 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearest Neighbor Normalization Improves Multimodal Retrieval
Oct 31, 2024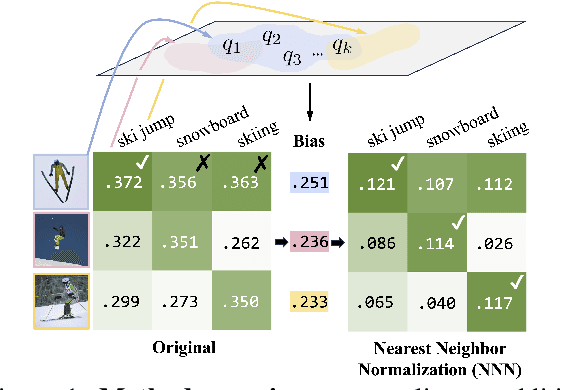



Multimodal models leverage large-scale pre-training to achieve strong but still imperfect performance on tasks such as image captioning, visual question answering, and cross-modal retrieval. In this paper, we present a simple and efficient method for correcting errors in trained contrastive image-text retrieval models with no additional training, called Nearest Neighbor Normalization (NNN). We show an improvement on retrieval metrics in both text retrieval and image retrieval for all of the contrastive models that we tested (CLIP, BLIP, ALBEF, SigLIP, BEiT) and for both of the datasets that we used (MS-COCO and Flickr30k). NNN requires a reference database, but does not require any training on this database, and can even increase the retrieval accuracy of a model after finetuning.
Accelerating Direct Preference Optimization with Prefix Sharing
Oct 27, 2024



Offline paired preference optimization algorithms have become a popular approach for fine-tuning on preference data, outperforming traditional supervised fine-tuning in various tasks. However, traditional implementations often involve redundant computations, especially for tasks with long shared prompts. We introduce prefix sharing for preference tuning, a novel technique that processes chosen and rejected responses as one sequence with a shared prefix. To prevent cross-response contamination, we use a custom block-sparse attention mask. Our method achieves $1.1$-$1.5\times$ improvement in training throughput on popular DPO datasets, without any effect on convergence. When combined with sequence packing, we observe consistent $1.3$-$1.6\times$ speedups, benefiting even datasets with smaller sequence lengths. While we focus on Direct Preference Optimization (DPO), our approach is applicable to other paired preference tuning methods. By enhancing computational efficiency, our work contributes to making preference-based fine-tuning more accessible for a wider range of applications and model sizes. We open-source our code at https://github.com/frankxwang/dpo-prefix-sharing.
A Multimodal Automated Interpretability Agent
Apr 22, 2024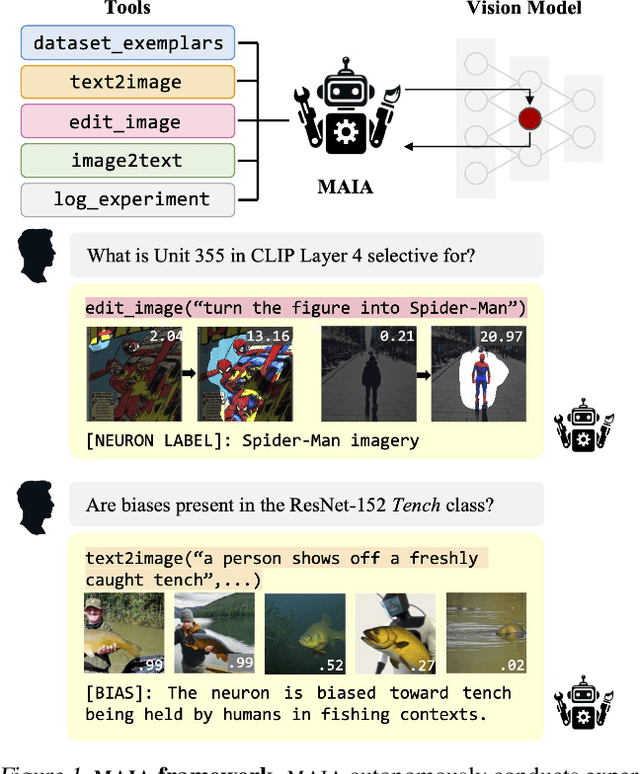



This paper describes MAIA, a Multimodal Automated Interpretability Agent. MAIA is a system that uses neural models to automate neural model understanding tasks like feature interpretation and failure mode discovery. It equips a pre-trained vision-language model with a set of tools that support iterative experimentation on subcomponents of other models to explain their behavior. These include tools commonly used by human interpretability researchers: for synthesizing and editing inputs, computing maximally activating exemplars from real-world datasets, and summarizing and describing experimental results. Interpretability experiments proposed by MAIA compose these tools to describe and explain system behavior. We evaluate applications of MAIA to computer vision models. We first characterize MAIA's ability to describe (neuron-level) features in learned representations of images. Across several trained models and a novel dataset of synthetic vision neurons with paired ground-truth descriptions, MAIA produces descriptions comparable to those generated by expert human experimenters. We then show that MAIA can aid in two additional interpretability tasks: reducing sensitivity to spurious features, and automatically identifying inputs likely to be mis-classified.
Discovering Faint and High Apparent Motion Rate Near-Earth Asteroids Using A Deep Learning Program
Aug 19, 2022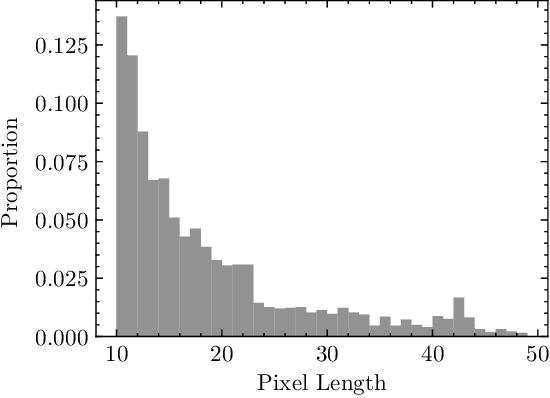

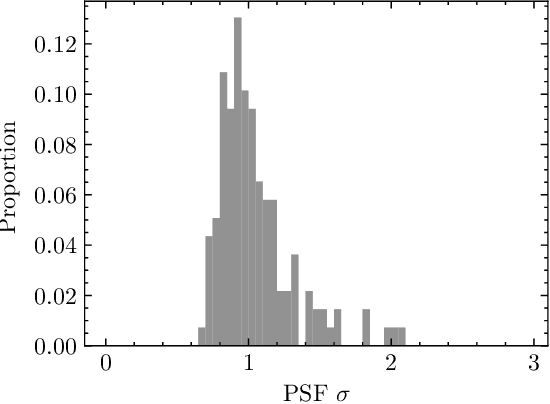

Although many near-Earth objects have been found by ground-based telescopes, some fast-moving ones, especially those near detection limits, have been missed by observatories. We developed a convolutional neural network for detecting faint fast-moving near-Earth objects. It was trained with artificial streaks generated from simulations and was able to find these asteroid streaks with an accuracy of 98.7% and a false positive rate of 0.02% on simulated data. This program was used to search image data from the Zwicky Transient Facility (ZTF) in four nights in 2019, and it identified six previously undiscovered asteroids. The visual magnitudes of our detections range from ~19.0 - 20.3 and motion rates range from ~6.8 - 24 deg/day, which is very faint compared to other ZTF detections moving at similar motion rates. Our asteroids are also ~1 - 51 m diameter in size and ~5 - 60 lunar distances away at close approach, assuming their albedo values follow the albedo distribution function of known asteroids. The use of a purely simulated dataset to train our model enables the program to gain sensitivity in detecting faint and fast-moving objects while still being able to recover nearly all discoveries made by previously designed neural networks which used real detections to train neural networks. Our approach can be adopted by any observatory for detecting fast-moving asteroid streaks.