 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset for measuring reading levels in India at scale
Paper and Code
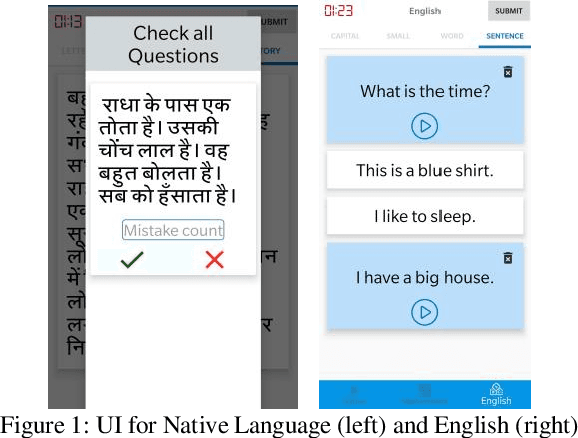
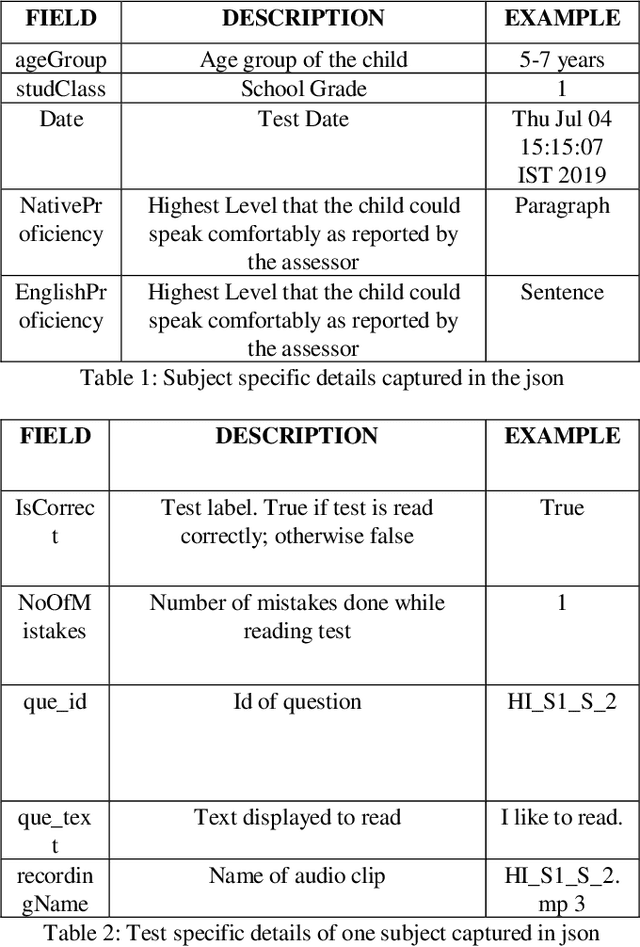
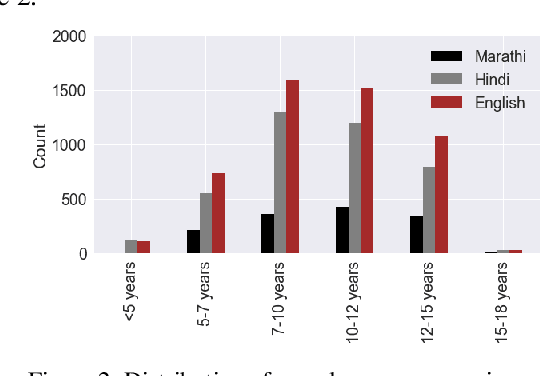
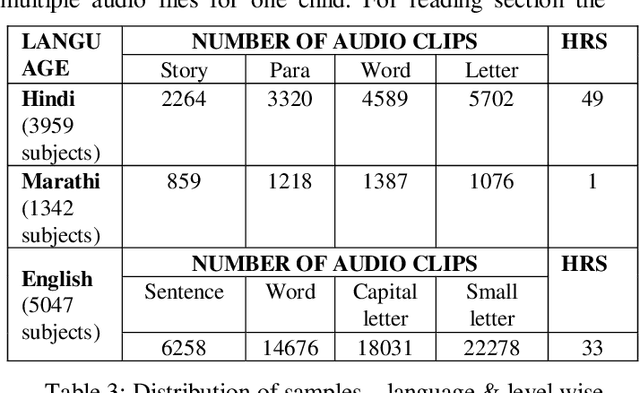
One out of four children in India are leaving grade eight without basic reading skills. Measuring the reading levels in a vast country like India poses significant hurdles. Recent advances in machine learning opens up the possibility of automating this task. However, the datasets are primarily in English. To solve this assessment problem and advance deep learning research in regional Indian languages, we present the ASER dataset of children in the age group of 6-14. The dataset consists of 5,300 subjects generating 81,658 labeled audio clips in Hindi, Marathi and English. These labels represent expert opinions on the ability of the child to read at a specified level. Using this dataset, we built a simple ASR-based classifier. Early results indicate that we can achieve a prediction accuracy of 86 percent for the English language. Considering the ASER survey spans half a million subjects, this dataset can grow to those scales.