 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent Monitoring Framework for Cloud Services: A Data-Driven Approach
Feb 29, 2024


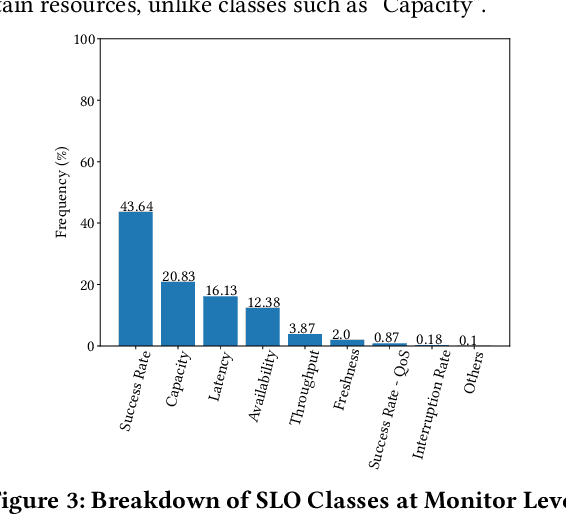
Cloud service owners need to continuously monitor their services to ensure high availability and reliability. Gaps in monitoring can lead to delay in incident detection and significant negative customer impact. Current process of monitor creation is ad-hoc and reactive in nature. Developers create monitors using their tribal knowledge and, primarily, a trial and error based process. As a result, monitors often have incomplete coverage which leads to production issues, or, redundancy which results in noise and wasted effort. In this work, we address this issue by proposing an intelligent monitoring framework that recommends monitors for cloud services based on their service properties. We start by mining the attributes of 30,000+ monitors from 791 production services at Microsoft and derive a structured ontology for monitors. We focus on two crucial dimensions: what to monitor (resources) and which metrics to monitor. We conduct an extensive empirical study and derive key insights on the major classes of monitors employed by cloud services at Microsoft, their associated dimensions, and the interrelationship between service properties and this ontology. Using these insights, we propose a deep learning based framework that recommends monitors based on the service properties. Finally, we conduct a user study with engineers from Microsoft which demonstrates the usefulness of the proposed framework. The proposed framework along with the ontology driven projections, succeeded in creating production quality recommendations for majority of resource classes. This was also validated by the users from the study who rated the framework's usefulness as 4.27 out of 5.
How Private Is Your RL Policy? An Inverse RL Based Analysis Framework
Dec 10, 2021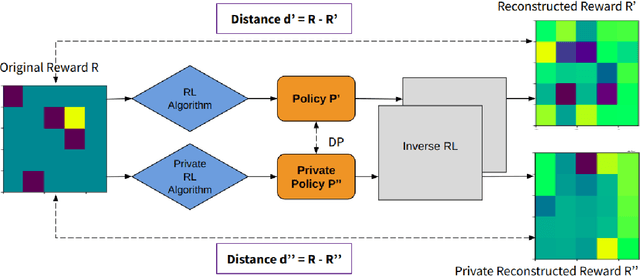
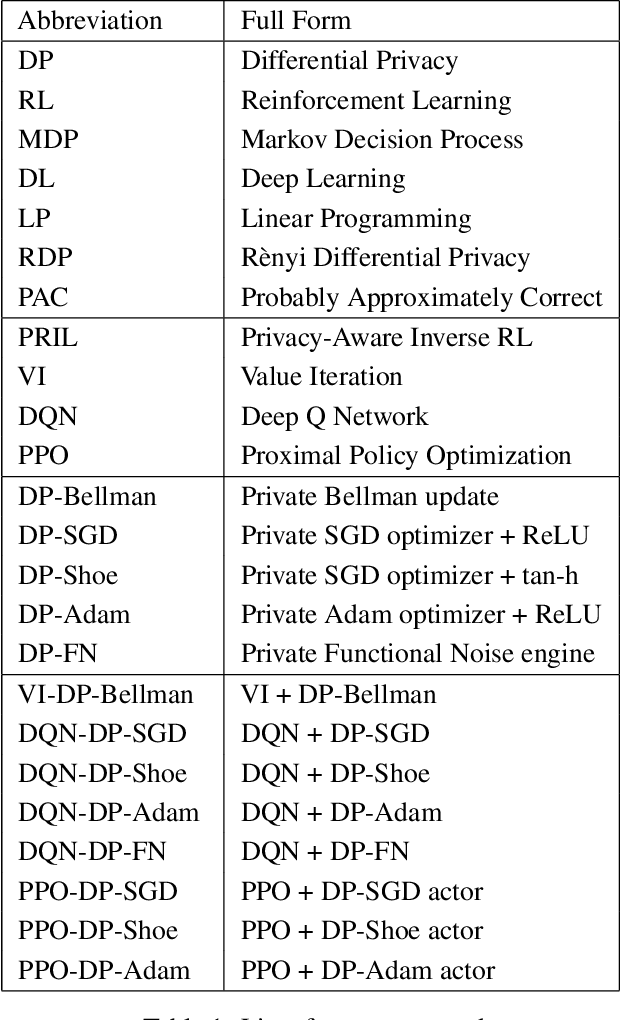


Reinforcement Learning (RL) enables agents to learn how to perform various tasks from scratch. In domains like autonomous driving, recommendation systems, and more, optimal RL policies learned could cause a privacy breach if the policies memorize any part of the private reward. We study the set of existing differentially-private RL policies derived from various RL algorithms such as Value Iteration, Deep Q Networks, and Vanilla Proximal Policy Optimization. We propose a new Privacy-Aware Inverse RL (PRIL) analysis framework, that performs reward reconstruction as an adversarial attack on private policies that the agents may deploy. For this, we introduce the reward reconstruction attack, wherein we seek to reconstruct the original reward from a privacy-preserving policy using an Inverse RL algorithm. An adversary must do poorly at reconstructing the original reward function if the agent uses a tightly private policy. Using this framework, we empirically test the effectiveness of the privacy guarantee offered by the private algorithms on multiple instances of the FrozenLake domain of varying complexities. Based on the analysis performed, we infer a gap between the current standard of privacy offered and the standard of privacy needed to protect reward functions in RL. We do so by quantifying the extent to which each private policy protects the reward function by measuring distances between the original and reconstructed rewards.