 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Hidden Biases of Policy Mirror Ascent in Continuous Action Spaces
Paper and Code
Jan 31, 2022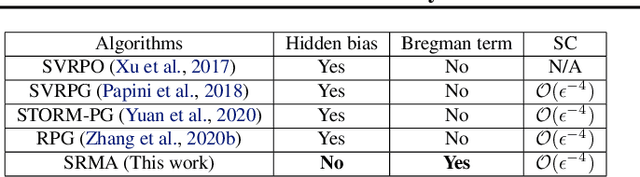
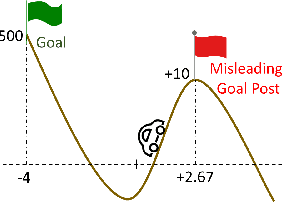

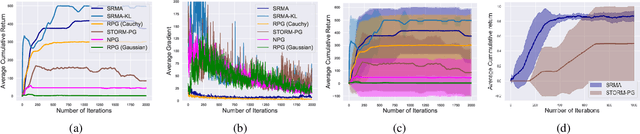
We focus on parameterized policy search for reinforcement learning over continuous action spaces. Typically, one assumes the score function associated with a policy is bounded, which fails to hold even for Gaussian policies. To properly address this issue, one must introduce an exploration tolerance parameter to quantify the region in which it is bounded. Doing so incurs a persistent bias that appears in the attenuation rate of the expected policy gradient norm, which is inversely proportional to the radius of the action space. To mitigate this hidden bias, heavy-tailed policy parameterizations may be used, which exhibit a bounded score function, but doing so can cause instability in algorithmic updates. To address these issues, in this work, we study the convergence of policy gradient algorithms under heavy-tailed parameterizations, which we propose to stabilize with a combination of mirror ascent-type updates and gradient tracking. Our main theoretical contribution is the establishment that this scheme converges with constant step and batch sizes, whereas prior works require these parameters to respectively shrink to null or grow to infinity. Experimentally, this scheme under a heavy-tailed policy parameterization yields improved reward accumulation across a variety of settings as compared with standard benchmarks.