 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovering the News with (AI) Style
Jan 05, 2020



We introduce a multi-modal discriminative and generative frame-work capable of assisting humans in producing visual content re-lated to a given theme, starting from a collection of documents(textual, visual, or both). This framework can be used by edit or to generate images for articles, as well as books or music album covers. Motivated by a request from the The New York Times (NYT) seeking help to use AI to create art for their special section on Artificial Intelligence, we demonstrated the application of our system in producing such image.
A Study on Passage Re-ranking in Embedding based Unsupervised Semantic Search
May 28, 2018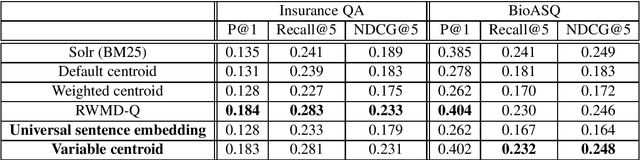
State of the art approaches for (embedding based) unsupervised semantic search exploits either compositional similarity (of a query and a passage) or pair-wise word (or term) similarity (from the query and the passage). By design, word based approaches do not incorporate similarity in the larger context (query/passage), while compositional similarity based approaches are usually unable to take advantage of the most important cues in the context. In this paper we propose a new compositional similarity based approach, called variable centroid vector (VCVB), that tries to address both of these limitations. We also presents results using a different type of compositional similarity based approach by exploiting universal sentence embedding. We provide empirical evaluation on two different benchmarks.
Language Independent Acquisition of Abbreviations
Sep 23, 2017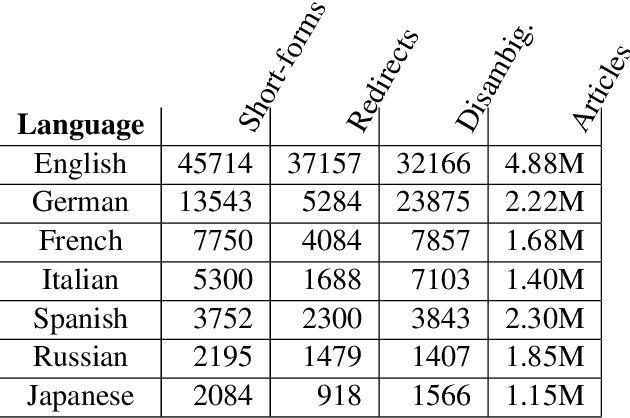
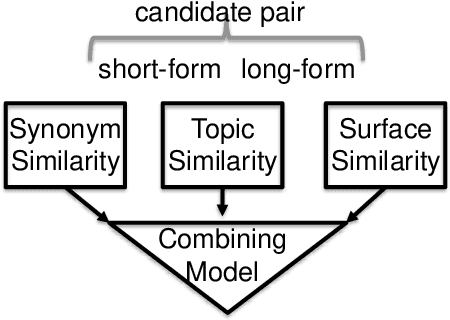
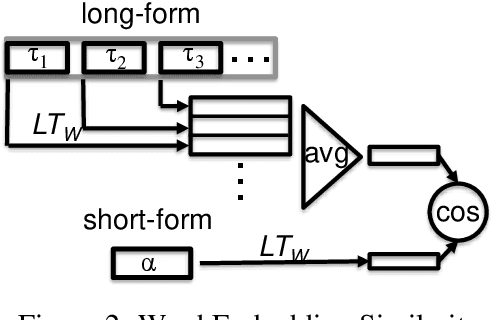
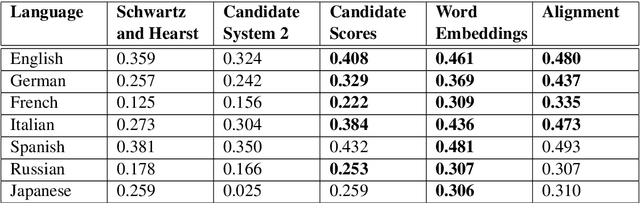
This paper addresses automatic extraction of abbreviations (encompassing acronyms and initialisms) and corresponding long-form expansions from plain unstructured text. We create and are going to release a multilingual resource for abbreviations and their corresponding expansions, built automatically by exploiting Wikipedia redirect and disambiguation pages, that can be used as a benchmark for evaluation. We address a shortcoming of previous work where only the redirect pages were used, and so every abbreviation had only a single expansion, even though multiple different expansions are possible for many of the abbreviations. We also develop a principled machine learning based approach to scoring expansion candidates using different techniques such as indicators of near synonymy, topical relatedness, and surface similarity. We show improved performance over seven languages, including two with a non-Latin alphabet, relative to strong baselines.