 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tale of Two Graphs: Separating Knowledge Exploration from Outline Structure for Open-Ended Deep Research
Feb 14, 2026Open-Ended Deep Research (OEDR) pushes LLM agents beyond short-form QA toward long-horizon workflows that iteratively search, connect, and synthesize evidence into structured reports. However, existing OEDR agents largely follow either linear ``search-then-generate'' accumulation or outline-centric planning. The former suffers from lost-in-the-middle failures as evidence grows, while the latter relies on the LLM to implicitly infer knowledge gaps from the outline alone, providing weak supervision for identifying missing relations and triggering targeted exploration. We present DualGraph memory, an architecture that separates what the agent knows from how it writes. DualGraph maintains two co-evolving graphs: an Outline Graph (OG), and a Knowledge Graph (KG), a semantic memory that stores fine-grained knowledge units, including core entities, concepts, and their relations. By analyzing the KG topology together with structural signals from the OG, DualGraph generates targeted search queries, enabling more efficient and comprehensive iterative knowledge-driven exploration and refinement. Across DeepResearch Bench, DeepResearchGym, and DeepConsult, DualGraph consistently outperforms state-of-the-art baselines in report depth, breadth, and factual grounding; for example, it reaches a 53.08 RACE score on DeepResearch Bench with GPT-5. Moreover, ablation studies confirm the central role of the dual-graph design.
LEGOMem: Modular Procedural Memory for Multi-agent LLM Systems for Workflow Automation
Oct 06, 2025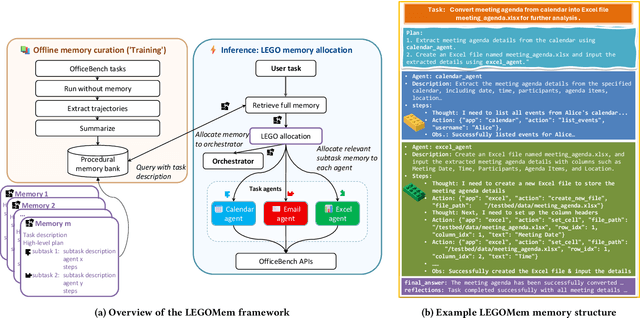
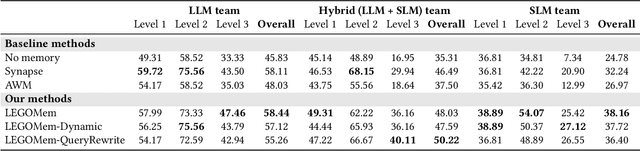
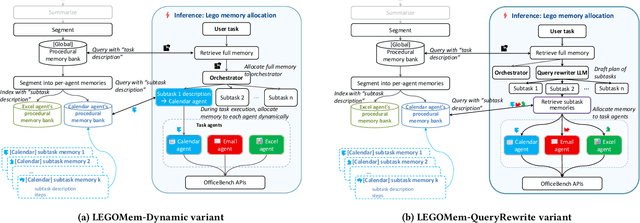
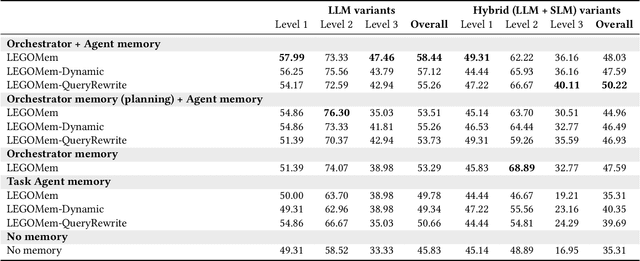
We introduce LEGOMem, a modular procedural memory framework for multi-agent large language model (LLM) systems in workflow automation. LEGOMem decomposes past task trajectories into reusable memory units and flexibly allocates them across orchestrators and task agents to support planning and execution. To explore the design space of memory in multi-agent systems, we use LEGOMem as a lens and conduct a systematic study of procedural memory in multi-agent systems, examining where memory should be placed, how it should be retrieved, and which agents benefit most. Experiments on the OfficeBench benchmark show that orchestrator memory is critical for effective task decomposition and delegation, while fine-grained agent memory improves execution accuracy. We find that even teams composed of smaller language models can benefit substantially from procedural memory, narrowing the performance gap with stronger agents by leveraging prior execution traces for more accurate planning and tool use. These results position LEGOMem as both a practical framework for memory-augmented agent systems and a research tool for understanding memory design in multi-agent workflow automation.
ACON: Optimizing Context Compression for Long-horizon LLM Agents
Oct 01, 2025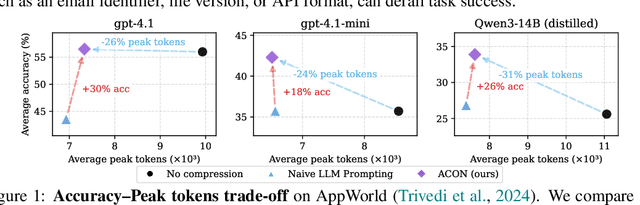
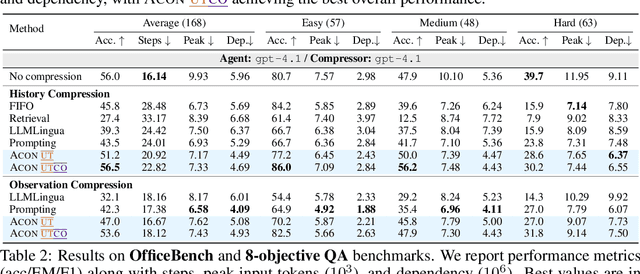
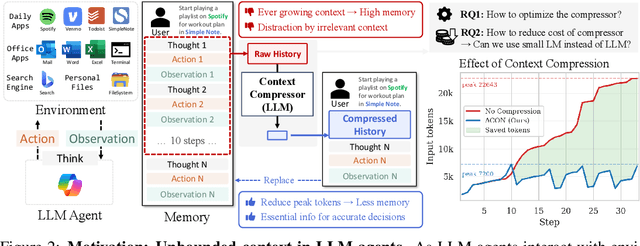
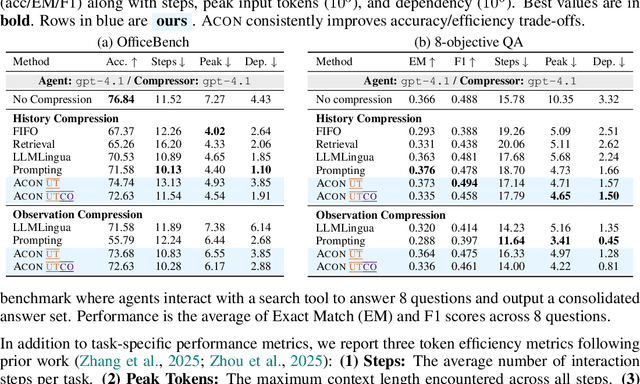
Large language models (LLMs) are increasingly deployed as agents in dynamic, real-world environments, where success requires both reasoning and effective tool use. A central challenge for agentic tasks is the growing context length, as agents must accumulate long histories of actions and observations. This expansion raises costs and reduces efficiency in long-horizon tasks, yet prior work on context compression has mostly focused on single-step tasks or narrow applications. We introduce Agent Context Optimization (ACON), a unified framework that optimally compresses both environment observations and interaction histories into concise yet informative condensations. ACON leverages compression guideline optimization in natural language space: given paired trajectories where full context succeeds but compressed context fails, capable LLMs analyze the causes of failure, and the compression guideline is updated accordingly. Furthermore, we propose distilling the optimized LLM compressor into smaller models to reduce the overhead of the additional module. Experiments on AppWorld, OfficeBench, and Multi-objective QA show that ACON reduces memory usage by 26-54% (peak tokens) while largely preserving task performance, preserves over 95% of accuracy when distilled into smaller compressors, and enhances smaller LMs as long-horizon agents with up to 46% performance improvement.
OdysseyBench: Evaluating LLM Agents on Long-Horizon Complex Office Application Workflows
Aug 12, 2025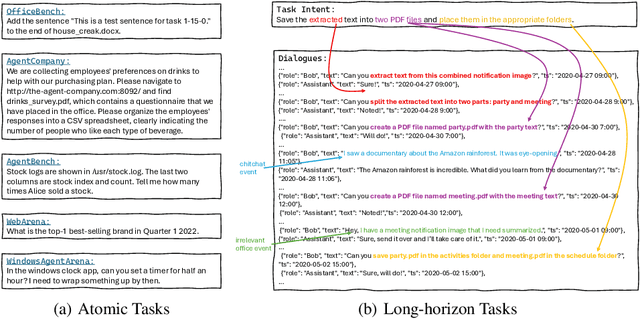
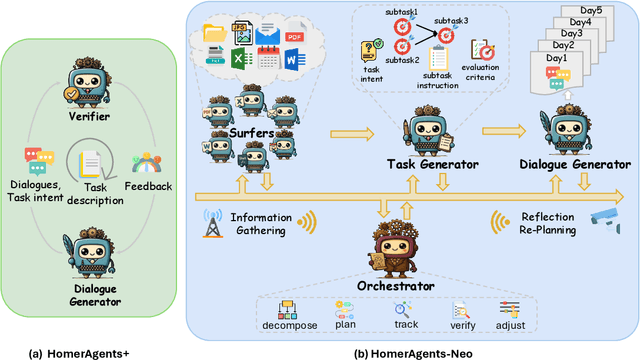
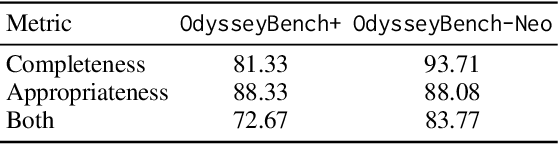
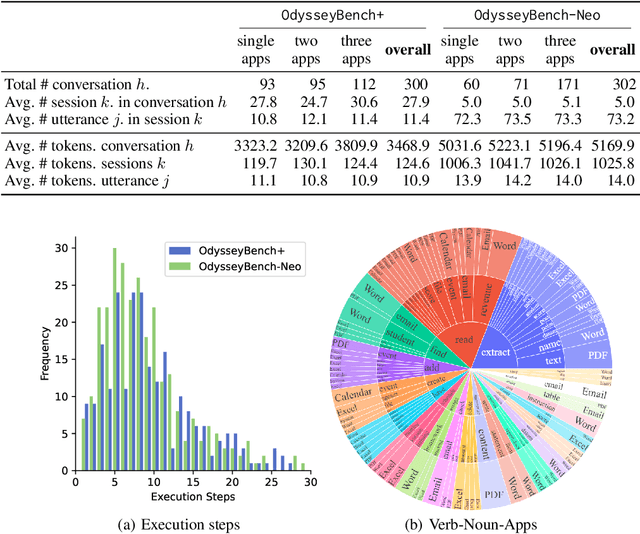
Autonomous agents powered by large language models (LLMs) are increasingly deployed in real-world applications requiring complex, long-horizon workflows. However, existing benchmarks predominantly focus on atomic tasks that are self-contained and independent, failing to capture the long-term contextual dependencies and multi-interaction coordination required in realistic scenarios. To address this gap, we introduce OdysseyBench, a comprehensive benchmark for evaluating LLM agents on long-horizon workflows across diverse office applications including Word, Excel, PDF, Email, and Calendar. Our benchmark comprises two complementary splits: OdysseyBench+ with 300 tasks derived from real-world use cases, and OdysseyBench-Neo with 302 newly synthesized complex tasks. Each task requires agent to identify essential information from long-horizon interaction histories and perform multi-step reasoning across various applications. To enable scalable benchmark creation, we propose HomerAgents, a multi-agent framework that automates the generation of long-horizon workflow benchmarks through systematic environment exploration, task generation, and dialogue synthesis. Our extensive evaluation demonstrates that OdysseyBench effectively challenges state-of-the-art LLM agents, providing more accurate assessment of their capabilities in complex, real-world contexts compared to existing atomic task benchmarks. We believe that OdysseyBench will serve as a valuable resource for advancing the development and evaluation of LLM agents in real-world productivity scenarios. In addition, we release OdysseyBench and HomerAgents to foster research along this line.
Enhancing Reasoning Capabilities of Small Language Models with Blueprints and Prompt Template Search
Jun 10, 2025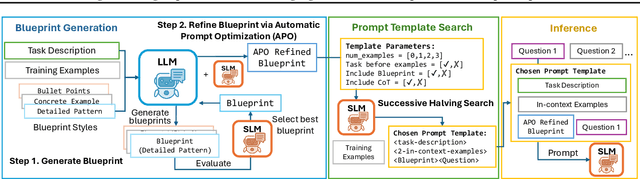
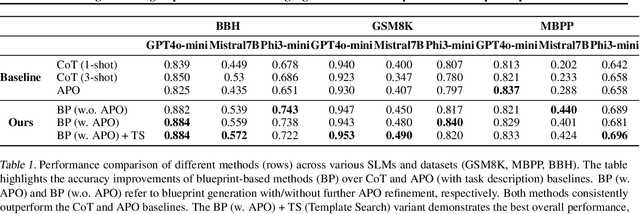


Small language models (SLMs) offer promising and efficient alternatives to large language models (LLMs). However, SLMs' limited capacity restricts their reasoning capabilities and makes them sensitive to prompt variations. To address these challenges, we propose a novel framework that enhances SLM reasoning capabilities through LLM generated blueprints. The blueprints provide structured, high-level reasoning guides that help SLMs systematically tackle related problems. Furthermore, our framework integrates a prompt template search mechanism to mitigate the SLMs' sensitivity to prompt variations. Our framework demonstrates improved SLM performance across various tasks, including math (GSM8K), coding (MBPP), and logic reasoning (BBH). Our approach improves the reasoning capabilities of SLMs without increasing model size or requiring additional training, offering a lightweight and deployment-friendly solution for on-device or resource-constrained environments.
LLM-Personalize: Aligning LLM Planners with Human Preferences via Reinforced Self-Training for Housekeeping Robots
Apr 22, 2024



Large language models (LLMs) have shown significant potential for robotics applications, particularly task planning, by harnessing their language comprehension and text generation capabilities. However, in applications such as household robotics, a critical gap remains in the personalization of these models to individual user preferences. We introduce LLM-Personalize, a novel framework with an optimization pipeline designed to personalize LLM planners for household robotics. Our LLM-Personalize framework features an LLM planner that performs iterative planning in multi-room, partially-observable household scenarios, making use of a scene graph constructed with local observations. The generated plan consists of a sequence of high-level actions which are subsequently executed by a controller. Central to our approach is the optimization pipeline, which combines imitation learning and iterative self-training to personalize the LLM planner. In particular, the imitation learning phase performs initial LLM alignment from demonstrations, and bootstraps the model to facilitate effective iterative self-training, which further explores and aligns the model to user preferences. We evaluate LLM-Personalize on Housekeep, a challenging simulated real-world 3D benchmark for household rearrangements, and show that LLM-Personalize achieves more than a 30 percent increase in success rate over existing LLM planners, showcasing significantly improved alignment with human preferences. Project page: https://donggehan.github.io/projectllmpersonalize/.
Multiagent Model-based Credit Assignment for Continuous Control
Dec 27, 2021
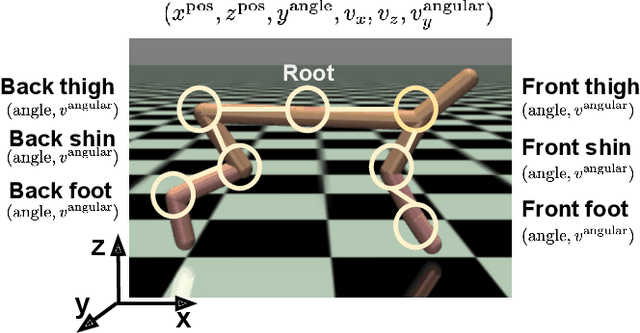
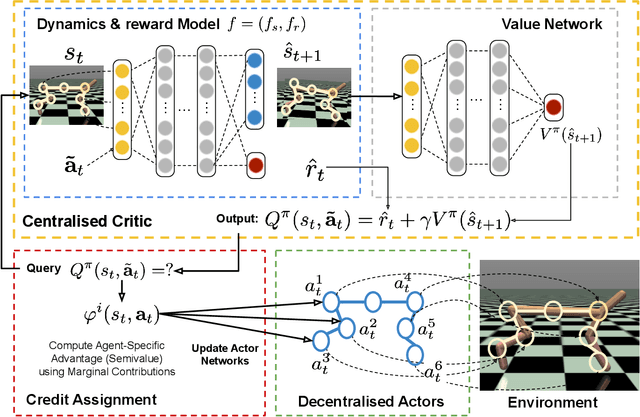
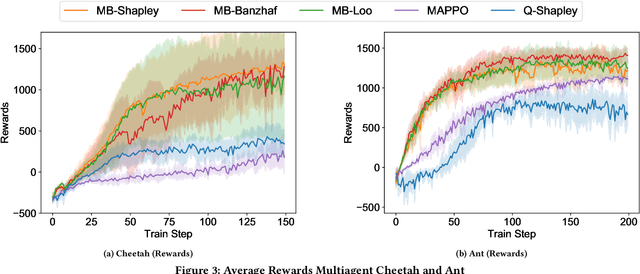
Deep reinforcement learning (RL) has recently shown great promise in robotic continuous control tasks. Nevertheless, prior research in this vein center around the centralized learning setting that largely relies on the communication availability among all the components of a robot. However, agents in the real world often operate in a decentralised fashion without communication due to latency requirements, limited power budgets and safety concerns. By formulating robotic components as a system of decentralised agents, this work presents a decentralised multiagent reinforcement learning framework for continuous control. To this end, we first develop a cooperative multiagent PPO framework that allows for centralized optimisation during training and decentralised operation during execution. However, the system only receives a global reward signal which is not attributed towards each agent. To address this challenge, we further propose a generic game-theoretic credit assignment framework which computes agent-specific reward signals. Last but not least, we also incorporate a model-based RL module into our credit assignment framework, which leads to significant improvement in sample efficiency. We demonstrate the effectiveness of our framework on experimental results on Mujoco locomotion control tasks. For a demo video please visit: https://youtu.be/gFyVPm4svEY.
MDP Abstraction with Successor Features
Oct 18, 2021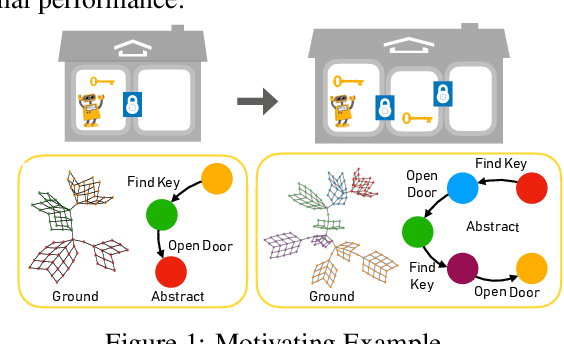
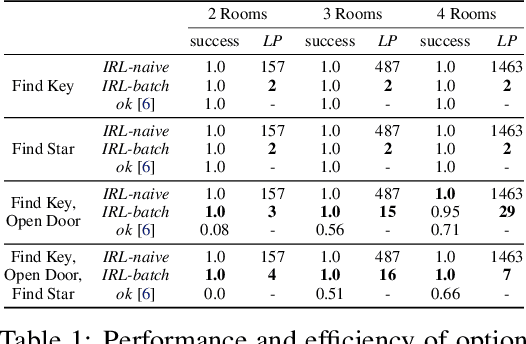
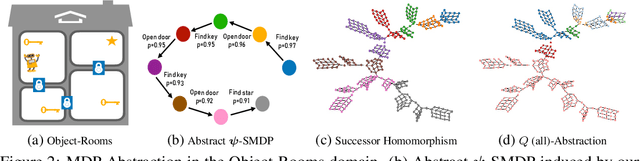
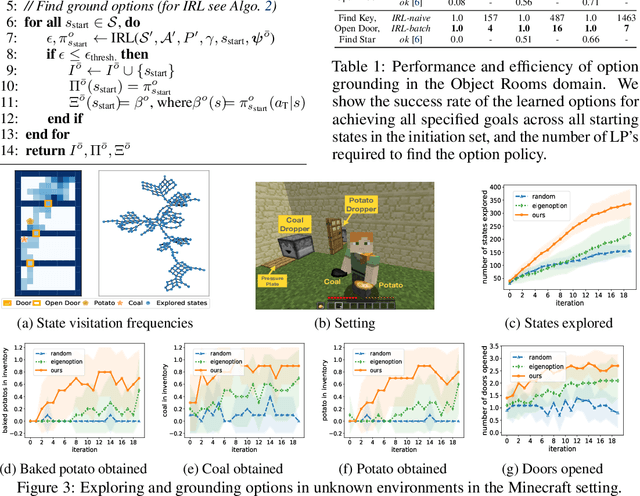
Abstraction plays an important role for generalisation of knowledge and skills, and is key to sample efficient learning and planning. For many complex problems an abstract plan can be formed first, which is then instantiated by filling in the necessary low-level details. Often, such abstract plans generalize well to related new problems. We study abstraction in the context of reinforcement learning, in which agents may perform state or temporal abstractions. Temporal abstractions aka options represent temporally-extended actions in the form of option policies. However, typically acquired option policies cannot be directly transferred to new environments due to changes in the state space or transition dynamics. Furthermore, many existing state abstraction schemes ignore the correlation between state and temporal abstraction. In this work, we propose successor abstraction, a novel abstraction scheme building on successor features. This includes an algorithm for encoding and instantiation of abstract options across different environments, and a state abstraction mechanism based on the abstract options. Our successor abstraction allows us to learn abstract environment models with semantics that are transferable across different environments through encoding and instantiation of abstract options. Empirically, we achieve better transfer and improved performance on a set of benchmark tasks as compared to relevant state of the art baselines.
Replication-Robust Payoff-Allocation with Applications in Machine Learning Marketplaces
Jun 25, 2020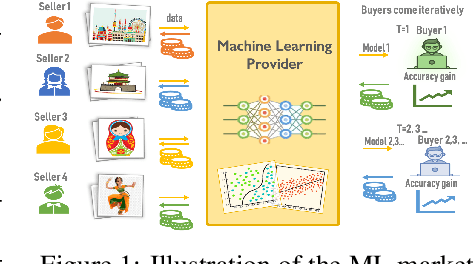
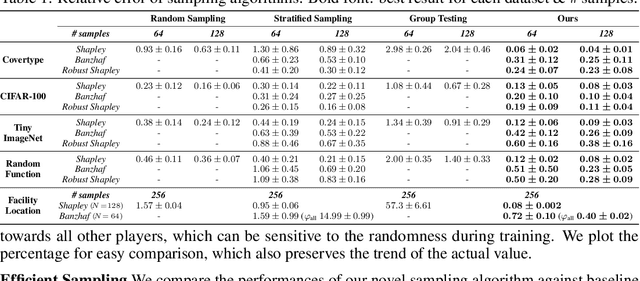
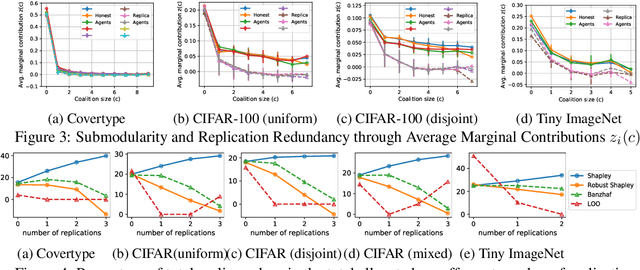
The ever-increasing take-up of machine learning techniques requires ever-more application-specific training data. Manually collecting such training data is a tedious and time-consuming process. Data marketplaces represent a compelling alternative, providing an easy way for acquiring data from potential data providers. A key component of such marketplaces is the compensation mechanism for data providers. Classic payoff-allocation methods such as the Shapley value can be vulnerable to data-replication attacks, and are infeasible to compute in the absence of efficient approximation algorithms. To address these challenges, we present an extensive theoretical study on the vulnerabilities of game theoretic payoff-allocation schemes to replication attacks. Our insights apply to a wide range of payoff-allocation schemes, and enable the design of customised replication-robust payoff-allocations. Furthermore, we present a novel efficient sampling algorithm for approximating payoff-allocation schemes based on marginal contributions. In our experiments, we validate the replication-robustness of classic payoff-allocation schemes and new payoff-allocation schemes derived from our theoretical insights. We also demonstrate the efficiency of our proposed sampling algorithm on a wide range of machine learning tasks.
Multi-agent Hierarchical Reinforcement Learning with Dynamic Termination
Oct 21, 2019
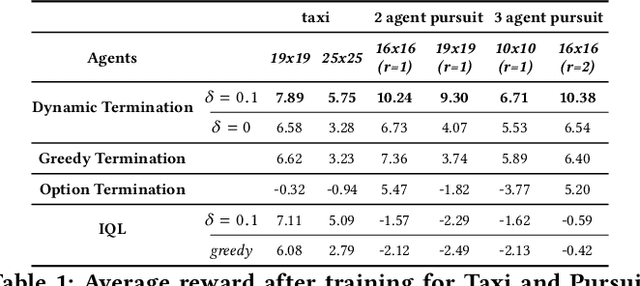
In a multi-agent system, an agent's optimal policy will typically depend on the policies chosen by others. Therefore, a key issue in multi-agent systems research is that of predicting the behaviours of others, and responding promptly to changes in such behaviours. One obvious possibility is for each agent to broadcast their current intention, for example, the currently executed option in a hierarchical reinforcement learning framework. However, this approach results in inflexibility of agents if options have an extended duration and are dynamic. While adjusting the executed option at each step improves flexibility from a single-agent perspective, frequent changes in options can induce inconsistency between an agent's actual behaviour and its broadcast intention. In order to balance flexibility and predictability, we propose a dynamic termination Bellman equation that allows the agents to flexibly terminate their options. We evaluate our model empirically on a set of multi-agent pursuit and taxi tasks, and show that our agents learn to adapt flexibly across scenarios that require different termination behaviours.