 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysical Depth-aware Early Accident Anticipation: A Multi-dimensional Visual Feature Fusion Framework
Feb 19, 2025Early accident anticipation from dashcam videos is a highly desirable yet challenging task for improving the safety of intelligent vehicles. Existing advanced accident anticipation approaches commonly model the interaction among traffic agents (e.g., vehicles, pedestrians, etc.) in the coarse 2D image space, which may not adequately capture their true positions and interactions. To address this limitation, we propose a physical depth-aware learning framework that incorporates the monocular depth features generated by a large model named Depth-Anything to introduce more fine-grained spatial 3D information. Furthermore, the proposed framework also integrates visual interaction features and visual dynamic features from traffic scenes to provide a more comprehensive perception towards the scenes. Based on these multi-dimensional visual features, the framework captures early indicators of accidents through the analysis of interaction relationships between objects in sequential frames. Additionally, the proposed framework introduces a reconstruction adjacency matrix for key traffic participants that are occluded, mitigating the impact of occluded objects on graph learning and maintaining the spatio-temporal continuity. Experimental results on public datasets show that the proposed framework attains state-of-the-art performance, highlighting the effectiveness of incorporating visual depth features and the superiority of the proposed framework.
Vision Technologies with Applications in Traffic Surveillance Systems: A Holistic Survey
Nov 30, 2024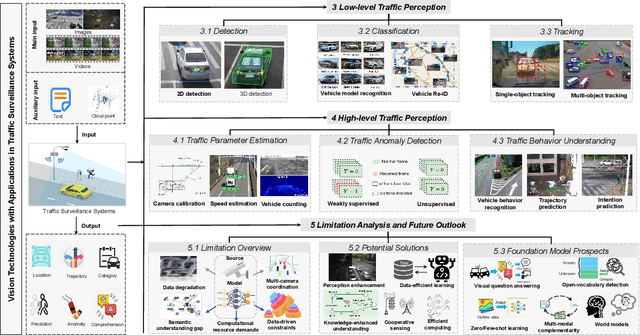
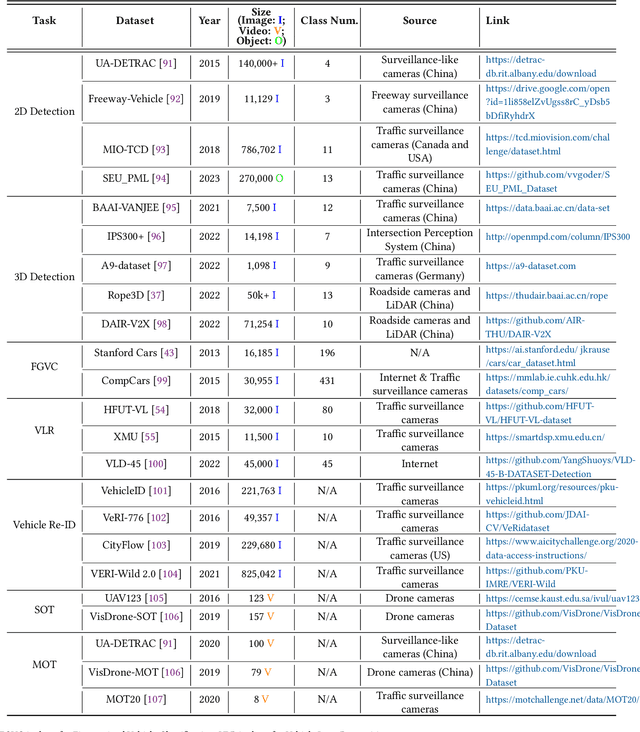
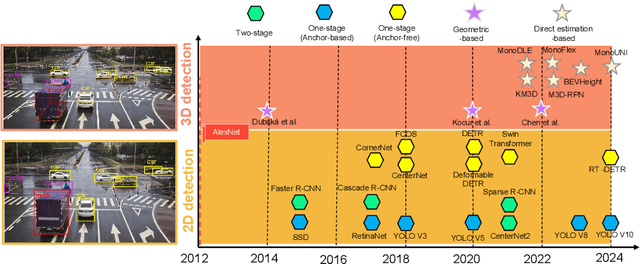
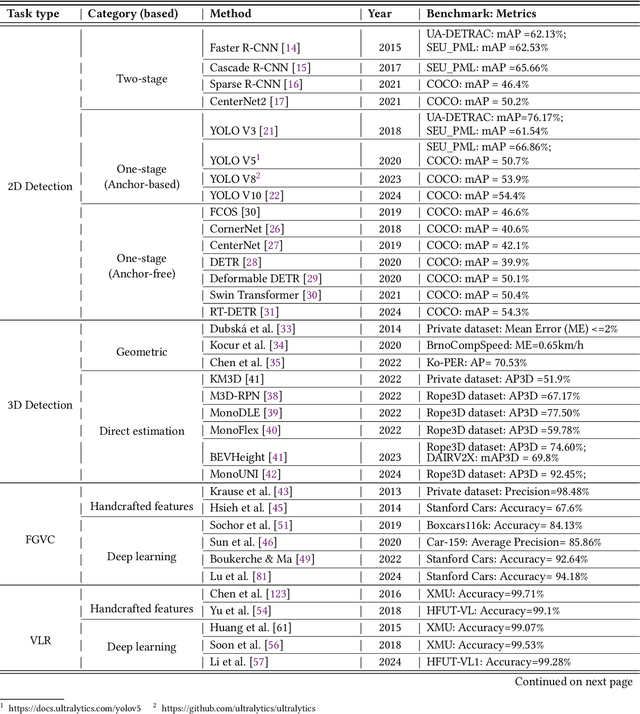
Traffic Surveillance Systems (TSS) have become increasingly crucial in modern intelligent transportation systems, with vision-based technologies playing a central role for scene perception and understanding. While existing surveys typically focus on isolated aspects of TSS, a comprehensive analysis bridging low-level and high-level perception tasks, particularly considering emerging technologies, remains lacking. This paper presents a systematic review of vision-based technologies in TSS, examining both low-level perception tasks (object detection, classification, and tracking) and high-level perception applications (parameter estimation, anomaly detection, and behavior understanding). Specifically, we first provide a detailed methodological categorization and comprehensive performance evaluation for each task. Our investigation reveals five fundamental limitations in current TSS: perceptual data degradation in complex scenarios, data-driven learning constraints, semantic understanding gaps, sensing coverage limitations and computational resource demands. To address these challenges, we systematically analyze five categories of potential solutions: advanced perception enhancement, efficient learning paradigms, knowledge-enhanced understanding, cooperative sensing frameworks and efficient computing frameworks. Furthermore, we evaluate the transformative potential of foundation models in TSS, demonstrating their unique capabilities in zero-shot learning, semantic understanding, and scene generation. This review provides a unified framework bridging low-level and high-level perception tasks, systematically analyzes current limitations and solutions, and presents a structured roadmap for integrating emerging technologies, particularly foundation models, to enhance TSS capabilities.