 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-modal Zero-shot Hashing
Aug 19, 2019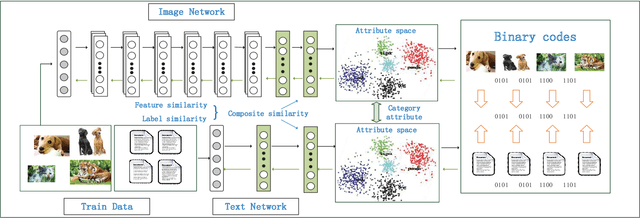



Hashing has been widely studied for big data retrieval due to its low storage cost and fast query speed. Zero-shot hashing (ZSH) aims to learn a hashing model that is trained using only samples from seen categories, but can generalize well to samples of unseen categories. ZSH generally uses category attributes to seek a semantic embedding space to transfer knowledge from seen categories to unseen ones. As a result, it may perform poorly when labeled data are insufficient. ZSH methods are mainly designed for single-modality data, which prevents their application to the widely spread multi-modal data. On the other hand, existing cross-modal hashing solutions assume that all the modalities share the same category labels, while in practice the labels of different data modalities may be different. To address these issues, we propose a general Cross-modal Zero-shot Hashing (CZHash) solution to effectively leverage unlabeled and labeled multi-modality data with different label spaces. CZHash first quantifies the composite similarity between instances using label and feature information. It then defines an objective function to achieve deep feature learning compatible with the composite similarity preserving, category attribute space learning, and hashing coding function learning. CZHash further introduces an alternative optimization procedure to jointly optimize these learning objectives. Experiments on benchmark multi-modal datasets show that CZHash significantly outperforms related representative hashing approaches both on effectiveness and adaptability.
Weakly-paired Cross-Modal Hashing
May 29, 2019



Hashing has been widely adopted for large-scale data retrieval in many domains, due to its low storage cost and high retrieval speed. Existing cross-modal hashing methods optimistically assume that the correspondence between training samples across modalities are readily available. This assumption is unrealistic in practical applications. In addition, these methods generally require the same number of samples across different modalities, which restricts their flexibility. We propose a flexible cross-modal hashing approach (Flex-CMH) to learn effective hashing codes from weakly-paired data, whose correspondence across modalities are partially (or even totally) unknown. FlexCMH first introduces a clustering-based matching strategy to explore the local structure of each cluster, and thus to find the potential correspondence between clusters (and samples therein) across modalities. To reduce the impact of an incomplete correspondence, it jointly optimizes in a unified objective function the potential correspondence, the cross-modal hashing functions derived from the correspondence, and a hashing quantitative loss. An alternative optimization technique is also proposed to coordinate the correspondence and hash functions, and to reinforce the reciprocal effects of the two objectives. Experiments on publicly multi-modal datasets show that FlexCMH achieves significantly better results than state-of-the-art methods, and it indeed offers a high degree of flexibility for practical cross-modal hashing tasks.
Ranking-based Deep Cross-modal Hashing
May 11, 2019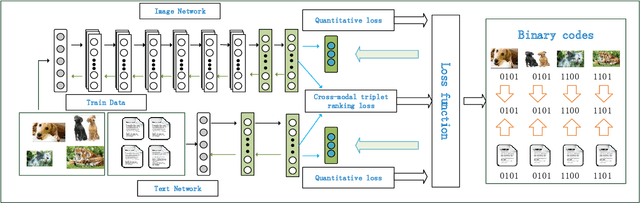
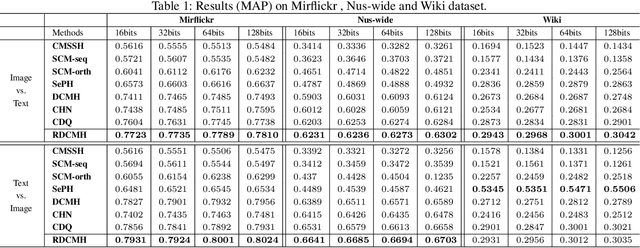


Cross-modal hashing has been receiving increasing interests for its low storage cost and fast query speed in multi-modal data retrievals. However, most existing hashing methods are based on hand-crafted or raw level features of objects, which may not be optimally compatible with the coding process. Besides, these hashing methods are mainly designed to handle simple pairwise similarity. The complex multilevel ranking semantic structure of instances associated with multiple labels has not been well explored yet. In this paper, we propose a ranking-based deep cross-modal hashing approach (RDCMH). RDCMH firstly uses the feature and label information of data to derive a semi-supervised semantic ranking list. Next, to expand the semantic representation power of hand-crafted features, RDCMH integrates the semantic ranking information into deep cross-modal hashing and jointly optimizes the compatible parameters of deep feature representations and of hashing functions. Experiments on real multi-modal datasets show that RDCMH outperforms other competitive baselines and achieves the state-of-the-art performance in cross-modal retrieval applications.