 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Independent Acquisition of Abbreviations
Paper and Code
Sep 23, 2017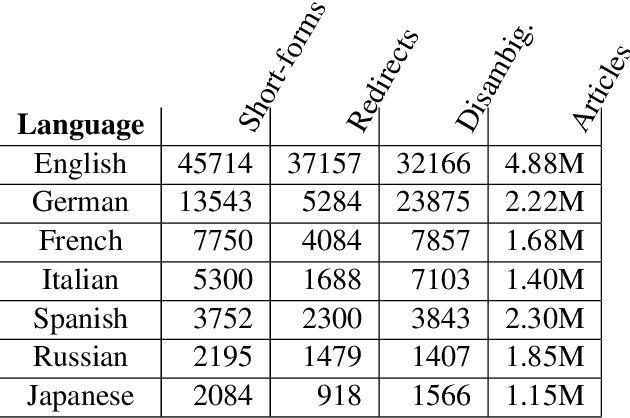
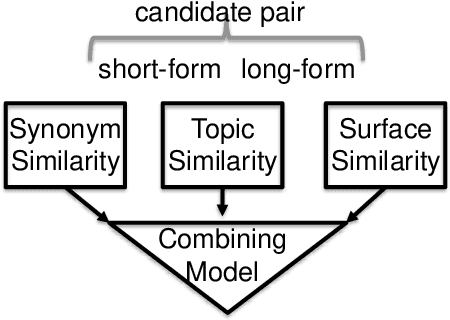
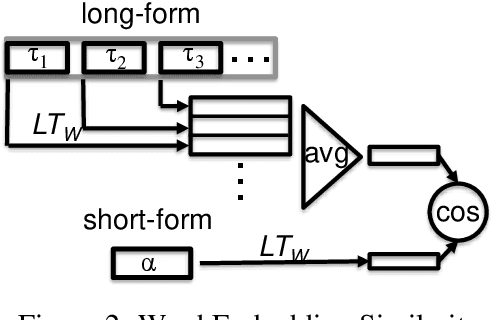
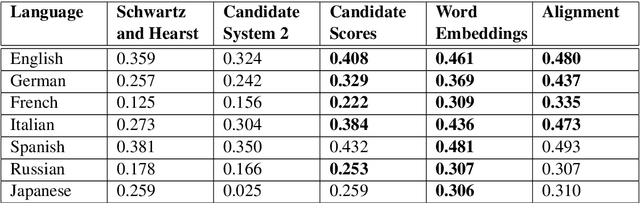
This paper addresses automatic extraction of abbreviations (encompassing acronyms and initialisms) and corresponding long-form expansions from plain unstructured text. We create and are going to release a multilingual resource for abbreviations and their corresponding expansions, built automatically by exploiting Wikipedia redirect and disambiguation pages, that can be used as a benchmark for evaluation. We address a shortcoming of previous work where only the redirect pages were used, and so every abbreviation had only a single expansion, even though multiple different expansions are possible for many of the abbreviations. We also develop a principled machine learning based approach to scoring expansion candidates using different techniques such as indicators of near synonymy, topical relatedness, and surface similarity. We show improved performance over seven languages, including two with a non-Latin alphabet, relative to strong baselines.