 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Behavior Cloning: Offline Imitation Learning from Imperfect Human Demonstrations
May 16, 2025Learning from humans is challenging because people are imperfect teachers. When everyday humans show the robot a new task they want it to perform, humans inevitably make errors (e.g., inputting noisy actions) and provide suboptimal examples (e.g., overshooting the goal). Existing methods learn by mimicking the exact behaviors the human teacher provides -- but this approach is fundamentally limited because the demonstrations themselves are imperfect. In this work we advance offline imitation learning by enabling robots to extrapolate what the human teacher meant, instead of only considering what the human actually showed. We achieve this by hypothesizing that all of the human's demonstrations are trying to convey a single, consistent policy, while the noise and sub-optimality within their behaviors obfuscates the data and introduces unintentional complexity. To recover the underlying policy and learn what the human teacher meant, we introduce Counter-BC, a generalized version of behavior cloning. Counter-BC expands the given dataset to include actions close to behaviors the human demonstrated (i.e., counterfactual actions that the human teacher could have intended, but did not actually show). During training Counter-BC autonomously modifies the human's demonstrations within this expanded region to reach a simple and consistent policy that explains the underlying trends in the human's dataset. Theoretically, we prove that Counter-BC can extract the desired policy from imperfect data, multiple users, and teachers of varying skill levels. Empirically, we compare Counter-BC to state-of-the-art alternatives in simulated and real-world settings with noisy demonstrations, standardized datasets, and real human teachers. See videos of our work here: https://youtu.be/XaeOZWhTt68
CIVIL: Causal and Intuitive Visual Imitation Learning
Apr 24, 2025



Today's robots learn new tasks by imitating human examples. However, this standard approach to visual imitation learning is fundamentally limited: the robot observes what the human does, but not why the human chooses those behaviors. Without understanding the features that factor into the human's decisions, robot learners often misinterpret the data and fail to perform the task when the environment changes. We therefore propose a shift in perspective: instead of asking human teachers just to show what actions the robot should take, we also enable humans to indicate task-relevant features using markers and language prompts. Our proposed algorithm, CIVIL, leverages this augmented data to filter the robot's visual observations and extract a feature representation that causally informs human actions. CIVIL then applies these causal features to train a transformer-based policy that emulates human behaviors without being confused by visual distractors. Our simulations, real-world experiments, and user study demonstrate that robots trained with CIVIL can learn from fewer human demonstrations and perform better than state-of-the-art baselines, especially in previously unseen scenarios. See videos at our project website: https://civil2025.github.io
A Unified Framework for Robots that Influence Humans over Long-Term Interaction
Mar 18, 2025Robot actions influence the decisions of nearby humans. Here influence refers to intentional change: robots influence humans when they shift the human's behavior in a way that helps the robot complete its task. Imagine an autonomous car trying to merge; by proactively nudging into the human's lane, the robot causes human drivers to yield and provide space. Influence is often necessary for seamless interaction. However, if influence is left unregulated and uncontrolled, robots will negatively impact the humans around them. Prior works have begun to address this problem by creating a variety of control algorithms that seek to influence humans. Although these methods are effective in the short-term, they fail to maintain influence over time as the human adapts to the robot's behaviors. In this paper we therefore present an optimization framework that enables robots to purposely regulate their influence over humans across both short-term and long-term interactions. Here the robot maintains its influence by reasoning over a dynamic human model which captures how the robot's current choices will impact the human's future behavior. Our resulting framework serves to unify current approaches: we demonstrate that state-of-the-art methods are simplifications of our underlying formalism. Our framework also provides a principled way to generate influential policies: in the best case the robot exactly solves our framework to find optimal, influential behavior. But when solving this optimization problem becomes impractical, designers can introduce their own simplifications to reach tractable approximations. We experimentally compare our unified framework to state-of-the-art baselines and ablations, and demonstrate across simulations and user studies that this framework is able to successfully influence humans over repeated interactions. See videos of our experiments here: https://youtu.be/nPekTUfUEbo
Aligning Learning with Communication in Shared Autonomy
Mar 18, 2024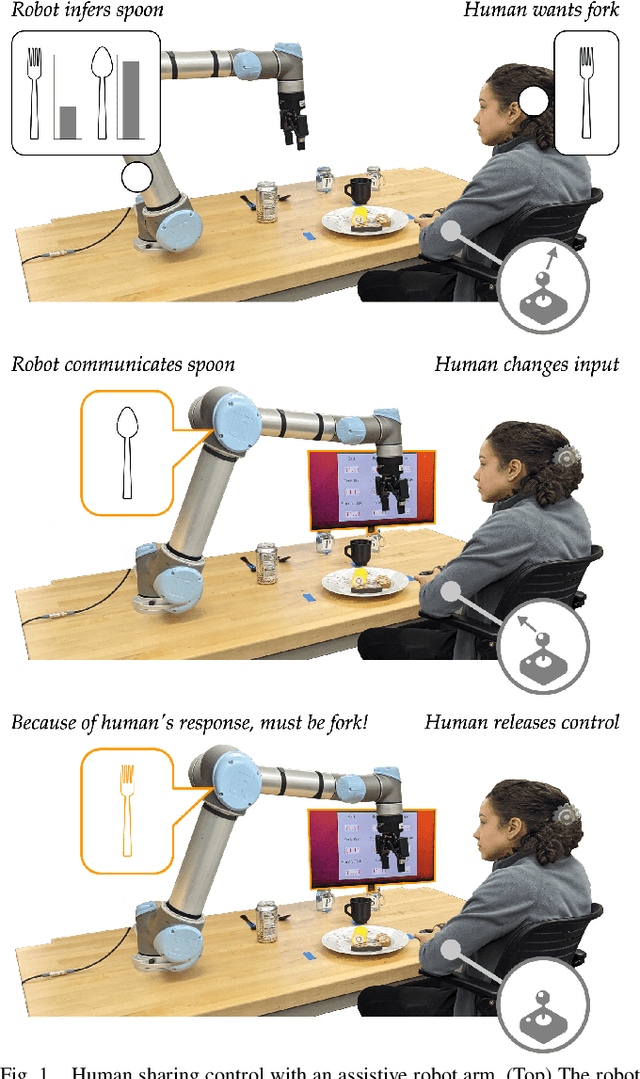
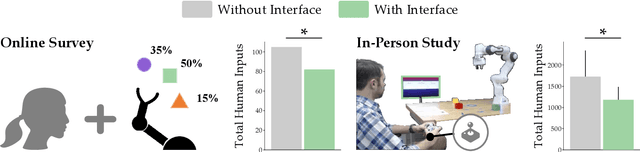
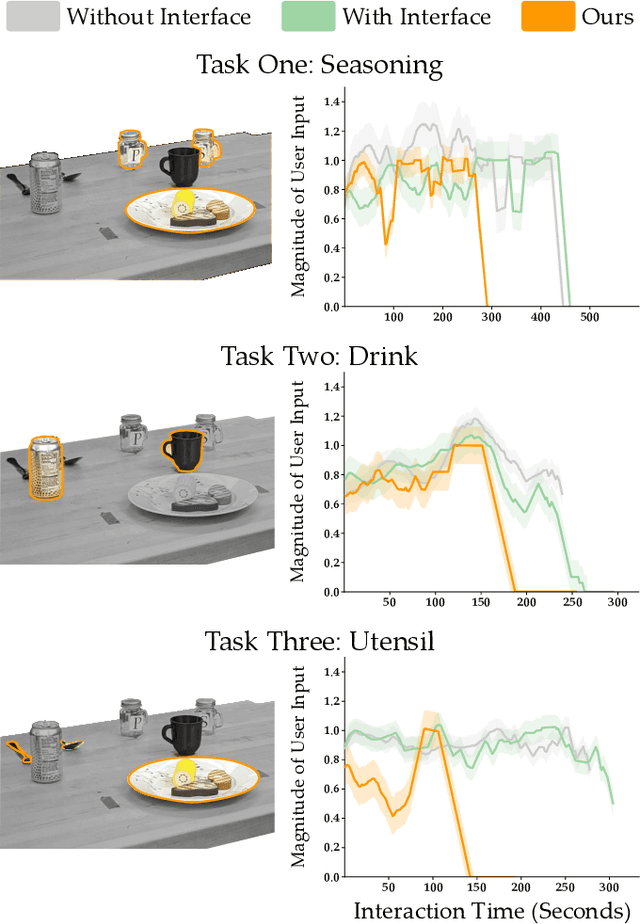
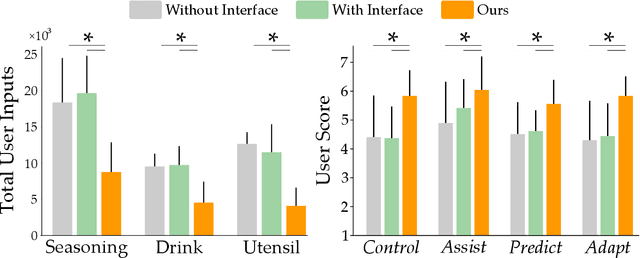
Assistive robot arms can help humans by partially automating their desired tasks. Consider an adult with motor impairments controlling an assistive robot arm to eat dinner. The robot can reduce the number of human inputs -- and how precise those inputs need to be -- by recognizing what the human wants (e.g., a fork) and assisting for that task (e.g., moving towards the fork). Prior research has largely focused on learning the human's task and providing meaningful assistance. But as the robot learns and assists, we also need to ensure that the human understands the robot's intent (e.g., does the human know the robot is reaching for a fork?). In this paper, we study the effects of communicating learned assistance from the robot back to the human operator. We do not focus on the specific interfaces used for communication. Instead, we develop experimental and theoretical models of a) how communication changes the way humans interact with assistive robot arms, and b) how robots can harness these changes to better align with the human's intent. We first conduct online and in-person user studies where participants operate robots that provide partial assistance, and we measure how the human's inputs change with and without communication. With communication, we find that humans are more likely to intervene when the robot incorrectly predicts their intent, and more likely to release control when the robot correctly understands their task. We then use these findings to modify an established robot learning algorithm so that the robot can correctly interpret the human's inputs when communication is present. Our results from a second in-person user study suggest that this combination of communication and learning outperforms assistive systems that isolate either learning or communication.
Should Collaborative Robots be Transparent?
Apr 23, 2023
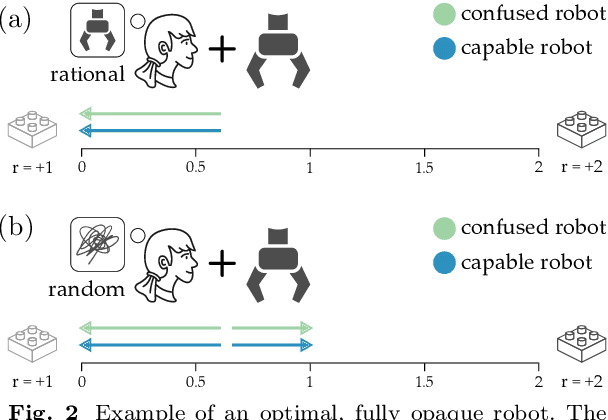
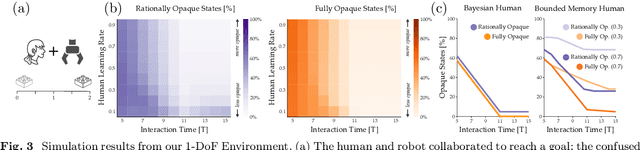
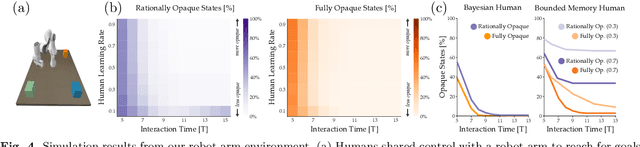
Today's robots often assume that their behavior should be transparent. These transparent (e.g., legible, explainable) robots intentionally choose actions that convey their internal state to nearby humans. But while transparent behavior seems beneficial, is it actually optimal? In this paper we consider collaborative settings where the human and robot have the same objective, and the human is uncertain about the robot's type (i.e., the robot's internal state). We extend a recursive combination of Bayesian Nash equilibrium and the Bellman equation to solve for optimal robot policies. Interestingly, we discover that it is not always optimal for collaborative robots to be transparent; instead, human and robot teams can sometimes achieve higher rewards when the robot is opaque. Opaque robots select the same actions regardless of their internal state: because each type of opaque robot behaves in the same way, the human cannot infer the robot's type. Our analysis suggests that opaque behavior becomes optimal when either (a) human-robot interactions have a short time horizon or (b) users are slow to learn from the robot's actions. Across online and in-person user studies with 43 total participants, we find that users reach higher rewards when working with opaque partners, and subjectively rate opaque robots as about equal to transparent robots. See videos of our experiments here: https://youtu.be/u8q1Z7WHUuI
Towards Robots that Influence Humans over Long-Term Interaction
Sep 21, 2022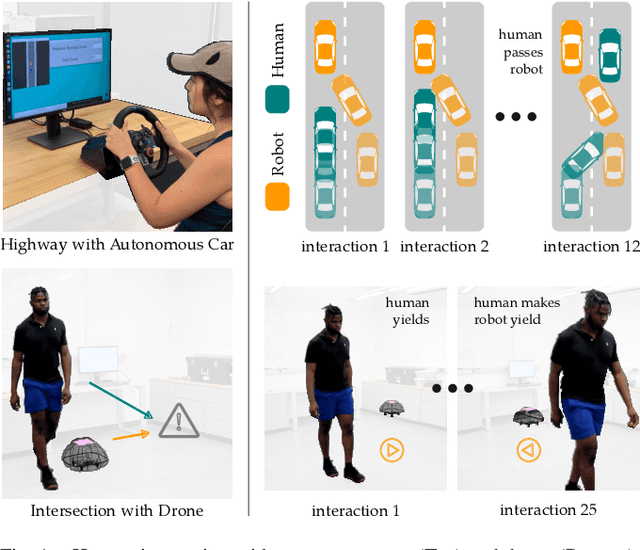
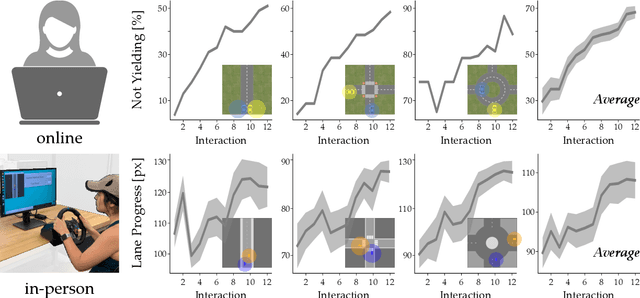
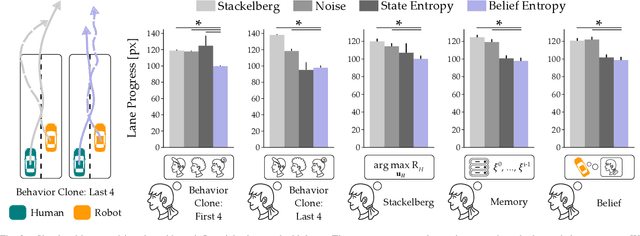
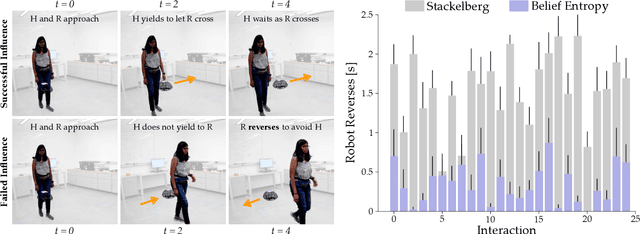
When humans interact with robots influence is inevitable. Consider an autonomous car driving near a human: the speed and steering of the autonomous car will affect how the human drives. Prior works have developed frameworks that enable robots to influence humans towards desired behaviors. But while these approaches are effective in the short-term (i.e., the first few human-robot interactions), here we explore long-term influence (i.e., repeated interactions between the same human and robot). Our central insight is that humans are dynamic: people adapt to robots, and behaviors which are influential now may fall short once the human learns to anticipate the robot's actions. With this insight, we experimentally demonstrate that a prevalent game-theoretic formalism for generating influential robot behaviors becomes less effective over repeated interactions. Next, we propose three modifications to Stackelberg games that make the robot's policy both influential and unpredictable. We finally test these modifications across simulations and user studies: our results suggest that robots which purposely make their actions harder to anticipate are better able to maintain influence over long-term interaction. See videos here: https://youtu.be/ydO83cgjZ2Q