 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuning-free coreset Markov chain Monte Carlo
Oct 24, 2024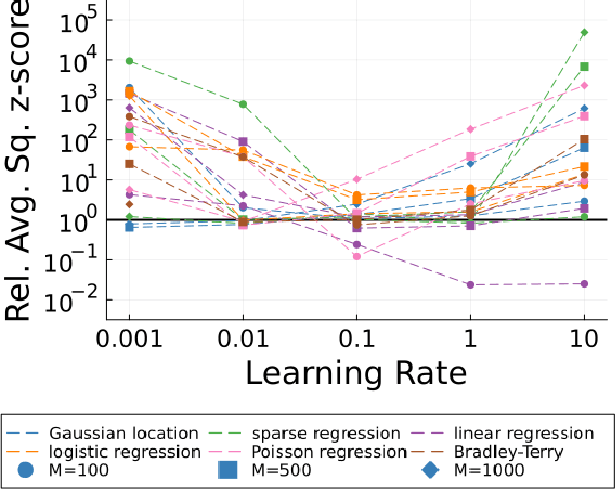
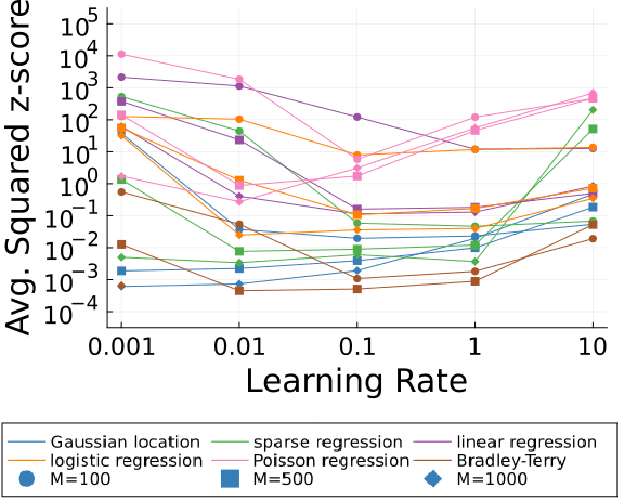


A Bayesian coreset is a small, weighted subset of a data set that replaces the full data during inference to reduce computational cost. The state-of-the-art coreset construction algorithm, Coreset Markov chain Monte Carlo (Coreset MCMC), uses draws from an adaptive Markov chain targeting the coreset posterior to train the coreset weights via stochastic gradient optimization. However, the quality of the constructed coreset, and thus the quality of its posterior approximation, is sensitive to the stochastic optimization learning rate. In this work, we propose a learning-rate-free stochastic gradient optimization procedure, Hot-start Distance over Gradient (Hot DoG), for training coreset weights in Coreset MCMC without user tuning effort. Empirical results demonstrate that Hot DoG provides higher quality posterior approximations than other learning-rate-free stochastic gradient methods, and performs competitively to optimally-tuned ADAM.
Coreset Markov Chain Monte Carlo
Oct 25, 2023
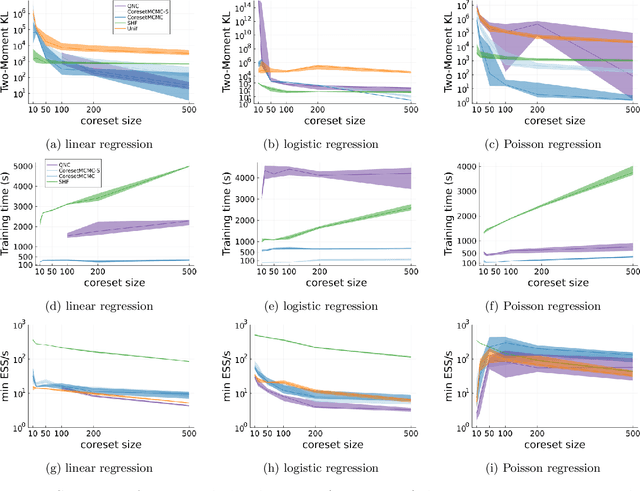
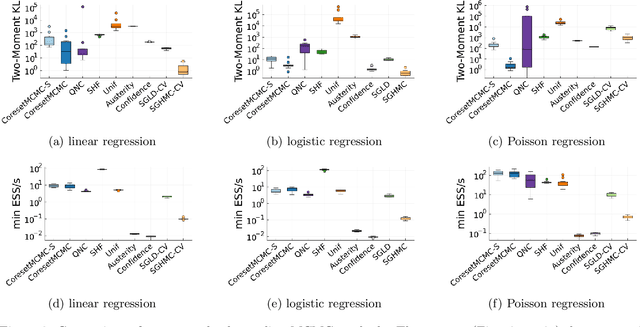
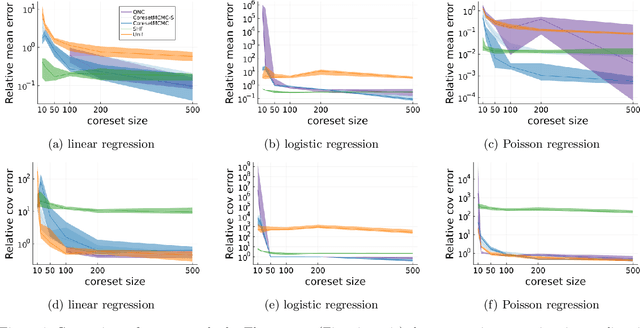
A Bayesian coreset is a small, weighted subset of data that replaces the full dataset during inference in order to reduce computational cost. However, state of the art methods for tuning coreset weights are expensive, require nontrivial user input, and impose constraints on the model. In this work, we propose a new method -- Coreset MCMC -- that simulates a Markov chain targeting the coreset posterior, while simultaneously updating the coreset weights using those same draws. Coreset MCMC is simple to implement and tune, and can be used with any existing MCMC kernel. We analyze Coreset MCMC in a representative setting to obtain key insights about the convergence behaviour of the method. Empirical results demonstrate that Coreset MCMC provides higher quality posterior approximations and reduced computational cost compared with other coreset construction methods. Further, compared with other general subsampling MCMC methods, we find that Coreset MCMC has a higher sampling efficiency with competitively accurate posterior approximations.
Ergodic variational flows
May 16, 2022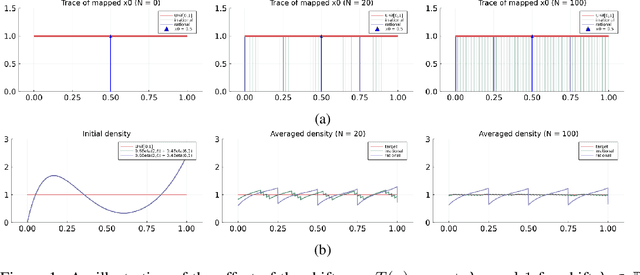
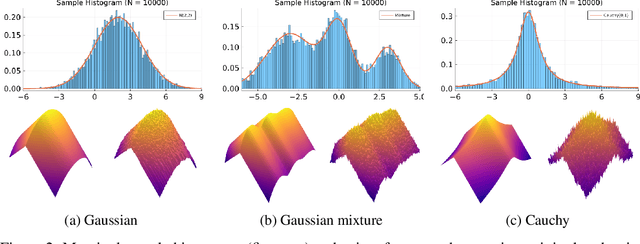
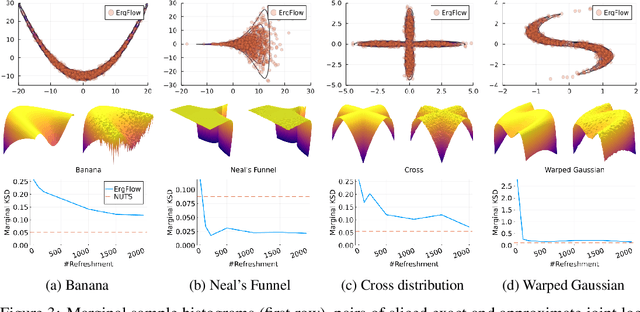
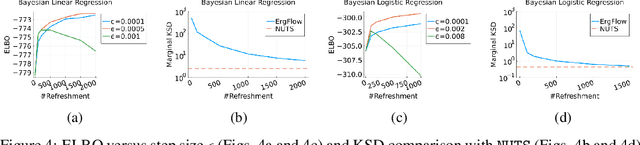
This work presents a new class of variational family -- ergodic variational flows -- that not only enables tractable i.i.d. sampling and density evaluation, but also comes with MCMC-like convergence guarantees. Ergodic variational flows consist of a mixture of repeated applications of a measure-preserving and ergodic map to an initial reference distribution. We provide mild conditions under which the variational distribution converges weakly and in total variation to the target as the number of steps in the flow increases; this convergence holds regardless of the value of variational parameters, although different parameter values may result in faster or slower convergence. Further, we develop a particular instantiation of the general family using Hamiltonian dynamics combined with deterministic momentum refreshment. Simulated and real data experiments provide an empirical verification of the convergence theory and demonstrate that samples produced by the method are of comparable quality to a state-of-the-art MCMC method.
Bayesian inference via sparse Hamiltonian flows
Mar 11, 2022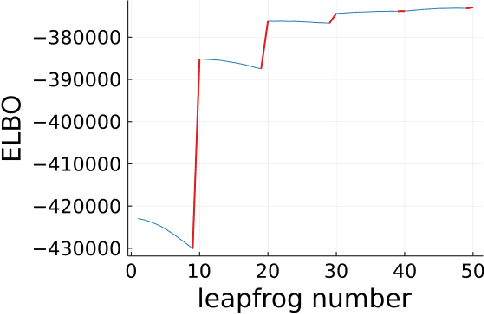

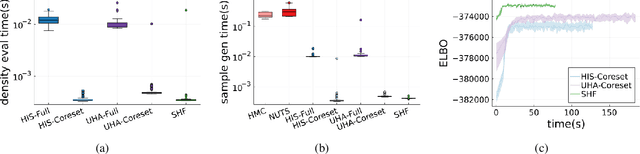
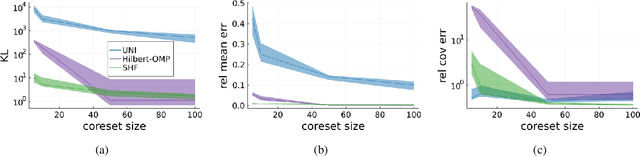
A Bayesian coreset is a small, weighted subset of data that replaces the full dataset during Bayesian inference, with the goal of reducing computational cost. Although past work has shown empirically that there often exists a coreset with low inferential error, efficiently constructing such a coreset remains a challenge. Current methods tend to be slow, require a secondary inference step after coreset construction, and do not provide bounds on the data marginal evidence. In this work, we introduce a new method -- sparse Hamiltonian flows -- that addresses all three of these challenges. The method involves first subsampling the data uniformly, and then optimizing a Hamiltonian flow parametrized by coreset weights and including periodic momentum quasi-refreshment steps. Theoretical results show that the method enables an exponential compression of the dataset in a representative model, and that the quasi-refreshment steps reduce the KL divergence to the target. Real and synthetic experiments demonstrate that sparse Hamiltonian flows provide accurate posterior approximations with significantly reduced runtime compared with competing dynamical-system-based inference methods.