 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTacStyle: Personalizing Tactile Robot Policies using Structured Behavior Representations
Jun 12, 2026Robotic systems that assist humans should be capable of adapting their behaviors to individual user preferences. For instance, users may want a robot arm to adjust the amount of force it applies while folding their laundry or cleaning furniture. Natural language provides an intuitive way for humans to communicate such preferences. Recent progress in language-conditioned robot policies has shown that robots can successfully use language prompts to determine what task to perform. However, extending the same approach to realize how the task should be performed requires detailed labels describing the preferences or styles of trajectories in the task data. Not only is collecting such annotations challenging, but conditioning directly on these labels may also fail to provide fine-grained control over a continuous range of behaviors. For example, it can be difficult to convey the exact force that a robot must apply through abstract instructions like "apply a bit more pressure than before". Therefore, in this work, we propose using language to reason over preferred behaviors instead of directly generating them. We first learn a structured latent representation that organizes user preferences according to differences in the corresponding trajectories. Then, given a preference prompt, we use a foundation model to interpret this latent space and choose a value that produces the desired behavior. Through both simulation and real-world experiments, we show that selecting robot behaviors from an intuitively structured latent space enables more precise adaptation to user preferences while requiring significantly fewer preference labels than language-conditioned policies.
Towards Balanced Behavior Cloning from Imbalanced Datasets
Aug 08, 2025Robots should be able to learn complex behaviors from human demonstrations. In practice, these human-provided datasets are inevitably imbalanced: i.e., the human demonstrates some subtasks more frequently than others. State-of-the-art methods default to treating each element of the human's dataset as equally important. So if -- for instance -- the majority of the human's data focuses on reaching a goal, and only a few state-action pairs move to avoid an obstacle, the learning algorithm will place greater emphasis on goal reaching. More generally, misalignment between the relative amounts of data and the importance of that data causes fundamental problems for imitation learning approaches. In this paper we analyze and develop learning methods that automatically account for mixed datasets. We formally prove that imbalanced data leads to imbalanced policies when each state-action pair is weighted equally; these policies emulate the most represented behaviors, and not the human's complex, multi-task demonstrations. We next explore algorithms that rebalance offline datasets (i.e., reweight the importance of different state-action pairs) without human oversight. Reweighting the dataset can enhance the overall policy performance. However, there is no free lunch: each method for autonomously rebalancing brings its own pros and cons. We formulate these advantages and disadvantages, helping other researchers identify when each type of approach is most appropriate. We conclude by introducing a novel meta-gradient rebalancing algorithm that addresses the primary limitations behind existing approaches. Our experiments show that dataset rebalancing leads to better downstream learning, improving the performance of general imitation learning algorithms without requiring additional data collection. See our project website: https://collab.me.vt.edu/data_curation/.
L2D2: Robot Learning from 2D Drawings
May 17, 2025Robots should learn new tasks from humans. But how do humans convey what they want the robot to do? Existing methods largely rely on humans physically guiding the robot arm throughout their intended task. Unfortunately -- as we scale up the amount of data -- physical guidance becomes prohibitively burdensome. Not only do humans need to operate robot hardware but also modify the environment (e.g., moving and resetting objects) to provide multiple task examples. In this work we propose L2D2, a sketching interface and imitation learning algorithm where humans can provide demonstrations by drawing the task. L2D2 starts with a single image of the robot arm and its workspace. Using a tablet, users draw and label trajectories on this image to illustrate how the robot should act. To collect new and diverse demonstrations, we no longer need the human to physically reset the workspace; instead, L2D2 leverages vision-language segmentation to autonomously vary object locations and generate synthetic images for the human to draw upon. We recognize that drawing trajectories is not as information-rich as physically demonstrating the task. Drawings are 2-dimensional and do not capture how the robot's actions affect its environment. To address these fundamental challenges the next stage of L2D2 grounds the human's static, 2D drawings in our dynamic, 3D world by leveraging a small set of physical demonstrations. Our experiments and user study suggest that L2D2 enables humans to provide more demonstrations with less time and effort than traditional approaches, and users prefer drawings over physical manipulation. When compared to other drawing-based approaches, we find that L2D2 learns more performant robot policies, requires a smaller dataset, and can generalize to longer-horizon tasks. See our project website: https://collab.me.vt.edu/L2D2/
CIVIL: Causal and Intuitive Visual Imitation Learning
Apr 24, 2025



Today's robots learn new tasks by imitating human examples. However, this standard approach to visual imitation learning is fundamentally limited: the robot observes what the human does, but not why the human chooses those behaviors. Without understanding the features that factor into the human's decisions, robot learners often misinterpret the data and fail to perform the task when the environment changes. We therefore propose a shift in perspective: instead of asking human teachers just to show what actions the robot should take, we also enable humans to indicate task-relevant features using markers and language prompts. Our proposed algorithm, CIVIL, leverages this augmented data to filter the robot's visual observations and extract a feature representation that causally informs human actions. CIVIL then applies these causal features to train a transformer-based policy that emulates human behaviors without being confused by visual distractors. Our simulations, real-world experiments, and user study demonstrate that robots trained with CIVIL can learn from fewer human demonstrations and perform better than state-of-the-art baselines, especially in previously unseen scenarios. See videos at our project website: https://civil2025.github.io
Kiri-Spoon: A Kirigami Utensil for Robot-Assisted Feeding
Jan 02, 2025
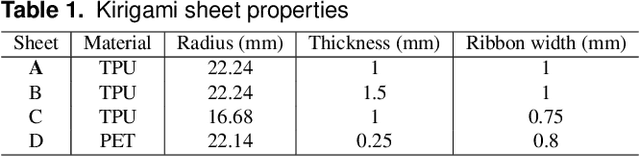


For millions of adults with mobility limitations, eating meals is a daily challenge. A variety of robotic systems have been developed to address this societal need. Unfortunately, end-user adoption of robot-assisted feeding is limited, in part because existing devices are unable to seamlessly grasp, manipulate, and feed diverse foods. Recent works seek to address this issue by creating new algorithms for food acquisition and bite transfer. In parallel to these algorithmic developments, however, we hypothesize that mechanical intelligence will make it fundamentally easier for robot arms to feed humans. We therefore propose Kiri-Spoon, a soft utensil specifically designed for robot-assisted feeding. Kiri-Spoon consists of a spoon-shaped kirigami structure: when actuated, the kirigami sheet deforms into a bowl of increasing curvature. Robot arms equipped with Kiri-Spoon can leverage the kirigami structure to wrap-around morsels during acquisition, contain those items as the robot moves, and then compliantly release the food into the user's mouth. Overall, Kiri-Spoon combines the familiar and comfortable shape of a standard spoon with the increased capabilities of soft robotic grippers. In what follows, we first apply a stakeholder-driven design process to ensure that Kiri-Spoon meets the needs of caregivers and users with physical disabilities. We next characterize the dynamics of Kiri-Spoon, and derive a mechanics model to relate actuation force to the spoon's shape. The paper concludes with three separate experiments that evaluate (a) the mechanical advantage provided by Kiri-Spoon, (b) the ways users with disabilities perceive our system, and (c) how the mechanical intelligence of Kiri-Spoon complements state-of-the-art algorithms. Our results suggest that Kiri-Spoon advances robot-assisted feeding across diverse foods, multiple robotic platforms, and different manipulation algorithms.
PECAN: Personalizing Robot Behaviors through a Learned Canonical Space
Jul 22, 2024



Robots should personalize how they perform tasks to match the needs of individual human users. Today's robot achieve this personalization by asking for the human's feedback in the task space. For example, an autonomous car might show the human two different ways to decelerate at stoplights, and ask the human which of these motions they prefer. This current approach to personalization is indirect: based on the behaviors the human selects (e.g., decelerating slowly), the robot tries to infer their underlying preference (e.g., defensive driving). By contrast, our paper develops a learning and interface-based approach that enables humans to directly indicate their desired style. We do this by learning an abstract, low-dimensional, and continuous canonical space from human demonstration data. Each point in the canonical space corresponds to a different style (e.g., defensive or aggressive driving), and users can directly personalize the robot's behavior by simply clicking on a point. Given the human's selection, the robot then decodes this canonical style across each task in the dataset -- e.g., if the human selects a defensive style, the autonomous car personalizes its behavior to drive defensively when decelerating, passing other cars, or merging onto highways. We refer to our resulting approach as PECAN: Personalizing Robot Behaviors through a Learned Canonical Space. Our simulations and user studies suggest that humans prefer using PECAN to directly personalize robot behavior (particularly when those users become familiar with PECAN), and that users find the learned canonical space to be intuitive and consistent. See videos here: https://youtu.be/wRJpyr23PKI
Accelerating Interface Adaptation with User-Friendly Priors
Mar 11, 2024


Robots often need to convey information to human users. For example, robots can leverage visual, auditory, and haptic interfaces to display their intent or express their internal state. In some scenarios there are socially agreed upon conventions for what these signals mean: e.g., a red light indicates an autonomous car is slowing down. But as robots develop new capabilities and seek to convey more complex data, the meaning behind their signals is not always mutually understood: one user might think a flashing light indicates the autonomous car is an aggressive driver, while another user might think the same signal means the autonomous car is defensive. In this paper we enable robots to adapt their interfaces to the current user so that the human's personalized interpretation is aligned with the robot's meaning. We start with an information theoretic end-to-end approach, which automatically tunes the interface policy to optimize the correlation between human and robot. But to ensure that this learning policy is intuitive -- and to accelerate how quickly the interface adapts to the human -- we recognize that humans have priors over how interfaces should function. For instance, humans expect interface signals to be proportional and convex. Our approach biases the robot's interface towards these priors, resulting in signals that are adapted to the current user while still following social expectations. Our simulations and user study results across $15$ participants suggest that these priors improve robot-to-human communication. See videos here: https://youtu.be/Re3OLg57hp8
Kiri-Spoon: A Soft Shape-Changing Utensil for Robot-Assisted Feeding
Mar 09, 2024



Assistive robot arms have the potential to help disabled or elderly adults eat everyday meals without relying on a caregiver. To provide meaningful assistance, these robots must reach for food items, pick them up, and then carry them to the human's mouth. Current work equips robot arms with standard utensils (e.g., forks and spoons). But -- although these utensils are intuitive for humans -- they are not easy for robots to control. If the robot arm does not carefully and precisely orchestrate its motion, food items may fall out of a spoon or slide off of the fork. Accordingly, in this paper we design, model, and test Kiri-Spoon, a novel utensil specifically intended for robot-assisted feeding. Kiri-Spoon combines the familiar shape of traditional utensils with the capabilities of soft grippers. By actuating a kirigami structure the robot can rapidly adjust the curvature of Kiri-Spoon: at one extreme the utensil wraps around food items to make them easier for the robot to pick up and carry, and at the other extreme the utensil returns to a typical spoon shape so that human users can easily take a bite of food. Our studies with able-bodied human operators suggest that robot arms equipped with Kiri-Spoon carry foods more robustly than when leveraging traditional utensils. See videos here: https://youtu.be/nddAniZLFPk
Surrogate Assisted Generation of Human-Robot Interaction Scenarios
May 11, 2023



As human-robot interaction (HRI) systems advance, so does the difficulty of evaluating and understanding the strengths and limitations of these systems in different environments and with different users. To this end, previous methods have algorithmically generated diverse scenarios that reveal system failures in a shared control teleoperation task. However, these methods require directly evaluating generated scenarios by simulating robot policies and human actions. The computational cost of these evaluations limits their applicability in more complex domains. Thus, we propose augmenting scenario generation systems with surrogate models that predict both human and robot behaviors. In the shared control teleoperation domain and a more complex shared workspace collaboration task, we show that surrogate assisted scenario generation efficiently synthesizes diverse datasets of challenging scenarios. We demonstrate that these failures are reproducible in real-world interactions.
Towards Transferring Human Preferences from Canonical to Actual Assembly Tasks
Nov 11, 2021
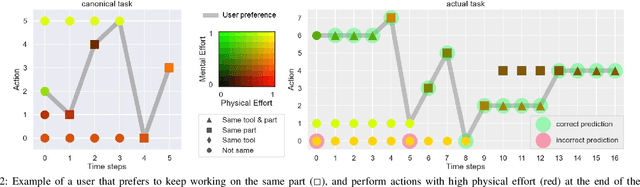
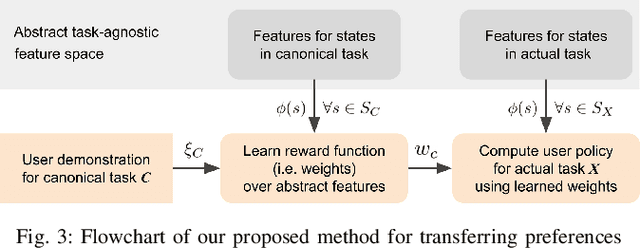
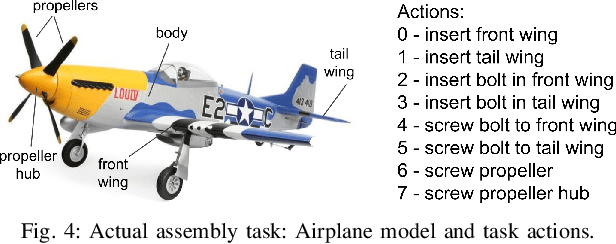
To assist human users according to their individual preference in assembly tasks, robots typically require user demonstrations in the given task. However, providing demonstrations in actual assembly tasks can be tedious and time-consuming. Our thesis is that we can learn user preferences in assembly tasks from demonstrations in a representative canonical task. Inspired by previous work in economy of human movement, we propose to represent user preferences as a linear function of abstract task-agnostic features, such as movement and physical and mental effort required by the user. For each user, we learn their preference from demonstrations in a canonical task and use the learned preference to anticipate their actions in the actual assembly task without any user demonstrations in the actual task. We evaluate our proposed method in a model-airplane assembly study and show that preferences can be effectively transferred from canonical to actual assembly tasks, enabling robots to anticipate user actions.