 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Control and Regret Analysis of Non-Stationary MDP with Look-ahead Information
Paper and Code
Sep 13, 2024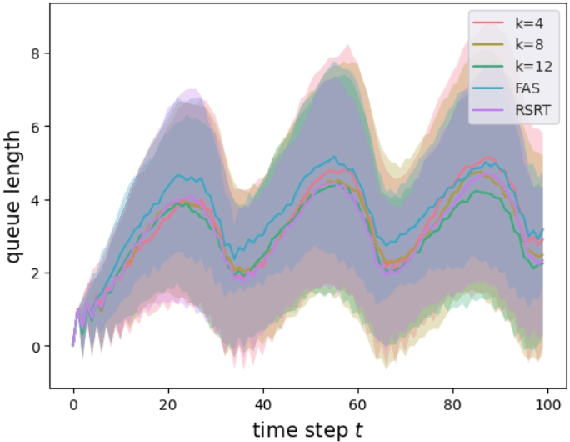
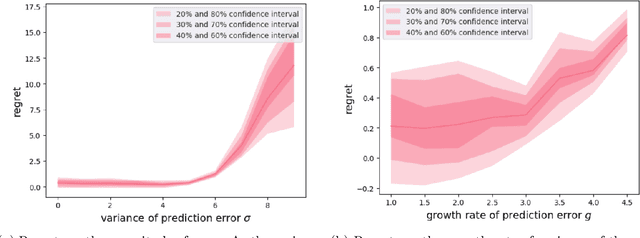
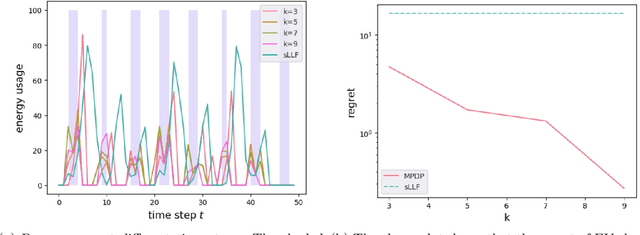
Policy design in non-stationary Markov Decision Processes (MDPs) is inherently challenging due to the complexities introduced by time-varying system transition and reward, which make it difficult for learners to determine the optimal actions for maximizing cumulative future rewards. Fortunately, in many practical applications, such as energy systems, look-ahead predictions are available, including forecasts for renewable energy generation and demand. In this paper, we leverage these look-ahead predictions and propose an algorithm designed to achieve low regret in non-stationary MDPs by incorporating such predictions. Our theoretical analysis demonstrates that, under certain assumptions, the regret decreases exponentially as the look-ahead window expands. When the system prediction is subject to error, the regret does not explode even if the prediction error grows sub-exponentially as a function of the prediction horizon. We validate our approach through simulations, confirming the efficacy of our algorithm in non-stationary environments.