methodology offers a more accessible and efficient solution for issue prioritization in software engineering. Our model predicted issue types in individual projects up to 93.2% in precision, 95% in recall, and 89.3% in F1-score.
Tag that issue: Applying API-domain labels in issue tracking systems
Apr 06, 2023Labeling issues with the skills required to complete them can help contributors to choose tasks in Open Source Software projects. However, manually labeling issues is time-consuming and error-prone, and current automated approaches are mostly limited to classifying issues as bugs/non-bugs. We investigate the feasibility and relevance of automatically labeling issues with what we call "API-domains," which are high-level categories of APIs. Therefore, we posit that the APIs used in the source code affected by an issue can be a proxy for the type of skills (e.g., DB, security, UI) needed to work on the issue. We ran a user study (n=74) to assess API-domain labels' relevancy to potential contributors, leveraged the issues' descriptions and the project history to build prediction models, and validated the predictions with contributors (n=20) of the projects. Our results show that (i) newcomers to the project consider API-domain labels useful in choosing tasks, (ii) labels can be predicted with a precision of 84% and a recall of 78.6% on average, (iii) the results of the predictions reached up to 71.3% in precision and 52.5% in recall when training with a project and testing in another (transfer learning), and (iv) project contributors consider most of the predictions helpful in identifying needed skills. These findings suggest our approach can be applied in practice to automatically label issues, assisting developers in finding tasks that better match their skills.
GiveMeLabeledIssues: An Open Source Issue Recommendation System
Mar 23, 2023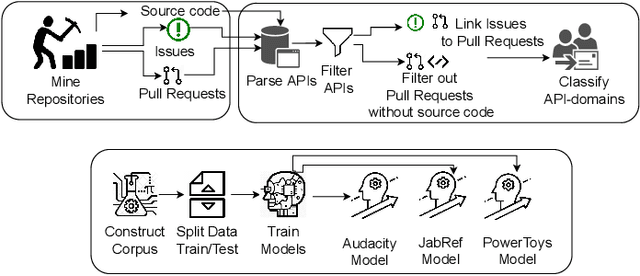


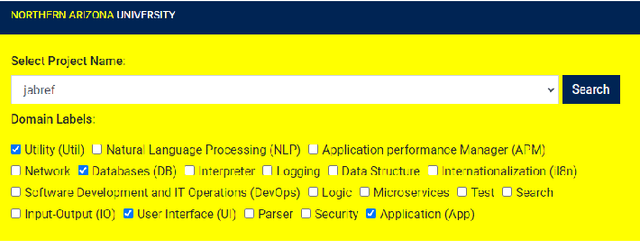
Developers often struggle to navigate an Open Source Software (OSS) project's issue-tracking system and find a suitable task. Proper issue labeling can aid task selection, but current tools are limited to classifying the issues according to their type (e.g., bug, question, good first issue, feature, etc.). In contrast, this paper presents a tool (GiveMeLabeledIssues) that mines project repositories and labels issues based on the skills required to solve them. We leverage the domain of the APIs involved in the solution (e.g., User Interface (UI), Test, Databases (DB), etc.) as a proxy for the required skills. GiveMeLabeledIssues facilitates matching developers' skills to tasks, reducing the burden on project maintainers. The tool obtained a precision of 83.9% when predicting the API domains involved in the issues. The replication package contains instructions on executing the tool and including new projects. A demo video is available at https://www.youtube.com/watch?v=ic2quUue7i8
Supporting the Task-driven Skill Identification in Open Source Project Issue Tracking Systems
Nov 02, 2022



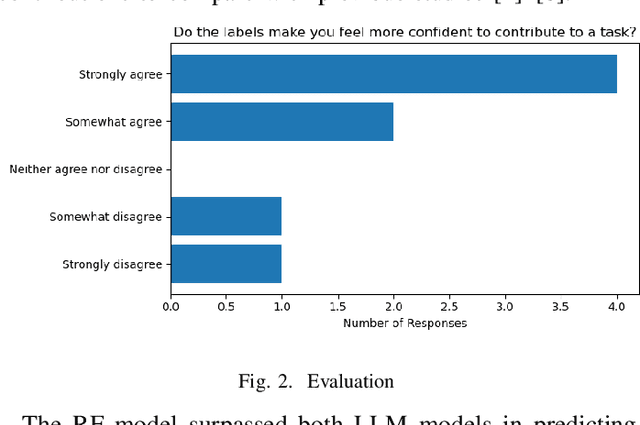
Selecting an appropriate task is challenging for contributors to Open Source Software (OSS), mainly for those who are contributing for the first time. Therefore, researchers and OSS projects have proposed various strategies to aid newcomers, including labeling tasks. We investigate the automatic labeling of open issues strategy to help the contributors to pick a task to contribute. We label the issues with API-domains--categories of APIs parsed from the source code used to solve the issues. We plan to add social network analysis metrics from the issues conversations as new predictors. By identifying the skills, we claim the contributor candidates should pick a task more suitable. We analyzed interview transcripts and the survey's open-ended questions to comprehend the strategies used to assist in onboarding contributors and used to pick up an issue. We applied quantitative studies to analyze the relevance of the labels in an experiment and compare the strategies' relative importance. We also mined issue data from OSS repositories to predict the API-domain labels with comparable precision, recall, and F-measure with the state-of-art. We plan to use a skill ontology to assist the matching process between contributors and tasks. By analyzing the confidence level of the matching instances in ontologies describing contributors' skills and tasks, we might recommend issues for contribution. So far, the results showed that organizing the issues--which includes assigning labels is seen as an essential strategy for diverse roles in OSS communities. The API-domain labels are relevant for experienced practitioners. The predictions have an average precision of 75.5%. Labeling the issues indicates the skills involved in an issue. The labels represent possible skills in the source code related to an issue. By investigating this research topic, we expect to assist the new contributors in finding a task.
Can I Solve It? Identifying APIs Required to Complete OSS Task
Mar 23, 2021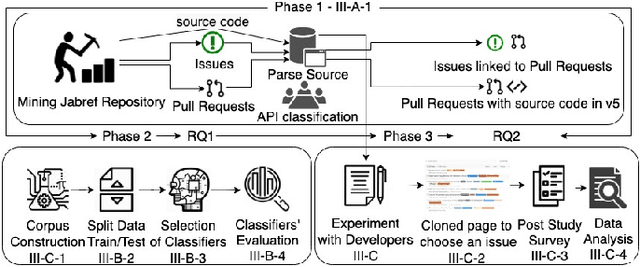
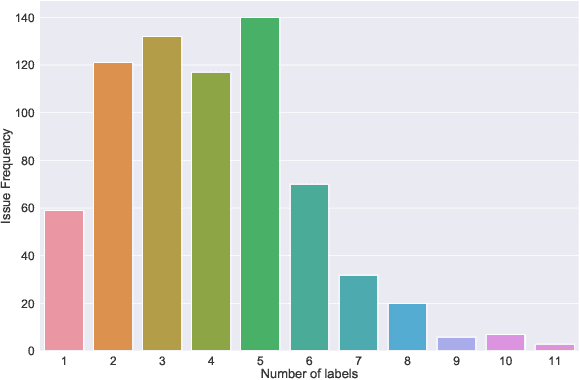
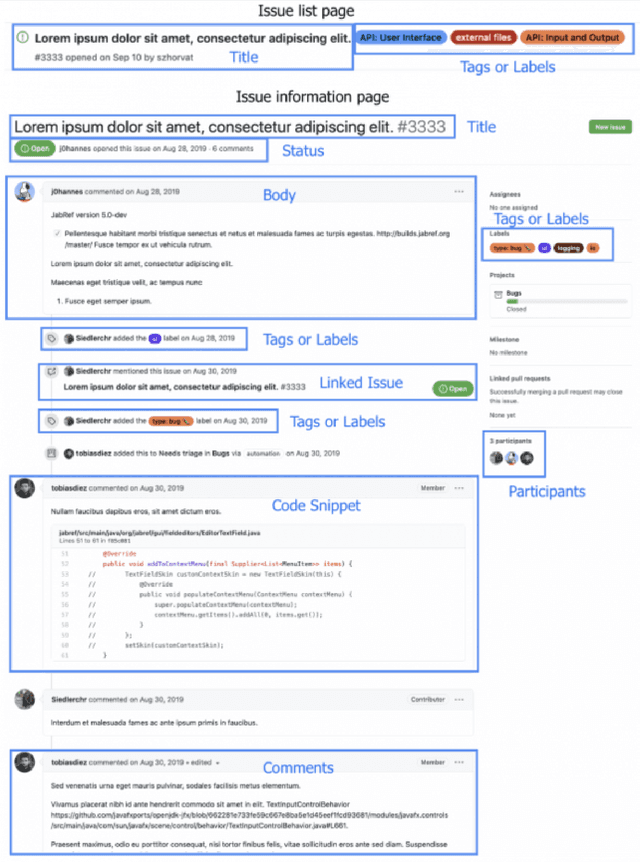
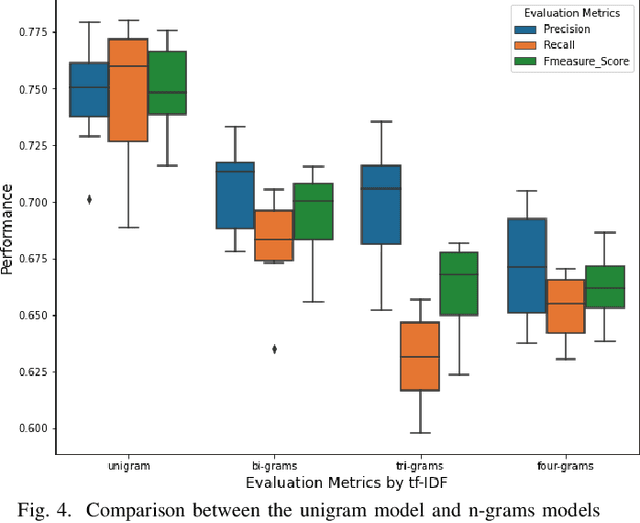
Open Source Software projects add labels to open issues to help contributors choose tasks. However, manually labeling issues is time-consuming and error-prone. Current automatic approaches for creating labels are mostly limited to classifying issues as a bug/non-bug. In this paper, we investigate the feasibility and relevance of labeling issues with the domain of the APIs required to complete the tasks. We leverage the issues' description and the project history to build prediction models, which resulted in precision up to 82% and recall up to 97.8%. We also ran a user study (n=74) to assess these labels' relevancy to potential contributors. The results show that the labels were useful to participants in choosing tasks, and the API-domain labels were selected more often than the existing architecture-based labels. Our results can inspire the creation of tools to automatically label issues, helping developers to find tasks that better match their skills.