 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOCI-Diff: Position Objects Consistently and Interactively with 3D-Layout Guided Diffusion
Jan 20, 2026We propose a diffusion-based approach for Text-to-Image (T2I) generation with consistent and interactive 3D layout control and editing. While prior methods improve spatial adherence using 2D cues or iterative copy-warp-paste strategies, they often distort object geometry and fail to preserve consistency across edits. To address these limitations, we introduce a framework for Positioning Objects Consistently and Interactively (POCI-Diff), a novel formulation for jointly enforcing 3D geometric constraints and instance-level semantic binding within a unified diffusion process. Our method enables explicit per-object semantic control by binding individual text descriptions to specific 3D bounding boxes through Blended Latent Diffusion, allowing one-shot synthesis of complex multi-object scenes. We further propose a warping-free generative editing pipeline that supports object insertion, removal, and transformation via regeneration rather than pixel deformation. To preserve object identity and consistency across edits, we condition the diffusion process on reference images using IP-Adapter, enabling coherent object appearance throughout interactive 3D editing while maintaining global scene coherence. Experimental results demonstrate that POCI-Diff produces high-quality images consistent with the specified 3D layouts and edits, outperforming state-of-the-art methods in both visual fidelity and layout adherence while eliminating warping-induced geometric artifacts.
ESPLoRA: Enhanced Spatial Precision with Low-Rank Adaption in Text-to-Image Diffusion Models for High-Definition Synthesis
Apr 18, 2025



Diffusion models have revolutionized text-to-image (T2I) synthesis, producing high-quality, photorealistic images. However, they still struggle to properly render the spatial relationships described in text prompts. To address the lack of spatial information in T2I generations, existing methods typically use external network conditioning and predefined layouts, resulting in higher computational costs and reduced flexibility. Our approach builds upon a curated dataset of spatially explicit prompts, meticulously extracted and synthesized from LAION-400M to ensure precise alignment between textual descriptions and spatial layouts. Alongside this dataset, we present ESPLoRA, a flexible fine-tuning framework based on Low-Rank Adaptation, specifically designed to enhance spatial consistency in generative models without increasing generation time or compromising the quality of the outputs. In addition to ESPLoRA, we propose refined evaluation metrics grounded in geometric constraints, capturing 3D spatial relations such as \textit{in front of} or \textit{behind}. These metrics also expose spatial biases in T2I models which, even when not fully mitigated, can be strategically exploited by our TORE algorithm to further improve the spatial consistency of generated images. Our method outperforms the current state-of-the-art framework, CoMPaSS, by 13.33% on established spatial consistency benchmarks.
3D Topology Transformation with Generative Adversarial Networks
Jul 07, 2020
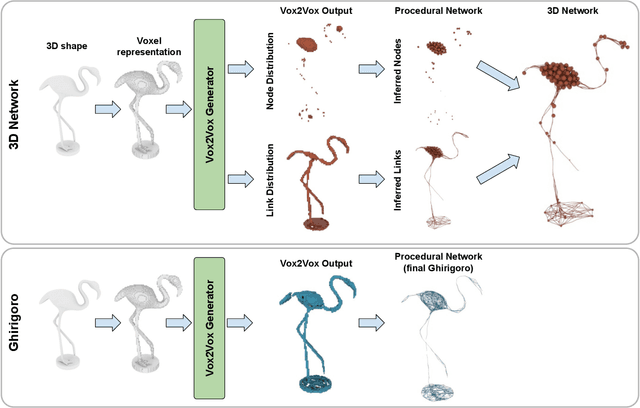

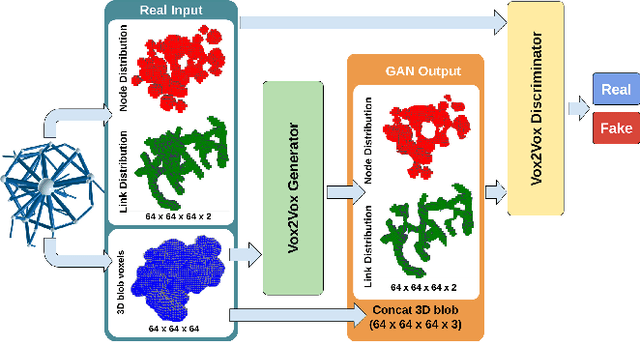
Generation and transformation of images and videos using artificial intelligence have flourished over the past few years. Yet, there are only a few works aiming to produce creative 3D shapes, such as sculptures. Here we show a novel 3D-to-3D topology transformation method using Generative Adversarial Networks (GAN). We use a modified pix2pix GAN, which we call Vox2Vox, to transform the volumetric style of a 3D object while retaining the original object shape. In particular, we show how to transform 3D models into two new volumetric topologies - the 3D Network and the Ghirigoro. We describe how to use our approach to construct customized 3D representations. We believe that the generated 3D shapes are novel and inspirational. Finally, we compare the results between our approach and a baseline algorithm that directly convert the 3D shapes, without using our GAN.