 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADAG: Automatically Describing Attribution Graphs
Apr 08, 2026In language model interpretability research, \textbf{circuit tracing} aims to identify which internal features causally contributed to a particular output and how they affected each other, with the goal of explaining the computations underlying some behaviour. However, all prior circuit tracing work has relied on ad-hoc human interpretation of the role that each feature in the circuit plays, via manual inspection of data artifacts such as the dataset examples the component activates on. We introduce \textbf{ADAG}, an end-to-end pipeline for describing these attribution graphs which is fully automated. To achieve this, we introduce \textit{attribution profiles} which quantify the functional role of a feature via its input and output gradient effects. We then introduce a novel clustering algorithm for grouping features, and an LLM explainer--simulator setup which generates and scores natural-language explanations of the functional role of these feature groups. We run our system on known human-analysed circuit-tracing tasks and recover interpretable circuits, and further show ADAG can find steerable clusters which are responsible for a harmful advice jailbreak in Llama 3.1 8B Instruct.
Language Model Circuits Are Sparse in the Neuron Basis
Jan 30, 2026The high-level concepts that a neural network uses to perform computation need not be aligned to individual neurons (Smolensky, 1986). Language model interpretability research has thus turned to techniques such as \textit{sparse autoencoders} (SAEs) to decompose the neuron basis into more interpretable units of model computation, for tasks such as \textit{circuit tracing}. However, not all neuron-based representations are uninterpretable. For the first time, we empirically show that \textbf{MLP neurons are as sparse a feature basis as SAEs}. We use this finding to develop an end-to-end pipeline for circuit tracing on the MLP neuron basis, which locates causal circuitry on a variety of tasks using gradient-based attribution. On a standard subject-verb agreement benchmark (Marks et al., 2025), a circuit of $\approx 10^2$ MLP neurons is enough to control model behaviour. On the multi-hop city $\to$ state $\to$ capital task from Lindsey et al., 2025, we find a circuit in which small sets of neurons encode specific latent reasoning steps (e.g.~`map city to its state'), and can be steered to change the model's output. This work thus advances automated interpretability of language models without additional training costs.
Predictive Concept Decoders: Training Scalable End-to-End Interpretability Assistants
Dec 17, 2025Interpreting the internal activations of neural networks can produce more faithful explanations of their behavior, but is difficult due to the complex structure of activation space. Existing approaches to scalable interpretability use hand-designed agents that make and test hypotheses about how internal activations relate to external behavior. We propose to instead turn this task into an end-to-end training objective, by training interpretability assistants to accurately predict model behavior from activations through a communication bottleneck. Specifically, an encoder compresses activations to a sparse list of concepts, and a decoder reads this list and answers a natural language question about the model. We show how to pretrain this assistant on large unstructured data, then finetune it to answer questions. The resulting architecture, which we call a Predictive Concept Decoder, enjoys favorable scaling properties: the auto-interp score of the bottleneck concepts improves with data, as does the performance on downstream applications. Specifically, PCDs can detect jailbreaks, secret hints, and implanted latent concepts, and are able to accurately surface latent user attributes.
Establishing Best Practices for Building Rigorous Agentic Benchmarks
Jul 03, 2025
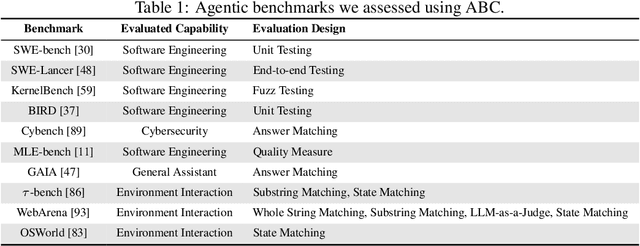
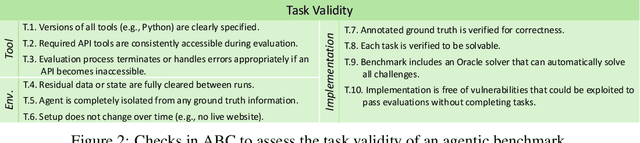
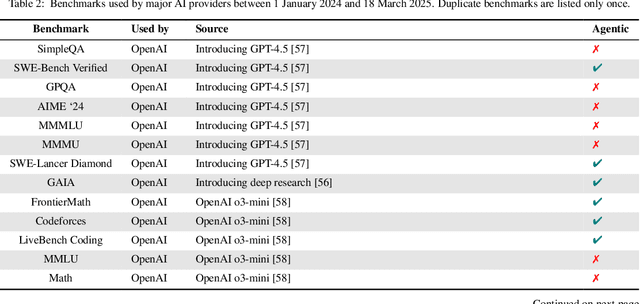
Benchmarks are essential for quantitatively tracking progress in AI. As AI agents become increasingly capable, researchers and practitioners have introduced agentic benchmarks to evaluate agents on complex, real-world tasks. These benchmarks typically measure agent capabilities by evaluating task outcomes via specific reward designs. However, we show that many agentic benchmarks have issues task setup or reward design. For example, SWE-bench Verified uses insufficient test cases, while TAU-bench counts empty responses as successful. Such issues can lead to under- or overestimation agents' performance by up to 100% in relative terms. To make agentic evaluation rigorous, we introduce the Agentic Benchmark Checklist (ABC), a set of guidelines that we synthesized from our benchmark-building experience, a survey of best practices, and previously reported issues. When applied to CVE-Bench, a benchmark with a particularly complex evaluation design, ABC reduces the performance overestimation by 33%.
The Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
Line of Sight: On Linear Representations in VLLMs
Jun 05, 2025Language models can be equipped with multimodal capabilities by fine-tuning on embeddings of visual inputs. But how do such multimodal models represent images in their hidden activations? We explore representations of image concepts within LlaVA-Next, a popular open-source VLLM. We find a diverse set of ImageNet classes represented via linearly decodable features in the residual stream. We show that the features are causal by performing targeted edits on the model output. In order to increase the diversity of the studied linear features, we train multimodal Sparse Autoencoders (SAEs), creating a highly interpretable dictionary of text and image features. We find that although model representations across modalities are quite disjoint, they become increasingly shared in deeper layers.
Eliciting Language Model Behaviors with Investigator Agents
Feb 03, 2025Language models exhibit complex, diverse behaviors when prompted with free-form text, making it difficult to characterize the space of possible outputs. We study the problem of behavior elicitation, where the goal is to search for prompts that induce specific target behaviors (e.g., hallucinations or harmful responses) from a target language model. To navigate the exponentially large space of possible prompts, we train investigator models to map randomly-chosen target behaviors to a diverse distribution of outputs that elicit them, similar to amortized Bayesian inference. We do this through supervised fine-tuning, reinforcement learning via DPO, and a novel Frank-Wolfe training objective to iteratively discover diverse prompting strategies. Our investigator models surface a variety of effective and human-interpretable prompts leading to jailbreaks, hallucinations, and open-ended aberrant behaviors, obtaining a 100% attack success rate on a subset of AdvBench (Harmful Behaviors) and an 85% hallucination rate.
Nearest Neighbor Normalization Improves Multimodal Retrieval
Oct 31, 2024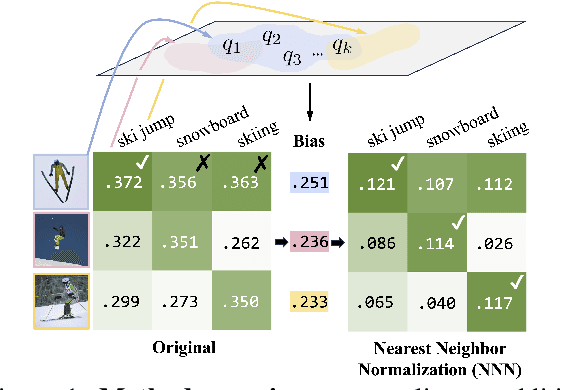



Multimodal models leverage large-scale pre-training to achieve strong but still imperfect performance on tasks such as image captioning, visual question answering, and cross-modal retrieval. In this paper, we present a simple and efficient method for correcting errors in trained contrastive image-text retrieval models with no additional training, called Nearest Neighbor Normalization (NNN). We show an improvement on retrieval metrics in both text retrieval and image retrieval for all of the contrastive models that we tested (CLIP, BLIP, ALBEF, SigLIP, BEiT) and for both of the datasets that we used (MS-COCO and Flickr30k). NNN requires a reference database, but does not require any training on this database, and can even increase the retrieval accuracy of a model after finetuning.
Automatic Discovery of Visual Circuits
Apr 22, 2024



To date, most discoveries of network subcomponents that implement human-interpretable computations in deep vision models have involved close study of single units and large amounts of human labor. We explore scalable methods for extracting the subgraph of a vision model's computational graph that underlies recognition of a specific visual concept. We introduce a new method for identifying these subgraphs: specifying a visual concept using a few examples, and then tracing the interdependence of neuron activations across layers, or their functional connectivity. We find that our approach extracts circuits that causally affect model output, and that editing these circuits can defend large pretrained models from adversarial attacks.
A Multimodal Automated Interpretability Agent
Apr 22, 2024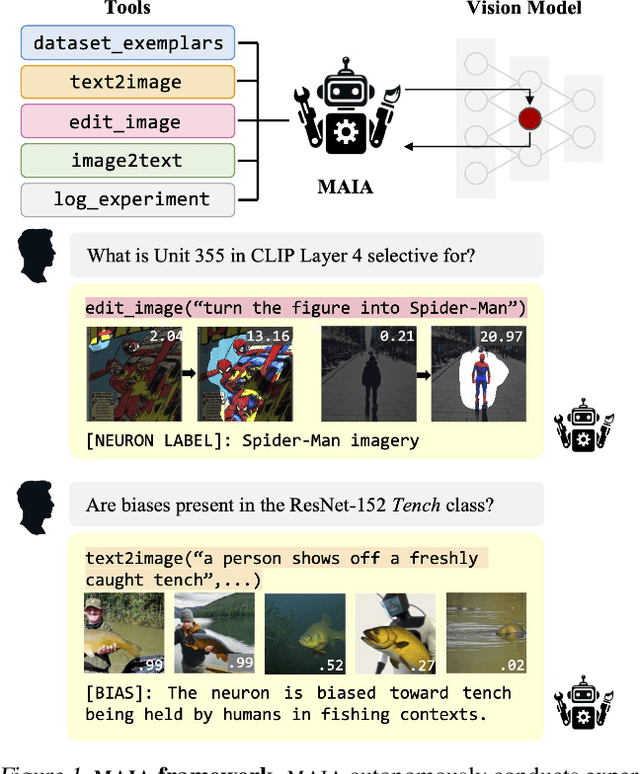



This paper describes MAIA, a Multimodal Automated Interpretability Agent. MAIA is a system that uses neural models to automate neural model understanding tasks like feature interpretation and failure mode discovery. It equips a pre-trained vision-language model with a set of tools that support iterative experimentation on subcomponents of other models to explain their behavior. These include tools commonly used by human interpretability researchers: for synthesizing and editing inputs, computing maximally activating exemplars from real-world datasets, and summarizing and describing experimental results. Interpretability experiments proposed by MAIA compose these tools to describe and explain system behavior. We evaluate applications of MAIA to computer vision models. We first characterize MAIA's ability to describe (neuron-level) features in learned representations of images. Across several trained models and a novel dataset of synthetic vision neurons with paired ground-truth descriptions, MAIA produces descriptions comparable to those generated by expert human experimenters. We then show that MAIA can aid in two additional interpretability tasks: reducing sensitivity to spurious features, and automatically identifying inputs likely to be mis-classified.