 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentence Bag Graph Formulation for Biomedical Distant Supervision Relation Extraction
Oct 29, 2023



We introduce a novel graph-based framework for alleviating key challenges in distantly-supervised relation extraction and demonstrate its effectiveness in the challenging and important domain of biomedical data. Specifically, we propose a graph view of sentence bags referring to an entity pair, which enables message-passing based aggregation of information related to the entity pair over the sentence bag. The proposed framework alleviates the common problem of noisy labeling in distantly supervised relation extraction and also effectively incorporates inter-dependencies between sentences within a bag. Extensive experiments on two large-scale biomedical relation datasets and the widely utilized NYT dataset demonstrate that our proposed framework significantly outperforms the state-of-the-art methods for biomedical distant supervision relation extraction while also providing excellent performance for relation extraction in the general text mining domain.
Reinforcement Causal Structure Learning on Order Graph
Nov 22, 2022



Learning directed acyclic graph (DAG) that describes the causality of observed data is a very challenging but important task. Due to the limited quantity and quality of observed data, and non-identifiability of causal graph, it is almost impossible to infer a single precise DAG. Some methods approximate the posterior distribution of DAGs to explore the DAG space via Markov chain Monte Carlo (MCMC), but the DAG space is over the nature of super-exponential growth, accurately characterizing the whole distribution over DAGs is very intractable. In this paper, we propose {Reinforcement Causal Structure Learning on Order Graph} (RCL-OG) that uses order graph instead of MCMC to model different DAG topological orderings and to reduce the problem size. RCL-OG first defines reinforcement learning with a new reward mechanism to approximate the posterior distribution of orderings in an efficacy way, and uses deep Q-learning to update and transfer rewards between nodes. Next, it obtains the probability transition model of nodes on order graph, and computes the posterior probability of different orderings. In this way, we can sample on this model to obtain the ordering with high probability. Experiments on synthetic and benchmark datasets show that RCL-OG provides accurate posterior probability approximation and achieves better results than competitive causal discovery algorithms.
MetaMIML: Meta Multi-Instance Multi-Label Learning
Nov 07, 2021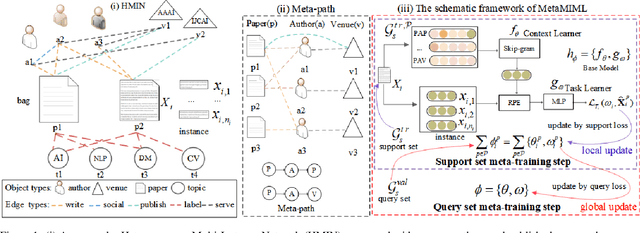
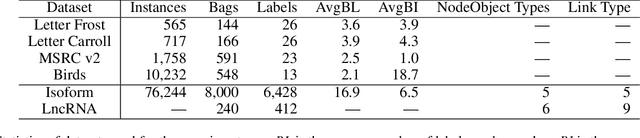
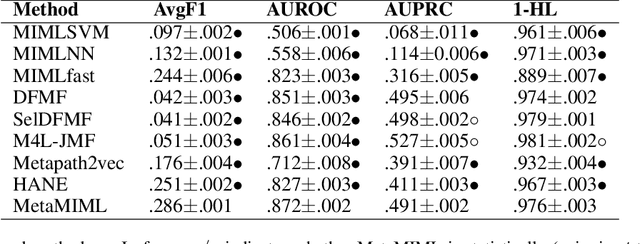

Multi-Instance Multi-Label learning (MIML) models complex objects (bags), each of which is associated with a set of interrelated labels and composed with a set of instances. Current MIML solutions still focus on a single-type of objects and assumes an IID distribution of training data. But these objects are linked with objects of other types, %(i.e., pictures in Facebook link with various users), which also encode the semantics of target objects. In addition, they generally need abundant labeled data for training. To effectively mine interdependent MIML objects of different types, we propose a network embedding and meta learning based approach (MetaMIML). MetaMIML introduces the context learner with network embedding to capture semantic information of objects of different types, and the task learner to extract the meta knowledge for fast adapting to new tasks. In this way, MetaMIML can naturally deal with MIML objects at data level improving, but also exploit the power of meta-learning at the model enhancing. Experiments on benchmark datasets demonstrate that MetaMIML achieves a significantly better performance than state-of-the-art algorithms.
Distantly-Supervised Long-Tailed Relation Extraction Using Constraint Graphs
May 29, 2021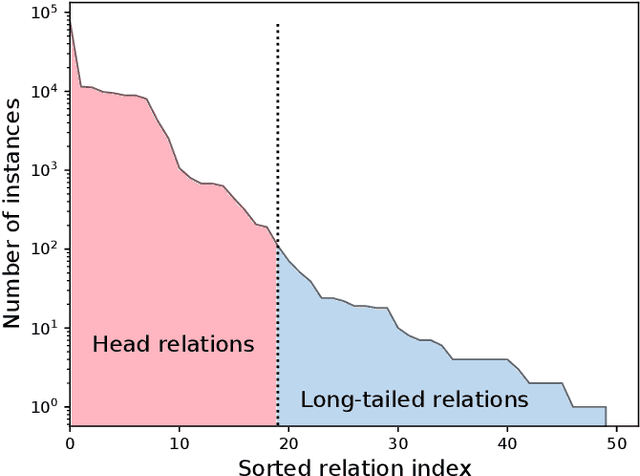

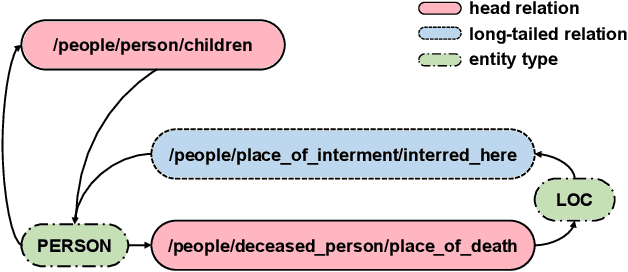
Label noise and long-tailed distributions are two major challenges in distantly supervised relation extraction. Recent studies have shown great progress on denoising, but pay little attention to the problem of long-tailed relations. In this paper, we introduce constraint graphs to model the dependencies between relation labels. On top of that, we further propose a novel constraint graph-based relation extraction framework(CGRE) to handle the two challenges simultaneously. CGRE employs graph convolution networks (GCNs) to propagate information from data-rich relation nodes to data-poor relation nodes, and thus boosts the representation learning of long-tailed relations. To further improve the noise immunity, a constraint-aware attention module is designed in CGRE to integrate the constraint information. Experimental results on a widely-used benchmark dataset indicate that our approach achieves significant improvements over the previous methods for both denoising and long-tailed relation extraction.
Neighbor Embedding Variational Autoencoder
Mar 21, 2021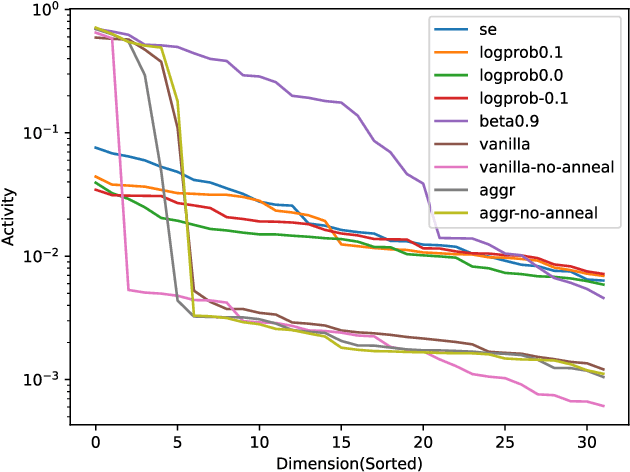
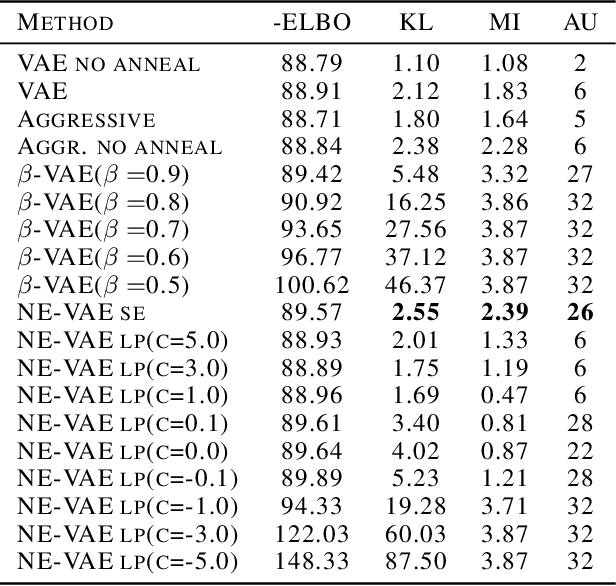
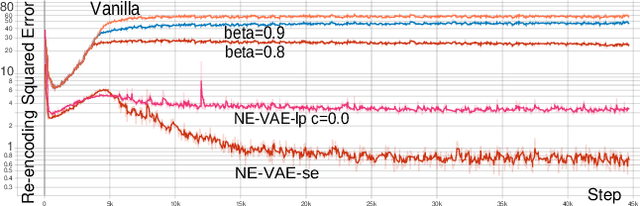
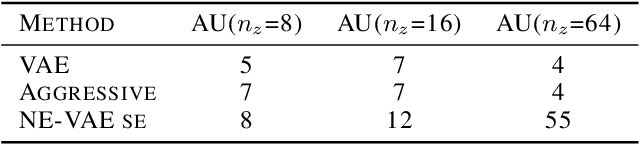
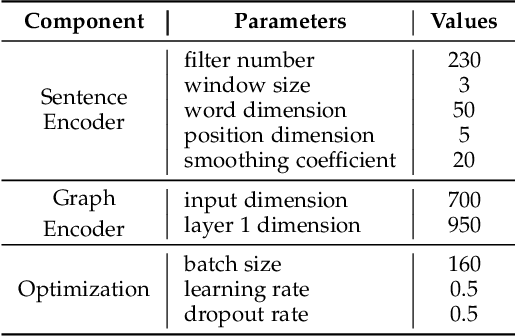
Being one of the most popular generative framework, variational autoencoders(VAE) are known to suffer from a phenomenon termed posterior collapse, i.e. the latent variational distributions collapse to the prior, especially when a strong decoder network is used. In this work, we analyze the latent representation of collapsed VAEs, and proposed a novel model, neighbor embedding VAE(NE-VAE), which explicitly constraints the encoder to encode inputs close in the input space to be close in the latent space. We observed that for VAE variants that report similar ELBO, KL divergence or even mutual information scores may still behave quite differently in the latent organization. In our experiments, NE-VAE can produce qualitatively different latent representations with majority of the latent dimensions remained active, which may benefit downstream latent space optimization tasks. NE-VAE can prevent posterior collapse to a much greater extent than it's predecessors, and can be easily plugged into any autoencoder framework, without introducing addition model components and complex training routines.
Partial Multi-label Learning with Label and Feature Collaboration
Mar 17, 2020
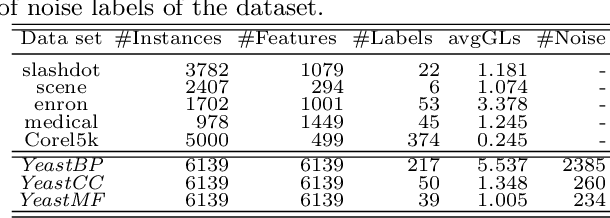
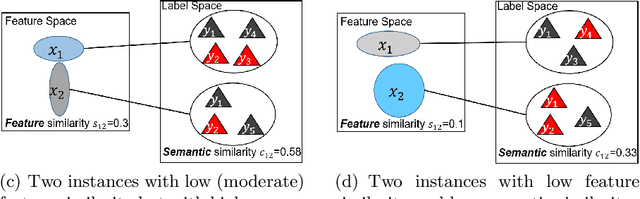
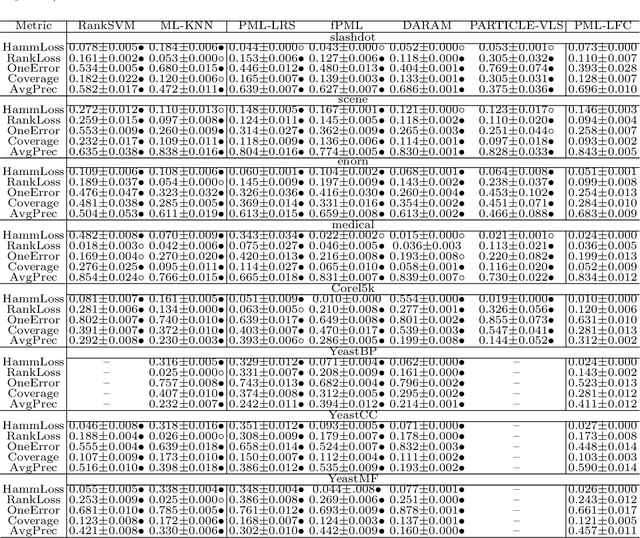
Partial multi-label learning (PML) models the scenario where each training instance is annotated with a set of candidate labels, and only some of the labels are relevant. The PML problem is practical in real-world scenarios, as it is difficult and even impossible to obtain precisely labeled samples. Several PML solutions have been proposed to combat with the prone misled by the irrelevant labels concealed in the candidate labels, but they generally focus on the smoothness assumption in feature space or low-rank assumption in label space, while ignore the negative information between features and labels. Specifically, if two instances have largely overlapped candidate labels, irrespective of their feature similarity, their ground-truth labels should be similar; while if they are dissimilar in the feature and candidate label space, their ground-truth labels should be dissimilar with each other. To achieve a credible predictor on PML data, we propose a novel approach called PML-LFC (Partial Multi-label Learning with Label and Feature Collaboration). PML-LFC estimates the confidence values of relevant labels for each instance using the similarity from both the label and feature spaces, and trains the desired predictor with the estimated confidence values. PML-LFC achieves the predictor and the latent label matrix in a reciprocal reinforce manner by a unified model, and develops an alternative optimization procedure to optimize them. Extensive empirical study on both synthetic and real-world datasets demonstrates the superiority of PML-LFC.
Multi-View Multi-Instance Multi-Label Learning based on Collaborative Matrix Factorization
May 15, 2019

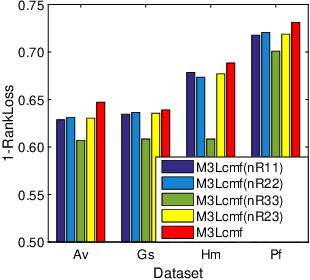
Multi-view Multi-instance Multi-label Learning(M3L) deals with complex objects encompassing diverse instances, represented with different feature views, and annotated with multiple labels. Existing M3L solutions only partially explore the inter or intra relations between objects (or bags), instances, and labels, which can convey important contextual information for M3L. As such, they may have a compromised performance. In this paper, we propose a collaborative matrix factorization based solution called M3Lcmf. M3Lcmf first uses a heterogeneous network composed of nodes of bags, instances, and labels, to encode different types of relations via multiple relational data matrices. To preserve the intrinsic structure of the data matrices, M3Lcmf collaboratively factorizes them into low-rank matrices, explores the latent relationships between bags, instances, and labels, and selectively merges the data matrices. An aggregation scheme is further introduced to aggregate the instance-level labels into bag-level and to guide the factorization. An empirical study on benchmark datasets show that M3Lcmf outperforms other related competitive solutions both in the instance-level and bag-level prediction.
Ranking-based Deep Cross-modal Hashing
May 11, 2019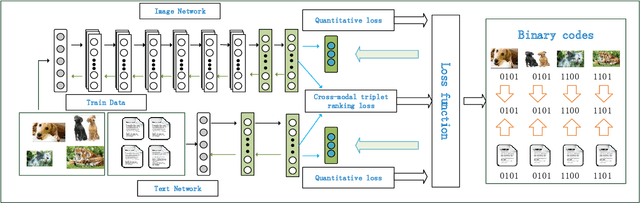
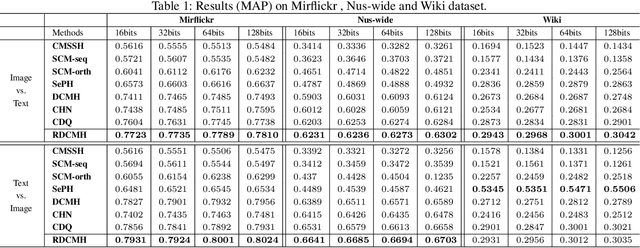


Cross-modal hashing has been receiving increasing interests for its low storage cost and fast query speed in multi-modal data retrievals. However, most existing hashing methods are based on hand-crafted or raw level features of objects, which may not be optimally compatible with the coding process. Besides, these hashing methods are mainly designed to handle simple pairwise similarity. The complex multilevel ranking semantic structure of instances associated with multiple labels has not been well explored yet. In this paper, we propose a ranking-based deep cross-modal hashing approach (RDCMH). RDCMH firstly uses the feature and label information of data to derive a semi-supervised semantic ranking list. Next, to expand the semantic representation power of hand-crafted features, RDCMH integrates the semantic ranking information into deep cross-modal hashing and jointly optimizes the compatible parameters of deep feature representations and of hashing functions. Experiments on real multi-modal datasets show that RDCMH outperforms other competitive baselines and achieves the state-of-the-art performance in cross-modal retrieval applications.
Multiple Independent Subspace Clusterings
May 10, 2019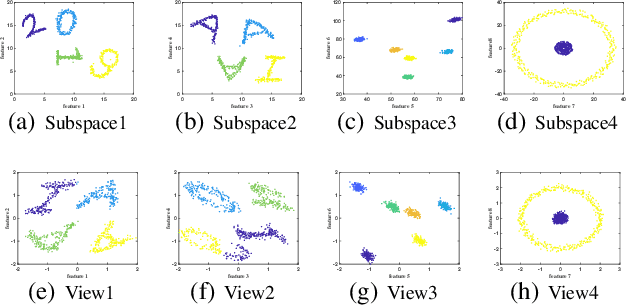



Multiple clustering aims at discovering diverse ways of organizing data into clusters. Despite the progress made, it's still a challenge for users to analyze and understand the distinctive structure of each output clustering. To ease this process, we consider diverse clusterings embedded in different subspaces, and analyze the embedding subspaces to shed light into the structure of each clustering. To this end, we provide a two-stage approach called MISC (Multiple Independent Subspace Clusterings). In the first stage, MISC uses independent subspace analysis to seek multiple and statistical independent (i.e. non-redundant) subspaces, and determines the number of subspaces via the minimum description length principle. In the second stage, to account for the intrinsic geometric structure of samples embedded in each subspace, MISC performs graph regularized semi-nonnegative matrix factorization to explore clusters. It additionally integrates the kernel trick into matrix factorization to handle non-linearly separable clusters. Experimental results on synthetic datasets show that MISC can find different interesting clusterings from the sought independent subspaces, and it also outperforms other related and competitive approaches on real-world datasets.