 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdsourcing with Meta-Workers: A New Way to Save the Budget
Paper and Code
Nov 07, 2021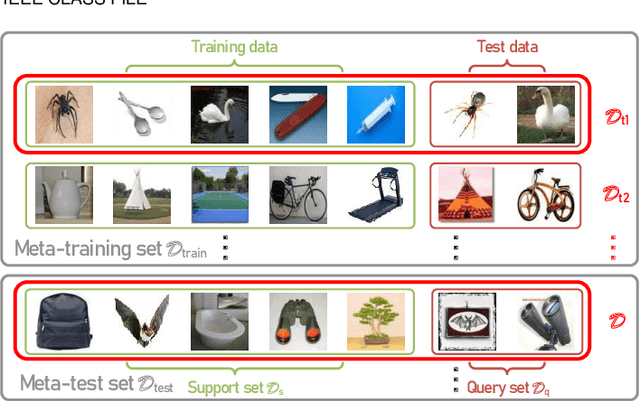
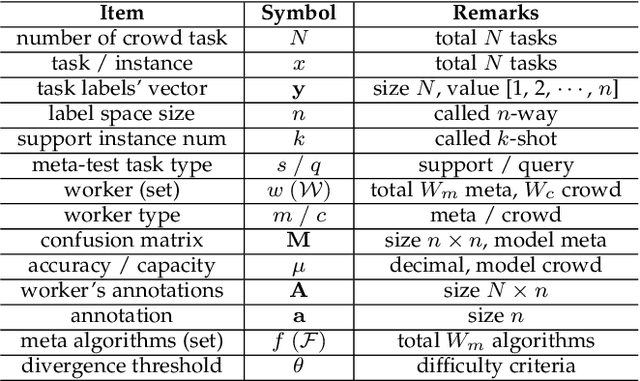
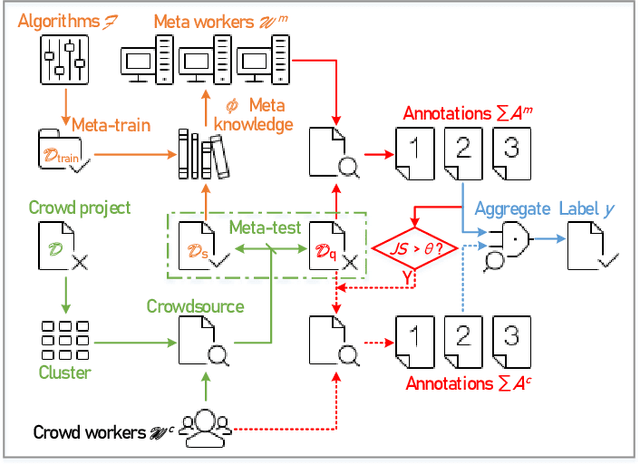

Due to the unreliability of Internet workers, it's difficult to complete a crowdsourcing project satisfactorily, especially when the tasks are multiple and the budget is limited. Recently, meta learning has brought new vitality to few-shot learning, making it possible to obtain a classifier with a fair performance using only a few training samples. Here we introduce the concept of \emph{meta-worker}, a machine annotator trained by meta learning for types of tasks (i.e., image classification) that are well-fit for AI. Unlike regular crowd workers, meta-workers can be reliable, stable, and more importantly, tireless and free. We first cluster unlabeled data and ask crowd workers to repeatedly annotate the instances nearby the cluster centers; we then leverage the annotated data and meta-training datasets to build a cluster of meta-workers using different meta learning algorithms. Subsequently, meta-workers are asked to annotate the remaining crowdsourced tasks. The Jensen-Shannon divergence is used to measure the disagreement among the annotations provided by the meta-workers, which determines whether or not crowd workers should be invited for further annotation of the same task. Finally, we model meta-workers' preferences and compute the consensus annotation by weighted majority voting. Our empirical study confirms that, by combining machine and human intelligence, we can accomplish a crowdsourcing project with a lower budget than state-of-the-art task assignment methods, while achieving a superior or comparable quality.