 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerate, Evaluate, Iterate: Synthetic Data for Human-in-the-Loop Refinement of LLM Judges
Nov 06, 2025The LLM-as-a-judge paradigm enables flexible, user-defined evaluation, but its effectiveness is often limited by the scarcity of diverse, representative data for refining criteria. We present a tool that integrates synthetic data generation into the LLM-as-a-judge workflow, empowering users to create tailored and challenging test cases with configurable domains, personas, lengths, and desired outcomes, including borderline cases. The tool also supports AI-assisted inline editing of existing test cases. To enhance transparency and interpretability, it reveals the prompts and explanations behind each generation. In a user study (N=24), 83% of participants preferred the tool over manually creating or selecting test cases, as it allowed them to rapidly generate diverse synthetic data without additional workload. The generated synthetic data proved as effective as hand-crafted data for both refining evaluation criteria and aligning with human preferences. These findings highlight synthetic data as a promising alternative, particularly in contexts where efficiency and scalability are critical.
Granite Guardian
Dec 10, 2024



We introduce the Granite Guardian models, a suite of safeguards designed to provide risk detection for prompts and responses, enabling safe and responsible use in combination with any large language model (LLM). These models offer comprehensive coverage across multiple risk dimensions, including social bias, profanity, violence, sexual content, unethical behavior, jailbreaking, and hallucination-related risks such as context relevance, groundedness, and answer relevance for retrieval-augmented generation (RAG). Trained on a unique dataset combining human annotations from diverse sources and synthetic data, Granite Guardian models address risks typically overlooked by traditional risk detection models, such as jailbreaks and RAG-specific issues. With AUC scores of 0.871 and 0.854 on harmful content and RAG-hallucination-related benchmarks respectively, Granite Guardian is the most generalizable and competitive model available in the space. Released as open-source, Granite Guardian aims to promote responsible AI development across the community. https://github.com/ibm-granite/granite-guardian
Black-box Uncertainty Quantification Method for LLM-as-a-Judge
Oct 15, 2024
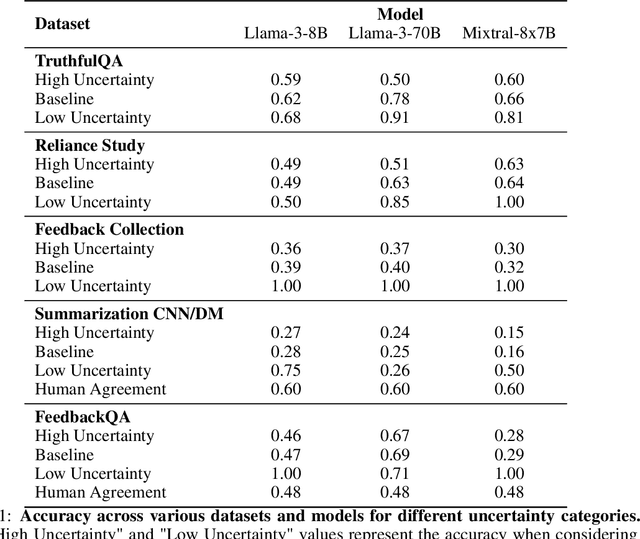
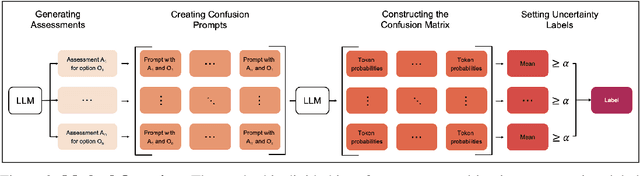

LLM-as-a-Judge is a widely used method for evaluating the performance of Large Language Models (LLMs) across various tasks. We address the challenge of quantifying the uncertainty of LLM-as-a-Judge evaluations. While uncertainty quantification has been well-studied in other domains, applying it effectively to LLMs poses unique challenges due to their complex decision-making capabilities and computational demands. In this paper, we introduce a novel method for quantifying uncertainty designed to enhance the trustworthiness of LLM-as-a-Judge evaluations. The method quantifies uncertainty by analyzing the relationships between generated assessments and possible ratings. By cross-evaluating these relationships and constructing a confusion matrix based on token probabilities, the method derives labels of high or low uncertainty. We evaluate our method across multiple benchmarks, demonstrating a strong correlation between the accuracy of LLM evaluations and the derived uncertainty scores. Our findings suggest that this method can significantly improve the reliability and consistency of LLM-as-a-Judge evaluations.