 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Optimal Individualized Treatment Rules for Bivariate Survival Outcomes via Adaptive Prediction-Powered Learning
May 28, 2026In randomized trials involving multiple treatments, bivariate survival outcomes present significant analytical challenges for making decisions. This paper addresses the problem of deriving optimal individualized treatment rules to maximize the joint survival probability beyond fixed time points $(t_1, t_2)$ through deep neural networks, while accounting for right censoring. We propose a novel approach that models treatment rules via stochastic policies, coupling marginal accelerated failure time models via link function to capture bivariate dependence. To enhance robustness and effectiveness of decision making, we introduce an adaptive prediction-powered method that leverages auxiliary predictions from machine learning models.
Proximal Path-Specific Inference
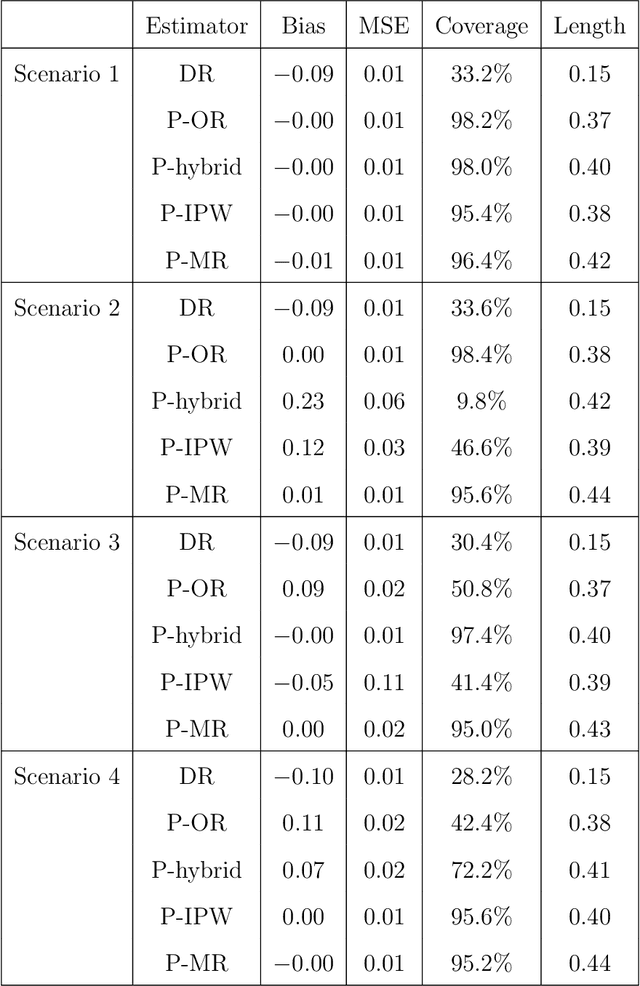
May 10, 2026Causal mediation analysis has been extended to estimate path-specific effects with multiple intermediate variables, isolating treatment effects through a mediator of interest while excluding pathways through its ancestors. Such analyses address bias from recanting witnesses, i.e., treatment-induced mediator-outcome confounders. However, existing methods typically rely on stringent assumptions precluding general unmeasured confounding, which are often violated in practice. In this paper, we relax these restrictions by leveraging observed covariates as proxy variables to accommodate unmeasured confounding among the treatment, recanting witness, mediator, and outcome. Using proximal confounding bridge functions, we develop four nonparametric identification strategies for the path-specific effect. We further derive the efficient influence function and propose a quadruply robust, locally efficient estimator. To handle high-dimensional nuisance parameters, we propose a proximal debiased machine learning approach. We theoretically guarantee that our estimator achieves $\sqrt{n}$-consistency and asymptotic normality even when machine learning estimators for nuisance functions converge at slower rates. Our approaches are validated via semiparametric and nonparametric simulations and an application to the CDC WONDER Natality study, estimating the path-specific effect of prenatal care on preterm birth through preeclampsia, independent of maternal smoking during pregnancy.
Double Machine Learning of Continuous Treatment Effects with General Instrumental Variables
Jan 04, 2026Estimating causal effects of continuous treatments is a common problem in practice, for example, in studying dose-response functions. Classical analyses typically assume that all confounders are fully observed, whereas in real-world applications, unmeasured confounding often persists. In this article, we propose a novel framework for local identification of dose-response functions using instrumental variables, thereby mitigating bias induced by unobserved confounders. We introduce the concept of a uniform regular weighting function and consider covering the treatment space with a finite collection of open sets. On each of these sets, such a weighting function exists, allowing us to identify the dose-response function locally within the corresponding region. For estimation, we develop an augmented inverse probability weighting score for continuous treatments under a debiased machine learning framework with instrumental variables. We further establish the asymptotic properties when the dose-response function is estimated via kernel regression or empirical risk minimization. Finally, we conduct both simulation and empirical studies to assess the finite-sample performance of the proposed methods.
Identification and Debiased Learning of Causal Effects with General Instrumental Variables
Oct 23, 2025Instrumental variable methods are fundamental to causal inference when treatment assignment is confounded by unobserved variables. In this article, we develop a general nonparametric framework for identification and learning with multi-categorical or continuous instrumental variables. Specifically, we propose an additive instrumental variable framework to identify mean potential outcomes and the average treatment effect with a weighting function. Leveraging semiparametric theory, we derive efficient influence functions and construct consistent, asymptotically normal estimators via debiased machine learning. Extensions to longitudinal data, dynamic treatment regimes, and multiplicative instrumental variables are further developed. We demonstrate the proposed method by employing simulation studies and analyzing real data from the Job Training Partnership Act program.
On Multiple Robustness of Proximal Dynamic Treatment Regimes
Oct 23, 2025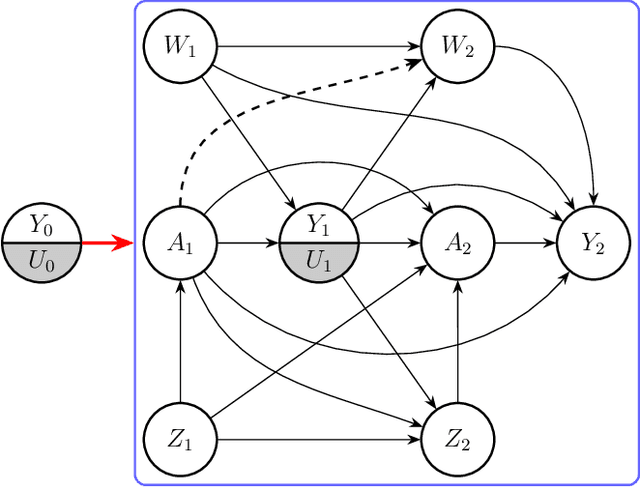
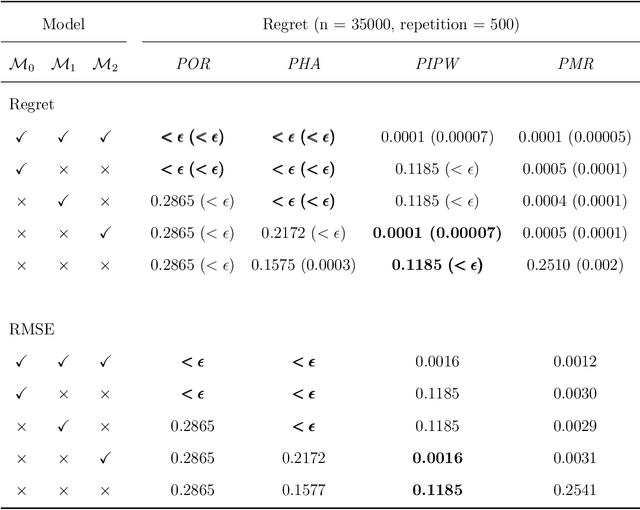
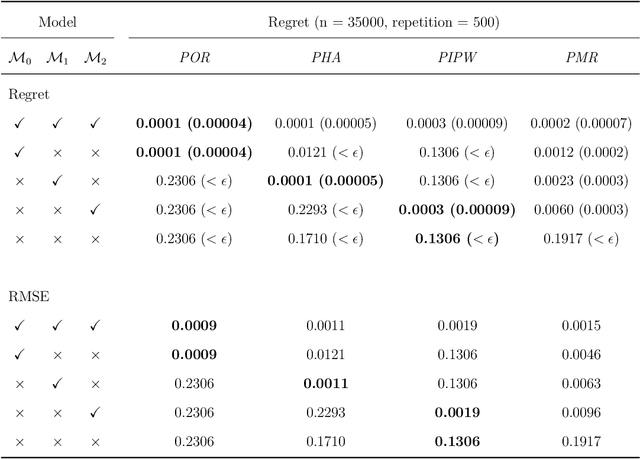
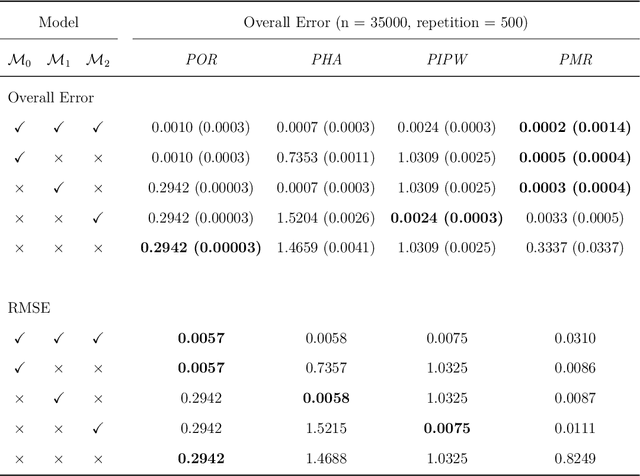
Dynamic treatment regimes are sequential decision rules that adapt treatment according to individual time-varying characteristics and outcomes to achieve optimal effects, with applications in precision medicine, personalized recommendations, and dynamic marketing. Estimating optimal dynamic treatment regimes via sequential randomized trials might face costly and ethical hurdles, often necessitating the use of historical observational data. In this work, we utilize proximal causal inference framework for learning optimal dynamic treatment regimes when the unconfoundedness assumption fails. Our contributions are four-fold: (i) we propose three nonparametric identification methods for optimal dynamic treatment regimes; (ii) we establish the semiparametric efficiency bound for the value function of a given regime; (iii) we propose a (K+1)-robust method for learning optimal dynamic treatment regimes, where K is the number of stages; (iv) as a by-product for marginal structural models, we establish identification and estimation of counterfactual means under a static regime. Numerical experiments validate the efficiency and multiple robustness of our proposed methods.
Reinforcement Learning with Continuous Actions Under Unmeasured Confounding
May 01, 2025This paper addresses the challenge of offline policy learning in reinforcement learning with continuous action spaces when unmeasured confounders are present. While most existing research focuses on policy evaluation within partially observable Markov decision processes (POMDPs) and assumes discrete action spaces, we advance this field by establishing a novel identification result to enable the nonparametric estimation of policy value for a given target policy under an infinite-horizon framework. Leveraging this identification, we develop a minimax estimator and introduce a policy-gradient-based algorithm to identify the in-class optimal policy that maximizes the estimated policy value. Furthermore, we provide theoretical results regarding the consistency, finite-sample error bound, and regret bound of the resulting optimal policy. Extensive simulations and a real-world application using the German Family Panel data demonstrate the effectiveness of our proposed methodology.
Proximal Inference on Population Intervention Indirect Effect
Apr 16, 2025

The population intervention indirect effect (PIIE) is a novel mediation effect representing the indirect component of the population intervention effect. Unlike traditional mediation measures, such as the natural indirect effect, the PIIE holds particular relevance in observational studies involving unethical exposures, when hypothetical interventions that impose harmful exposures are inappropriate. Although prior research has identified PIIE under unmeasured confounders between exposure and outcome, it has not fully addressed the confounding that affects the mediator. This study extends the PIIE identification to settings where unmeasured confounders influence exposure-outcome, exposure-mediator, and mediator-outcome relationships. Specifically, we leverage observed covariates as proxy variables for unmeasured confounders, constructing three proximal identification frameworks. Additionally, we characterize the semiparametric efficiency bound and develop multiply robust and locally efficient estimators. To handle high-dimensional nuisance parameters, we propose a debiased machine learning approach that achieves $\sqrt{n}$-consistency and asymptotic normality to estimate the true PIIE values, even when the machine learning estimators for the nuisance functions do not converge at $\sqrt{n}$-rate. In simulations, our estimators demonstrate higher confidence interval coverage rates than conventional methods across various model misspecifications. In a real data application, our approaches reveal an indirect effect of alcohol consumption on depression risk mediated by depersonalization symptoms.
Vision Technologies with Applications in Traffic Surveillance Systems: A Holistic Survey
Nov 30, 2024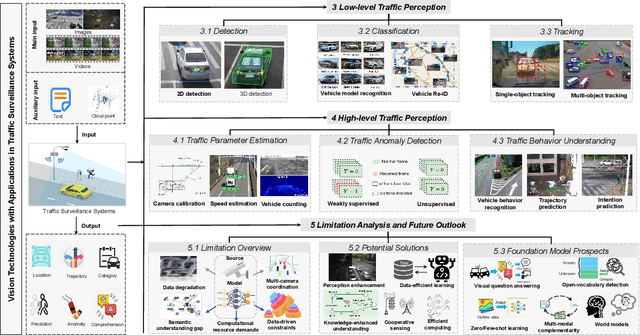
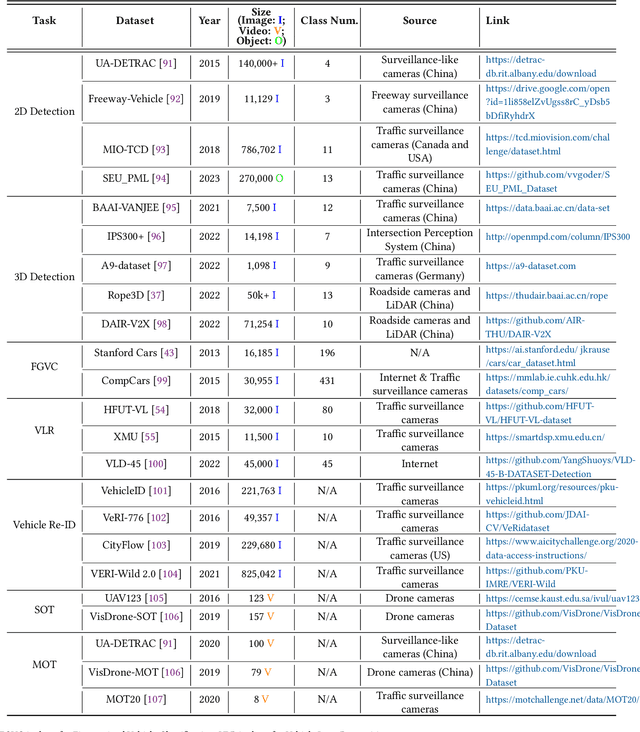
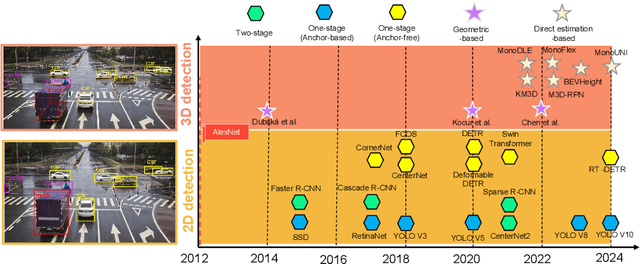
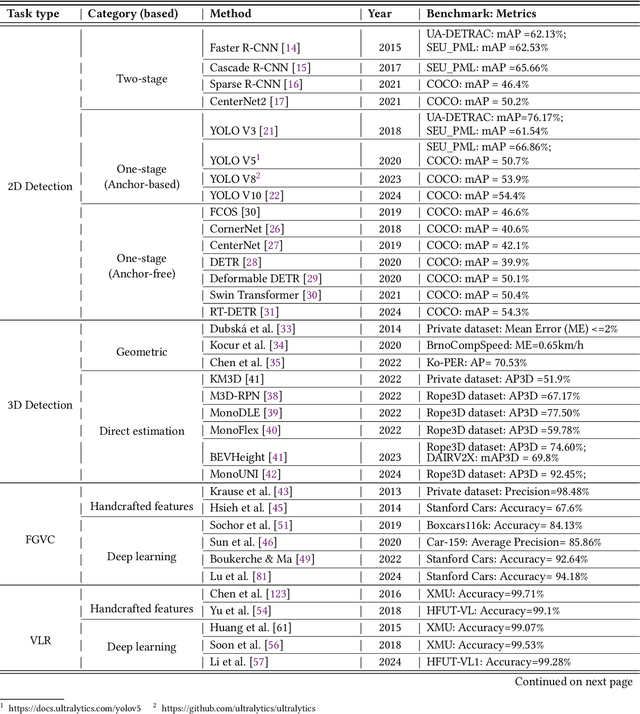
Traffic Surveillance Systems (TSS) have become increasingly crucial in modern intelligent transportation systems, with vision-based technologies playing a central role for scene perception and understanding. While existing surveys typically focus on isolated aspects of TSS, a comprehensive analysis bridging low-level and high-level perception tasks, particularly considering emerging technologies, remains lacking. This paper presents a systematic review of vision-based technologies in TSS, examining both low-level perception tasks (object detection, classification, and tracking) and high-level perception applications (parameter estimation, anomaly detection, and behavior understanding). Specifically, we first provide a detailed methodological categorization and comprehensive performance evaluation for each task. Our investigation reveals five fundamental limitations in current TSS: perceptual data degradation in complex scenarios, data-driven learning constraints, semantic understanding gaps, sensing coverage limitations and computational resource demands. To address these challenges, we systematically analyze five categories of potential solutions: advanced perception enhancement, efficient learning paradigms, knowledge-enhanced understanding, cooperative sensing frameworks and efficient computing frameworks. Furthermore, we evaluate the transformative potential of foundation models in TSS, demonstrating their unique capabilities in zero-shot learning, semantic understanding, and scene generation. This review provides a unified framework bridging low-level and high-level perception tasks, systematically analyzes current limitations and solutions, and presents a structured roadmap for integrating emerging technologies, particularly foundation models, to enhance TSS capabilities.
Learning Robust Treatment Rules for Censored Data
Aug 17, 2024



There is a fast-growing literature on estimating optimal treatment rules directly by maximizing the expected outcome. In biomedical studies and operations applications, censored survival outcome is frequently observed, in which case the restricted mean survival time and survival probability are of great interest. In this paper, we propose two robust criteria for learning optimal treatment rules with censored survival outcomes; the former one targets at an optimal treatment rule maximizing the restricted mean survival time, where the restriction is specified by a given quantile such as median; the latter one targets at an optimal treatment rule maximizing buffered survival probabilities, where the predetermined threshold is adjusted to account the restricted mean survival time. We provide theoretical justifications for the proposed optimal treatment rules and develop a sampling-based difference-of-convex algorithm for learning them. In simulation studies, our estimators show improved performance compared to existing methods. We also demonstrate the proposed method using AIDS clinical trial data.
Individualized Treatment Allocations with Distributional Welfare
Nov 27, 2023



In this paper, we explore optimal treatment allocation policies that target distributional welfare. Most literature on treatment choice has considered utilitarian welfare based on the conditional average treatment effect (ATE). While average welfare is intuitive, it may yield undesirable allocations especially when individuals are heterogeneous (e.g., with outliers) - the very reason individualized treatments were introduced in the first place. This observation motivates us to propose an optimal policy that allocates the treatment based on the conditional \emph{quantile of individual treatment effects} (QoTE). Depending on the choice of the quantile probability, this criterion can accommodate a policymaker who is either prudent or negligent. The challenge of identifying the QoTE lies in its requirement for knowledge of the joint distribution of the counterfactual outcomes, which is generally hard to recover even with experimental data. Therefore, we introduce minimax optimal policies that are robust to model uncertainty. We then propose a range of identifying assumptions under which we can point or partially identify the QoTE. We establish the asymptotic bound on the regret of implementing the proposed policies. We consider both stochastic and deterministic rules. In simulations and two empirical applications, we compare optimal decisions based on the QoTE with decisions based on other criteria.