 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHurwitz Quaternion Multiplicative Quantization for KV Cache Compression
May 26, 2026We propose \textbf{Hurwitz Quaternion Multiplicative Quantization (HQMQ)}, a \textbf{calibration-free} method for KV cache compression of large language models. HQMQ treats each 4-element chunk of K or V as a quaternion and quantizes its unit direction to the \emph{product} $q_p \cdot q_s$, where $q_p$ ranges over the 24-element Hurwitz group $2T$ (the 24 vertices of the 24-cell on $S^3$, pairwise angle $60^\circ$) and $q_s$ ranges over a per-(layer, head) secondary codebook of $S$ \emph{random} unit quaternions. The multiplicative composition yields $24S$ effective codewords at $S$ stored parameters; random initialization suffices because left-multiplication is an $S^3$ isometry, so seeded codebooks vary in end-task ppl by $<1.5\%$. A per-batch median-multiplier outlier extraction step ($C{=}3$, no calibration) handles modern outlier-heavy architectures. We evaluate on five modern open models: Mistral-7B (dense MHA), Llama-3-8B and Qwen2.5-7B and Qwen3-8B (dense GQA), and gpt-oss-20b (sparse MoE). On Mistral-7B and Qwen3-8B, HQMQ matches fp16 within $0.02$--$0.03$ ppl points at $\sim$5 bits. On Qwen2.5-7B and Qwen3-8B, where naive int4 collapses to $10^4{+}$ ppl, HQMQ + Med3$\times$ recovers fp16 quality within $0.02$--$0.10$ ppl points at $\sim$5 bits. HQMQ Pareto-dominates naive int by $3$--$1900\times$ at matched bits across all five models, and downstream zero-shot accuracy matches fp16 at $3.79$ bits on Mistral. Against the strongest calibrated KV-quantization baseline, HQMQ at $3.79$ bits matches KIVI-4 ($\sim 4.5$ bits) within ${\sim}1$ pt on CoQA, $0.6$ pts on TruthfulQA, and $2.3$ pts on GSM8K, at $16\%$ fewer bits and without a calibration pass. At the storage level, HQMQ delivers up to $5.05\times$ KV compression, shrinking a Llama-3-70B 128k-context cache from 43 GB to 8.5 GB.
Tensor Memory: Fixed-Size Recurrent State for Long-Horizon Transformers
May 26, 2026Transformers process images and videos by flattening space and time into long token sequences. While attention and KV caching preserve past features, their memory grows with sequence length and they lack an explicit, persistent spatial state, making long-horizon video understanding and occlusion-sensitive reasoning difficult. We propose Tensor Memory, a lightweight module that augments Transformer blocks with a fixed-size recurrent 3D memory tensor: tokens write into a voxel grid via a differentiable soft write that deposits content as a Gaussian-weighted volume around a predicted continuous 3D location, the memory is updated with an efficient local interaction operator and gated recurrent dynamics, and tokens read back context via continuous sampling with gated residual fusion. Because the memory tensor has a constant size, Tensor Memory decouples state capacity from input length while preserving a spatial inductive bias. We evaluate the module on standard language, image, and video benchmarks and on a controlled toy diagnostic suite designed to isolate when persistent state is beneficial; it integrates with standard Transformer training pipelines and can be attached to or removed from existing blocks without other architectural changes.
POCI-Diff: Position Objects Consistently and Interactively with 3D-Layout Guided Diffusion
Jan 20, 2026We propose a diffusion-based approach for Text-to-Image (T2I) generation with consistent and interactive 3D layout control and editing. While prior methods improve spatial adherence using 2D cues or iterative copy-warp-paste strategies, they often distort object geometry and fail to preserve consistency across edits. To address these limitations, we introduce a framework for Positioning Objects Consistently and Interactively (POCI-Diff), a novel formulation for jointly enforcing 3D geometric constraints and instance-level semantic binding within a unified diffusion process. Our method enables explicit per-object semantic control by binding individual text descriptions to specific 3D bounding boxes through Blended Latent Diffusion, allowing one-shot synthesis of complex multi-object scenes. We further propose a warping-free generative editing pipeline that supports object insertion, removal, and transformation via regeneration rather than pixel deformation. To preserve object identity and consistency across edits, we condition the diffusion process on reference images using IP-Adapter, enabling coherent object appearance throughout interactive 3D editing while maintaining global scene coherence. Experimental results demonstrate that POCI-Diff produces high-quality images consistent with the specified 3D layouts and edits, outperforming state-of-the-art methods in both visual fidelity and layout adherence while eliminating warping-induced geometric artifacts.
Small Models, Smarter Learning: The Power of Joint Task Training
May 23, 2025
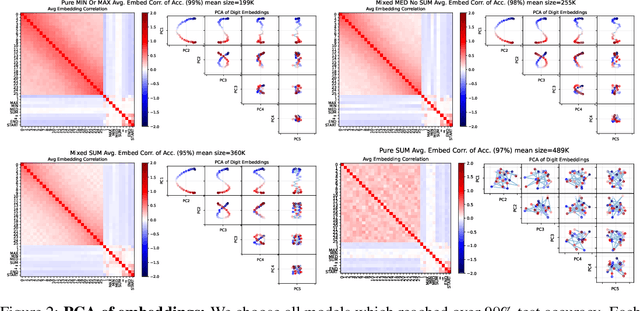
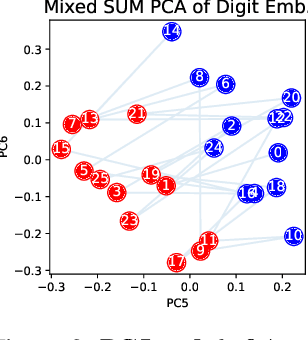

The ability of a model to learn a task depends strongly on both the task difficulty and the model size. We aim to understand how task difficulty relates to the minimum number of parameters required for learning specific tasks in small transformer models. Our study focuses on the ListOps dataset, which consists of nested mathematical operations. We gradually increase task difficulty by introducing new operations or combinations of operations into the training data. We observe that sum modulo n is the hardest to learn. Curiously, when combined with other operations such as maximum and median, the sum operation becomes easier to learn and requires fewer parameters. We show that joint training not only improves performance but also leads to qualitatively different model behavior. We show evidence that models trained only on SUM might be memorizing and fail to capture the number structure in the embeddings. In contrast, models trained on a mixture of SUM and other operations exhibit number-like representations in the embedding space, and a strong ability to distinguish parity. Furthermore, the SUM-only model relies more heavily on its feedforward layers, while the jointly trained model activates the attention mechanism more. Finally, we show that learning pure SUM can be induced in models below the learning threshold of pure SUM, by pretraining them on MAX+MED. Our findings indicate that emergent abilities in language models depend not only on model size, but also the training curriculum.
ESPLoRA: Enhanced Spatial Precision with Low-Rank Adaption in Text-to-Image Diffusion Models for High-Definition Synthesis
Apr 18, 2025



Diffusion models have revolutionized text-to-image (T2I) synthesis, producing high-quality, photorealistic images. However, they still struggle to properly render the spatial relationships described in text prompts. To address the lack of spatial information in T2I generations, existing methods typically use external network conditioning and predefined layouts, resulting in higher computational costs and reduced flexibility. Our approach builds upon a curated dataset of spatially explicit prompts, meticulously extracted and synthesized from LAION-400M to ensure precise alignment between textual descriptions and spatial layouts. Alongside this dataset, we present ESPLoRA, a flexible fine-tuning framework based on Low-Rank Adaptation, specifically designed to enhance spatial consistency in generative models without increasing generation time or compromising the quality of the outputs. In addition to ESPLoRA, we propose refined evaluation metrics grounded in geometric constraints, capturing 3D spatial relations such as \textit{in front of} or \textit{behind}. These metrics also expose spatial biases in T2I models which, even when not fully mitigated, can be strategically exploited by our TORE algorithm to further improve the spatial consistency of generated images. Our method outperforms the current state-of-the-art framework, CoMPaSS, by 13.33% on established spatial consistency benchmarks.
FairyTailor: A Multimodal Generative Framework for Storytelling
Jul 13, 2021
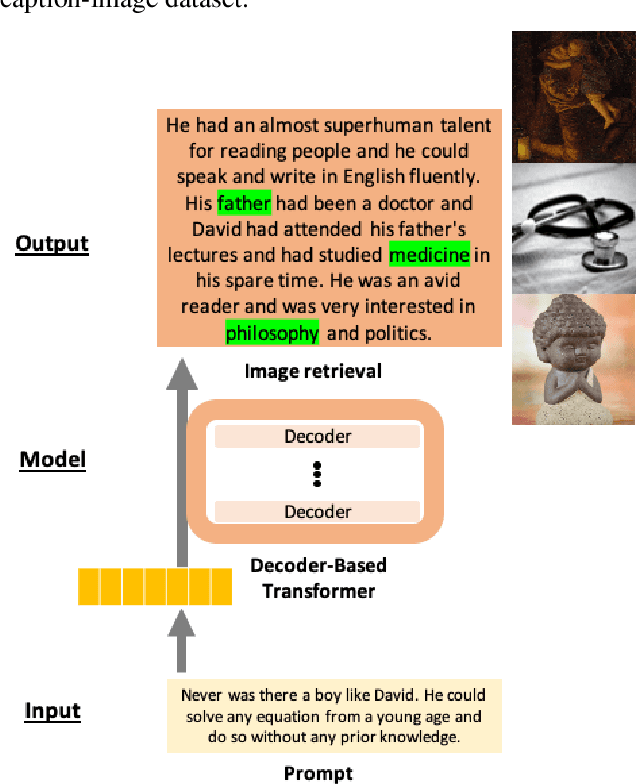

Storytelling is an open-ended task that entails creative thinking and requires a constant flow of ideas. Natural language generation (NLG) for storytelling is especially challenging because it requires the generated text to follow an overall theme while remaining creative and diverse to engage the reader. In this work, we introduce a system and a web-based demo, FairyTailor, for human-in-the-loop visual story co-creation. Users can create a cohesive children's fairytale by weaving generated texts and retrieved images with their input. FairyTailor adds another modality and modifies the text generation process to produce a coherent and creative sequence of text and images. To our knowledge, this is the first dynamic tool for multimodal story generation that allows interactive co-formation of both texts and images. It allows users to give feedback on co-created stories and share their results.
Latent Compass: Creation by Navigation
Dec 20, 2020In Marius von Senden's Space and Sight, a newly sighted blind patient describes the experience of a corner as lemon-like, because corners "prick" sight like lemons prick the tongue. Prickliness, here, is a dimension in the feature space of sensory experience, an effect of the perceived on the perceiver that arises where the two interact. In the account of the newly sighted, an effect familiar from one interaction translates to a novel context. Perception serves as the vehicle for generalization, in that an effect shared across different experiences produces a concrete abstraction grounded in those experiences. Cezanne and the post-impressionists, fluent in the language of experience translation, realized that the way to paint a concrete form that best reflected reality was to paint not what they saw, but what it was like to see. We envision a future of creation using AI where what it is like to see is replicable, transferrable, manipulable - part of the artist's palette that is both grounded in a particular context, and generalizable beyond it. An active line of research maps human-interpretable features onto directions in GAN latent space. Supervised and self-supervised approaches that search for anticipated directions or use off-the-shelf classifiers to drive image manipulation in embedding space are limited in the variety of features they can uncover. Unsupervised approaches that discover useful new directions show that the space of perceptually meaningful directions is nowhere close to being fully mapped. As this space is broad and full of creative potential, we want tools for direction discovery that capture the richness and generalizability of human perception. Our approach puts creators in the discovery loop during real-time tool use, in order to identify directions that are perceptually meaningful to them, and generate interpretable image translations along those directions.
3D Topology Transformation with Generative Adversarial Networks
Jul 07, 2020
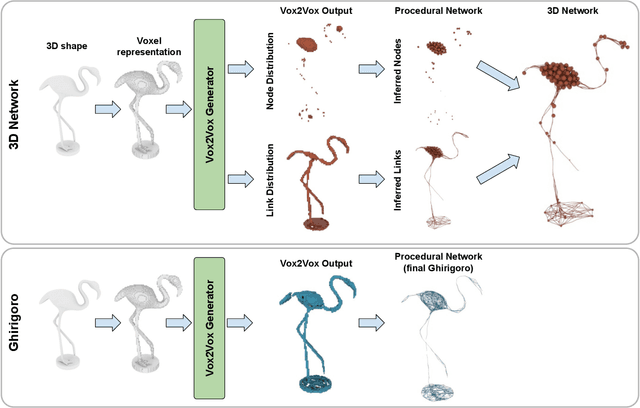

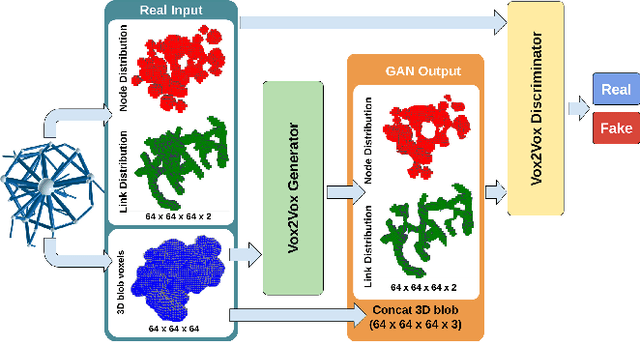
Generation and transformation of images and videos using artificial intelligence have flourished over the past few years. Yet, there are only a few works aiming to produce creative 3D shapes, such as sculptures. Here we show a novel 3D-to-3D topology transformation method using Generative Adversarial Networks (GAN). We use a modified pix2pix GAN, which we call Vox2Vox, to transform the volumetric style of a 3D object while retaining the original object shape. In particular, we show how to transform 3D models into two new volumetric topologies - the 3D Network and the Ghirigoro. We describe how to use our approach to construct customized 3D representations. We believe that the generated 3D shapes are novel and inspirational. Finally, we compare the results between our approach and a baseline algorithm that directly convert the 3D shapes, without using our GAN.
Covering the News with (AI) Style
Jan 05, 2020



We introduce a multi-modal discriminative and generative frame-work capable of assisting humans in producing visual content re-lated to a given theme, starting from a collection of documents(textual, visual, or both). This framework can be used by edit or to generate images for articles, as well as books or music album covers. Motivated by a request from the The New York Times (NYT) seeking help to use AI to create art for their special section on Artificial Intelligence, we demonstrated the application of our system in producing such image.