 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent Hierarchical Reinforcement Learning with Dynamic Termination
Paper and Code
Oct 21, 2019
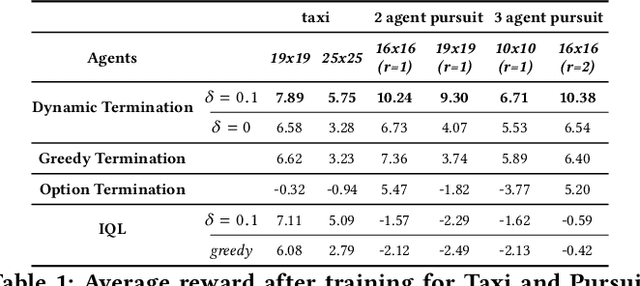
In a multi-agent system, an agent's optimal policy will typically depend on the policies chosen by others. Therefore, a key issue in multi-agent systems research is that of predicting the behaviours of others, and responding promptly to changes in such behaviours. One obvious possibility is for each agent to broadcast their current intention, for example, the currently executed option in a hierarchical reinforcement learning framework. However, this approach results in inflexibility of agents if options have an extended duration and are dynamic. While adjusting the executed option at each step improves flexibility from a single-agent perspective, frequent changes in options can induce inconsistency between an agent's actual behaviour and its broadcast intention. In order to balance flexibility and predictability, we propose a dynamic termination Bellman equation that allows the agents to flexibly terminate their options. We evaluate our model empirically on a set of multi-agent pursuit and taxi tasks, and show that our agents learn to adapt flexibly across scenarios that require different termination behaviours.