 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust 2D Convolution for Reliable Visual Recognition
Mar 18, 2022



2D convolution (Conv2d), which is responsible for extracting features from the input image, is one of the key modules of a convolutional neural network (CNN). However, Conv2d is vulnerable to image corruptions and adversarial samples. It is an important yet rarely investigated problem that whether we can design a more robust alternative of Conv2d for more reliable feature extraction. In this paper, inspired by the recently developed learnable sparse transform that learns to convert the CNN features into a compact and sparse latent space, we design a novel building block, denoted by RConv-MK, to strengthen the robustness of extracted convolutional features. Our method leverages a set of learnable kernels of different sizes to extract features at different frequencies and employs a normalized soft thresholding operator to adaptively remove noises and trivial features at different corruption levels. Extensive experiments on clean images, corrupted images as well as adversarial samples validate the effectiveness of the proposed robust module for reliable visual recognition. The source codes are enclosed in the submission.
Spatial Feature Calibration and Temporal Fusion for Effective One-stage Video Instance Segmentation
Apr 06, 2021
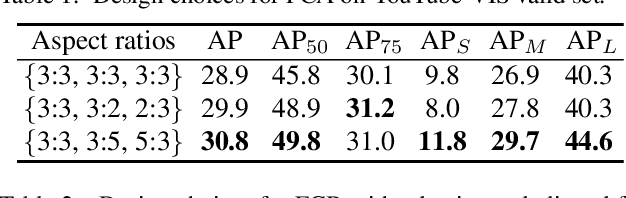


Modern one-stage video instance segmentation networks suffer from two limitations. First, convolutional features are neither aligned with anchor boxes nor with ground-truth bounding boxes, reducing the mask sensitivity to spatial location. Second, a video is directly divided into individual frames for frame-level instance segmentation, ignoring the temporal correlation between adjacent frames. To address these issues, we propose a simple yet effective one-stage video instance segmentation framework by spatial calibration and temporal fusion, namely STMask. To ensure spatial feature calibration with ground-truth bounding boxes, we first predict regressed bounding boxes around ground-truth bounding boxes, and extract features from them for frame-level instance segmentation. To further explore temporal correlation among video frames, we aggregate a temporal fusion module to infer instance masks from each frame to its adjacent frames, which helps our framework to handle challenging videos such as motion blur, partial occlusion and unusual object-to-camera poses. Experiments on the YouTube-VIS valid set show that the proposed STMask with ResNet-50/-101 backbone obtains 33.5 % / 36.8 % mask AP, while achieving 28.6 / 23.4 FPS on video instance segmentation. The code is released online https://github.com/MinghanLi/STMask.
Learning Image-adaptive 3D Lookup Tables for High Performance Photo Enhancement in Real-time
Sep 30, 2020



Recent years have witnessed the increasing popularity of learning based methods to enhance the color and tone of photos. However, many existing photo enhancement methods either deliver unsatisfactory results or consume too much computational and memory resources, hindering their application to high-resolution images (usually with more than 12 megapixels) in practice. In this paper, we learn image-adaptive 3-dimensional lookup tables (3D LUTs) to achieve fast and robust photo enhancement. 3D LUTs are widely used for manipulating color and tone of photos, but they are usually manually tuned and fixed in camera imaging pipeline or photo editing tools. We, for the first time to our best knowledge, propose to learn 3D LUTs from annotated data using pairwise or unpaired learning. More importantly, our learned 3D LUT is image-adaptive for flexible photo enhancement. We learn multiple basis 3D LUTs and a small convolutional neural network (CNN) simultaneously in an end-to-end manner. The small CNN works on the down-sampled version of the input image to predict content-dependent weights to fuse the multiple basis 3D LUTs into an image-adaptive one, which is employed to transform the color and tone of source images efficiently. Our model contains less than 600K parameters and takes less than 2 ms to process an image of 4K resolution using one Titan RTX GPU. While being highly efficient, our model also outperforms the state-of-the-art photo enhancement methods by a large margin in terms of PSNR, SSIM and a color difference metric on two publically available benchmark datasets.
Grid Anchor based Image Cropping: A New Benchmark and An Efficient Model
Sep 18, 2019



Image cropping aims to improve the composition as well as aesthetic quality of an image by removing extraneous content from it. Most of the existing image cropping databases provide only one or several human-annotated bounding boxes as the groundtruths, which can hardly reflect the non-uniqueness and flexibility of image cropping in practice. The employed evaluation metrics such as intersection-over-union cannot reliably reflect the real performance of a cropping model, either. This work revisits the problem of image cropping, and presents a grid anchor based formulation by considering the special properties and requirements (e.g., local redundancy, content preservation, aspect ratio) of image cropping. Our formulation reduces the searching space of candidate crops from millions to no more than ninety. Consequently, a grid anchor based cropping benchmark is constructed, where all crops of each image are annotated and more reliable evaluation metrics are defined. To meet the practical demands of robust performance and high efficiency, we also design an effective and lightweight cropping model. By simultaneously considering the region of interest and region of discard, and leveraging multi-scale information, our model can robustly output visually pleasing crops for images of different scenes. With less than 2.5M parameters, our model runs at a speed of 200 FPS on one single GTX 1080Ti GPU and 12 FPS on one i7-6800K CPU. The code is available at: \url{https://github.com/HuiZeng/Grid-Anchor-based-Image-Cropping-Pytorch}.
Reliable and Efficient Image Cropping: A Grid Anchor based Approach
Apr 09, 2019



Image cropping aims to improve the composition as well as aesthetic quality of an image by removing extraneous content from it. Existing image cropping databases provide only one or several human-annotated bounding boxes as the groundtruth, which cannot reflect the non-uniqueness and flexibility of image cropping in practice. The employed evaluation metrics such as intersection-over-union cannot reliably reflect the real performance of cropping models, either. This work revisits the problem of image cropping, and presents a grid anchor based formulation by considering the special properties and requirements (e.g., local redundancy, content preservation, aspect ratio) of image cropping. Our formulation reduces the searching space of candidate crops from millions to less than one hundred. Consequently, a grid anchor based cropping benchmark is constructed, where all crops of each image are annotated and more reliable evaluation metrics are defined. We also design an effective and lightweight network module, which simultaneously considers the region of interest and region of discard for more accurate image cropping. Our model can stably output visually pleasing crops for images of different scenes and run at a speed of 125 FPS. Code and dataset are available at: https://github.com/HuiZeng/Grid-Anchor-based-Image-Cropping.