 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Inference with Stochastic Gradient Algorithms
Paper and Code

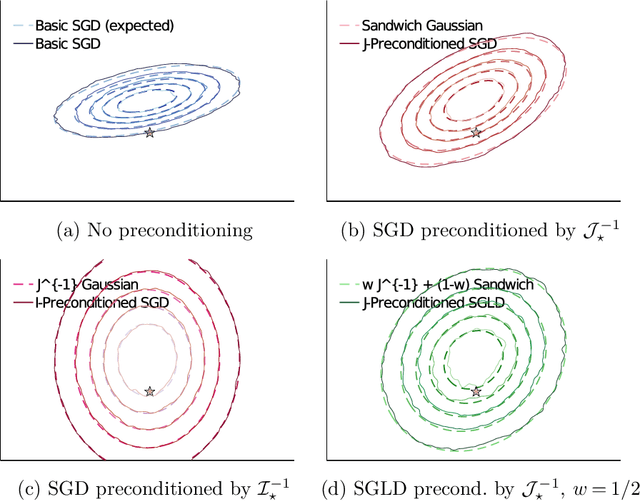
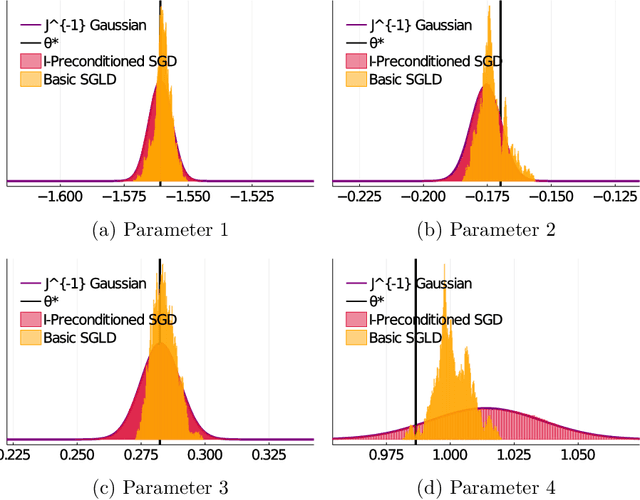
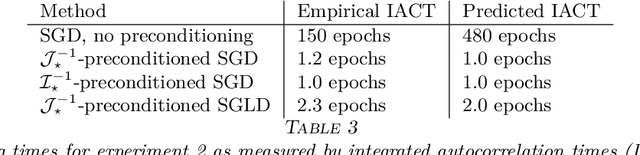
Stochastic gradient algorithms are widely used for both optimization and sampling in large-scale learning and inference problems. However, in practice, tuning these algorithms is typically done using heuristics and trial-and-error rather than rigorous, generalizable theory. To address this gap between theory and practice, we novel insights into the effect of tuning parameters by characterizing the large-sample behavior of iterates of a very general class of preconditioned stochastic gradient algorithms with fixed step size. In the optimization setting, our results show that iterate averaging with a large fixed step size can result in statistically efficient approximation of the (local) M-estimator. In the sampling context, our results show that with appropriate choices of tuning parameters, the limiting stationary covariance can match either the Bernstein--von Mises limit of the posterior, adjustments to the posterior for model misspecification, or the asymptotic distribution of the MLE; and that with a naive tuning the limit corresponds to none of these. Moreover, we argue that an essentially independent sample from the stationary distribution can be obtained after a fixed number of passes over the dataset. We validate our asymptotic results in realistic finite-sample regimes via several experiments using simulated and real data. Overall, we demonstrate that properly tuned stochastic gradient algorithms with constant step size offer a computationally efficient and statistically robust approach to obtaining point estimates or posterior-like samples.