 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Stage Clustering of Human Preferences for Action Prediction in Assembly Tasks
Mar 27, 2021
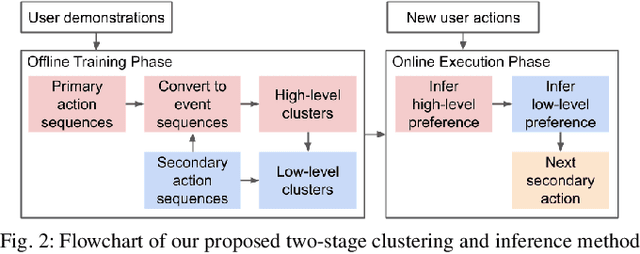
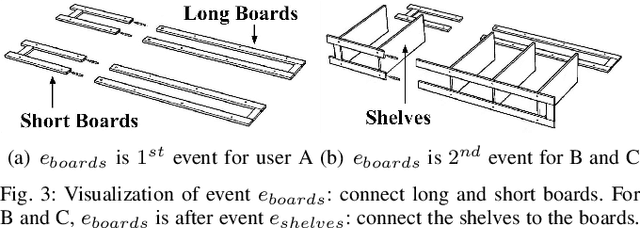

To effectively assist human workers in assembly tasks a robot must proactively offer support by inferring their preferences in sequencing the task actions. Previous work has focused on learning the dominant preferences of human workers for simple tasks largely based on their intended goal. However, people may have preferences at different resolutions: they may share the same high-level preference for the order of the sub-tasks but differ in the sequence of individual actions. We propose a two-stage approach for learning and inferring the preferences of human operators based on the sequence of sub-tasks and actions. We conduct an IKEA assembly study and demonstrate how our approach is able to learn the dominant preferences in a complex task. We show that our approach improves the prediction of human actions through cross-validation. Lastly, we show that our two-stage approach improves the efficiency of task execution in an online experiment, and demonstrate its applicability in a real-world robot-assisted IKEA assembly.
Fair Contextual Multi-Armed Bandits: Theory and Experiments
Dec 13, 2019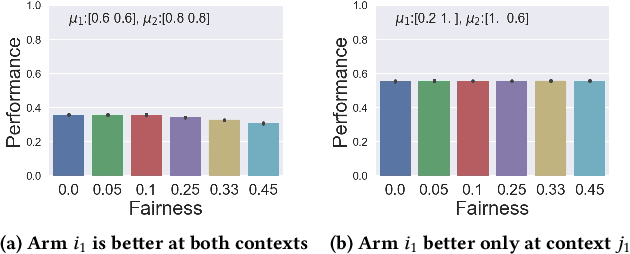
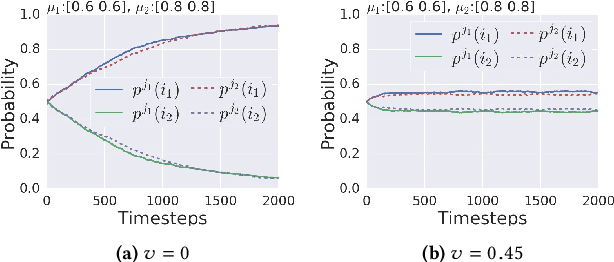
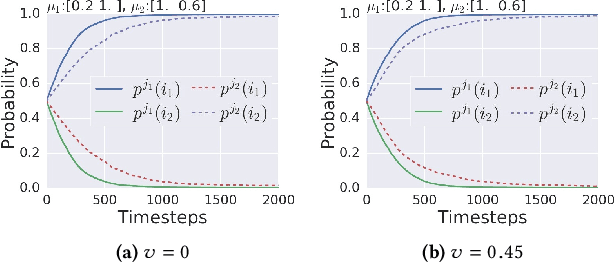
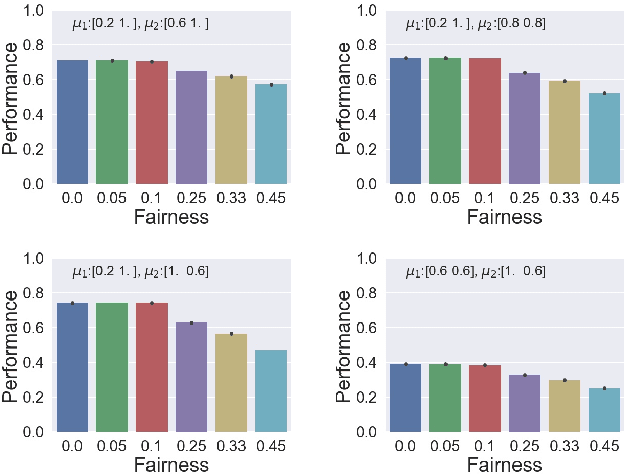
When an AI system interacts with multiple users, it frequently needs to make allocation decisions. For instance, a virtual agent decides whom to pay attention to in a group setting, or a factory robot selects a worker to deliver a part. Demonstrating fairness in decision making is essential for such systems to be broadly accepted. We introduce a Multi-Armed Bandit algorithm with fairness constraints, where fairness is defined as a minimum rate that a task or a resource is assigned to a user. The proposed algorithm uses contextual information about the users and the task and makes no assumptions on how the losses capturing the performance of different users are generated. We provide theoretical guarantees of performance and empirical results from simulation and an online user study. The results highlight the benefit of accounting for contexts in fair decision making, especially when users perform better at some contexts and worse at others.
Reinforcement Learning with Fairness Constraints for Resource Distribution in Human-Robot Teams
Jul 08, 2019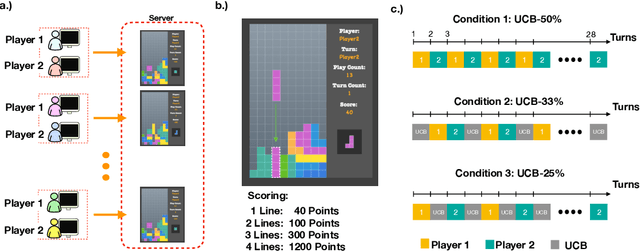

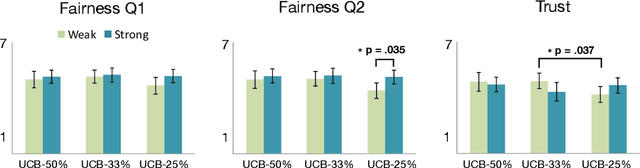
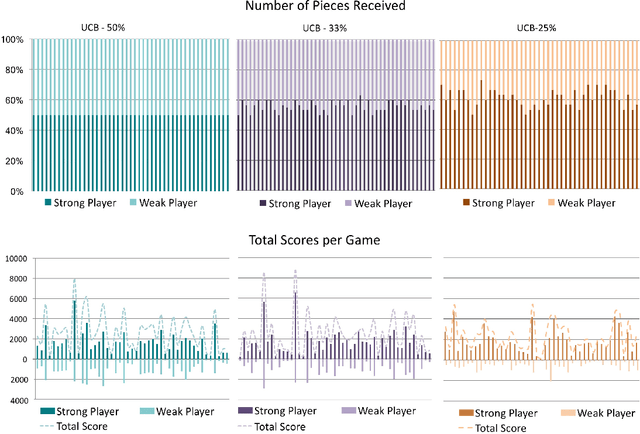
Much work in robotics and operations research has focused on optimal resource distribution, where an agent dynamically decides how to sequentially distribute resources among different candidates. However, most work ignores the notion of fairness in candidate selection. In the case where a robot distributes resources to human team members, disproportionately favoring the highest performing teammate can have negative effects in team dynamics and system acceptance. We introduce a multi-armed bandit algorithm with fairness constraints, where a robot distributes resources to human teammates of different skill levels. In this problem, the robot does not know the skill level of each human teammate, but learns it by observing their performance over time. We define fairness as a constraint on the minimum rate that each human teammate is selected throughout the task. We provide theoretical guarantees on performance and perform a large-scale user study, where we adjust the level of fairness in our algorithm. Results show that fairness in resource distribution has a significant effect on users' trust in the system.