 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Outlier Dynamics in LLM NVFP4 Pretraining
Feb 02, 2026Training large language models using 4-bit arithmetic enhances throughput and memory efficiency. Yet, the limited dynamic range of FP4 increases sensitivity to outliers. While NVFP4 mitigates quantization error via hierarchical microscaling, a persistent loss gap remains compared to BF16. This study conducts a longitudinal analysis of outlier dynamics across architecture during NVFP4 pretraining, focusing on where they localize, why they occur, and how they evolve temporally. We find that, compared with Softmax Attention (SA), Linear Attention (LA) reduces per-tensor heavy tails but still exhibits persistent block-level spikes under block quantization. Our analysis attributes outliers to specific architectural components: Softmax in SA, gating in LA, and SwiGLU in FFN, with "post-QK" operations exhibiting higher sensitivity to quantization. Notably, outliers evolve from transient spikes early in training to a small set of persistent hot channels (i.e., channels with persistently large magnitudes) in later stages. Based on these findings, we introduce Hot-Channel Patch (HCP), an online compensation mechanism that identifies hot channels and reinjects residuals using hardware-efficient kernels. We then develop CHON, an NVFP4 training recipe integrating HCP with post-QK operation protection. On GLA-1.3B model trained for 60B tokens, CHON reduces the loss gap to BF16 from 0.94% to 0.58% while maintaining downstream accuracy.
When Deepfakes Look Real: Detecting AI-Generated Faces with Unlabeled Data due to Annotation Challenges
Aug 12, 2025Existing deepfake detection methods heavily depend on labeled training data. However, as AI-generated content becomes increasingly realistic, even \textbf{human annotators struggle to distinguish} between deepfakes and authentic images. This makes the labeling process both time-consuming and less reliable. Specifically, there is a growing demand for approaches that can effectively utilize large-scale unlabeled data from online social networks. Unlike typical unsupervised learning tasks, where categories are distinct, AI-generated faces closely mimic real image distributions and share strong similarities, causing performance drop in conventional strategies. In this paper, we introduce the Dual-Path Guidance Network (DPGNet), to tackle two key challenges: (1) bridging the domain gap between faces from different generation models, and (2) utilizing unlabeled image samples. The method features two core modules: text-guided cross-domain alignment, which uses learnable prompts to unify visual and textual embeddings into a domain-invariant feature space, and curriculum-driven pseudo label generation, which dynamically exploit more informative unlabeled samples. To prevent catastrophic forgetting, we also facilitate bridging between domains via cross-domain knowledge distillation. Extensive experiments on \textbf{11 popular datasets}, show that DPGNet outperforms SoTA approaches by \textbf{6.3\%}, highlighting its effectiveness in leveraging unlabeled data to address the annotation challenges posed by the increasing realism of deepfakes.
InstGenIE: Generative Image Editing Made Efficient with Mask-aware Caching and Scheduling
May 27, 2025
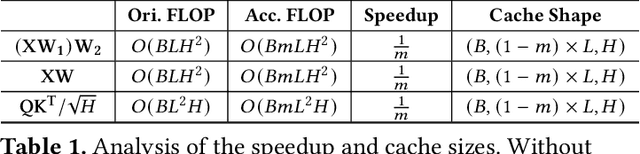
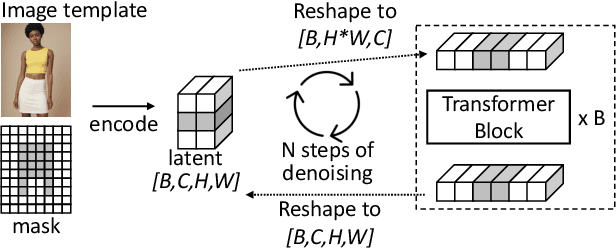
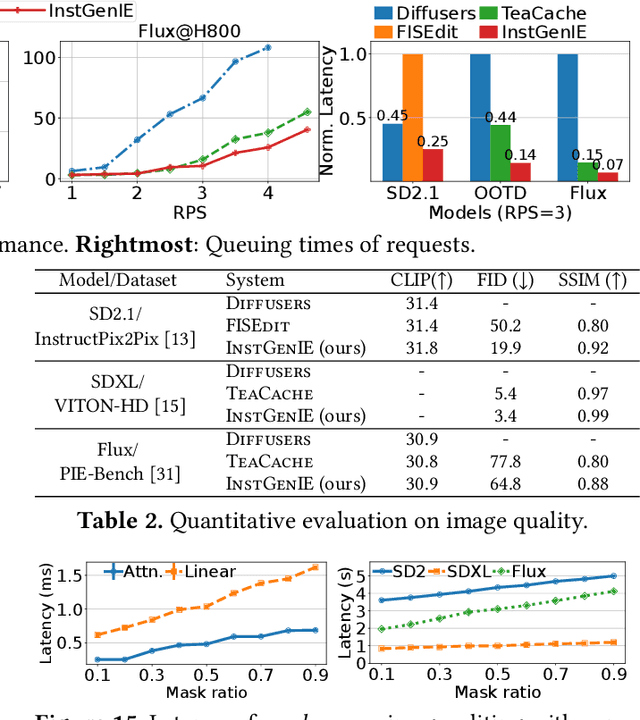
Generative image editing using diffusion models has become a prevalent application in today's AI cloud services. In production environments, image editing typically involves a mask that specifies the regions of an image template to be edited. The use of masks provides direct control over the editing process and introduces sparsity in the model inference. In this paper, we present InstGenIE, a system that efficiently serves image editing requests. The key insight behind InstGenIE is that image editing only modifies the masked regions of image templates while preserving the original content in the unmasked areas. Driven by this insight, InstGenIE judiciously skips redundant computations associated with the unmasked areas by reusing cached intermediate activations from previous inferences. To mitigate the high cache loading overhead, InstGenIE employs a bubble-free pipeline scheme that overlaps computation with cache loading. Additionally, to reduce queuing latency in online serving while improving the GPU utilization, InstGenIE proposes a novel continuous batching strategy for diffusion model serving, allowing newly arrived requests to join the running batch in just one step of denoising computation, without waiting for the entire batch to complete. As heterogeneous masks induce imbalanced loads, InstGenIE also develops a load balancing strategy that takes into account the loads of both computation and cache loading. Collectively, InstGenIE outperforms state-of-the-art diffusion serving systems for image editing, achieving up to 3x higher throughput and reducing average request latency by up to 14.7x while ensuring image quality.
Teacher Motion Priors: Enhancing Robot Locomotion over Challenging Terrain
Apr 14, 2025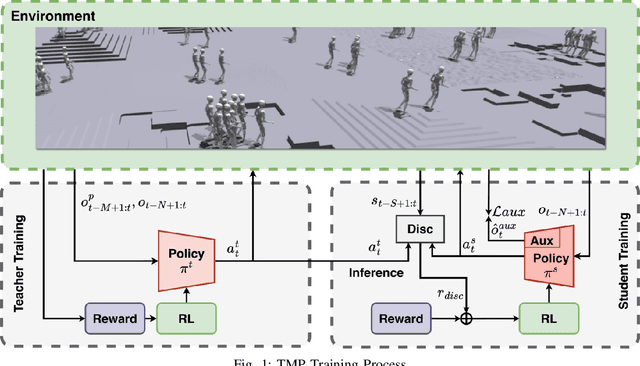
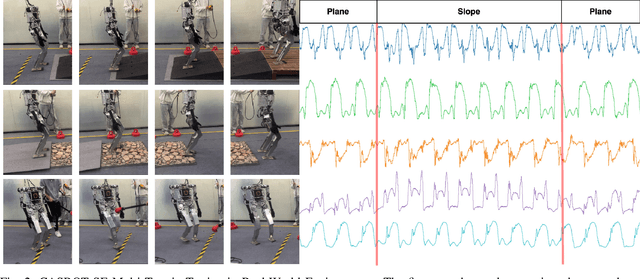
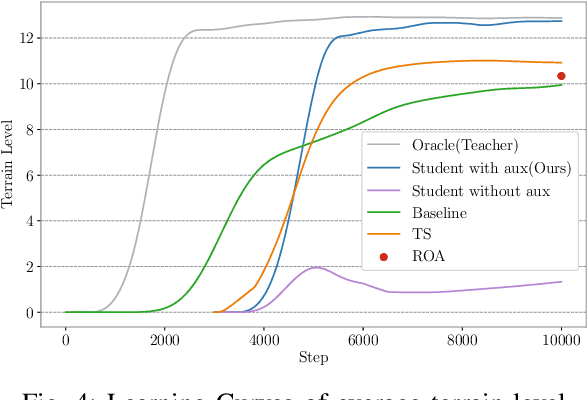
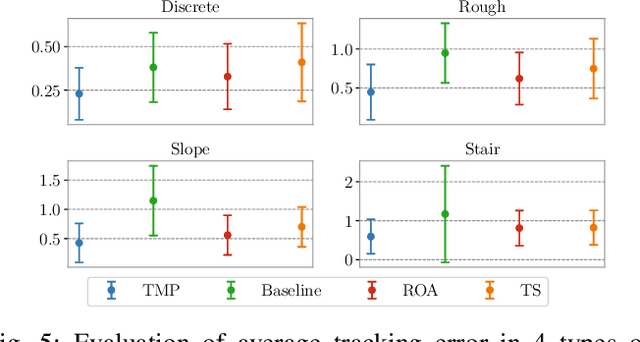
Achieving robust locomotion on complex terrains remains a challenge due to high dimensional control and environmental uncertainties. This paper introduces a teacher prior framework based on the teacher student paradigm, integrating imitation and auxiliary task learning to improve learning efficiency and generalization. Unlike traditional paradigms that strongly rely on encoder-based state embeddings, our framework decouples the network design, simplifying the policy network and deployment. A high performance teacher policy is first trained using privileged information to acquire generalizable motion skills. The teacher's motion distribution is transferred to the student policy, which relies only on noisy proprioceptive data, via a generative adversarial mechanism to mitigate performance degradation caused by distributional shifts. Additionally, auxiliary task learning enhances the student policy's feature representation, speeding up convergence and improving adaptability to varying terrains. The framework is validated on a humanoid robot, showing a great improvement in locomotion stability on dynamic terrains and significant reductions in development costs. This work provides a practical solution for deploying robust locomotion strategies in humanoid robots.
SwiftDiffusion: Efficient Diffusion Model Serving with Add-on Modules
Jul 02, 2024



This paper documents our characterization study and practices for serving text-to-image requests with stable diffusion models in production. We first comprehensively analyze inference request traces for commercial text-to-image applications. It commences with our observation that add-on modules, i.e., ControlNets and LoRAs, that augment the base stable diffusion models, are ubiquitous in generating images for commercial applications. Despite their efficacy, these add-on modules incur high loading overhead, prolong the serving latency, and swallow up expensive GPU resources. Driven by our characterization study, we present SwiftDiffusion, a system that efficiently generates high-quality images using stable diffusion models and add-on modules. To achieve this, SwiftDiffusion reconstructs the existing text-to-image serving workflow by identifying the opportunities for parallel computation and distributing ControlNet computations across multiple GPUs. Further, SwiftDiffusion thoroughly analyzes the dynamics of image generation and develops techniques to eliminate the overhead associated with LoRA loading and patching while preserving the image quality. Last, SwiftDiffusion proposes specialized optimizations in the backbone architecture of the stable diffusion models, which are also compatible with the efficient serving of add-on modules. Compared to state-of-the-art text-to-image serving systems, SwiftDiffusion reduces serving latency by up to 5x and improves serving throughput by up to 2x without compromising image quality.