 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Few Labeled Nodes via Augmented Graph Self-Training
Aug 26, 2022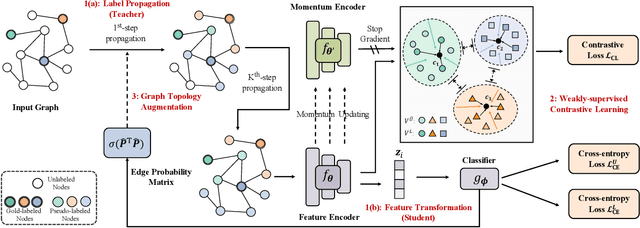
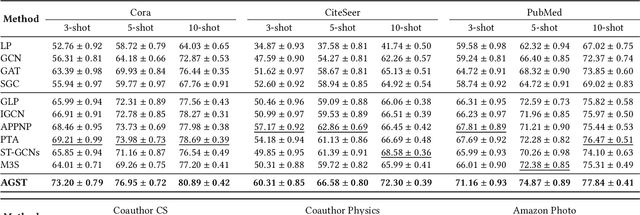
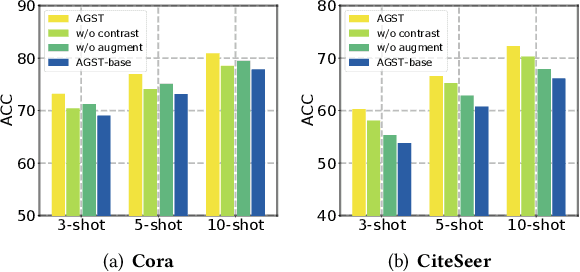
It is well known that the success of graph neural networks (GNNs) highly relies on abundant human-annotated data, which is laborious to obtain and not always available in practice. When only few labeled nodes are available, how to develop highly effective GNNs remains understudied. Though self-training has been shown to be powerful for semi-supervised learning, its application on graph-structured data may fail because (1) larger receptive fields are not leveraged to capture long-range node interactions, which exacerbates the difficulty of propagating feature-label patterns from labeled nodes to unlabeled nodes; and (2) limited labeled data makes it challenging to learn well-separated decision boundaries for different node classes without explicitly capturing the underlying semantic structure. To address the challenges of capturing informative structural and semantic knowledge, we propose a new graph data augmentation framework, AGST (Augmented Graph Self-Training), which is built with two new (i.e., structural and semantic) augmentation modules on top of a decoupled GST backbone. In this work, we investigate whether this novel framework can learn an effective graph predictive model with extremely limited labeled nodes. We conduct comprehensive evaluations on semi-supervised node classification under different scenarios of limited labeled-node data. The experimental results demonstrate the unique contributions of the novel data augmentation framework for node classification with few labeled data.
Characterizing Stage-Aware Writing Assistance in Collaborative Document Authoring
Aug 18, 2020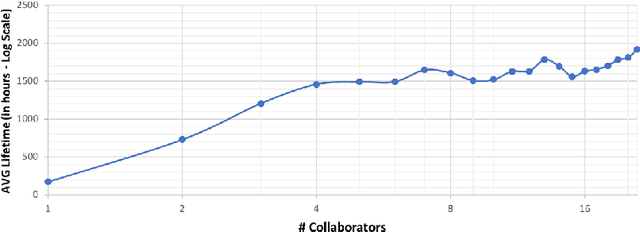
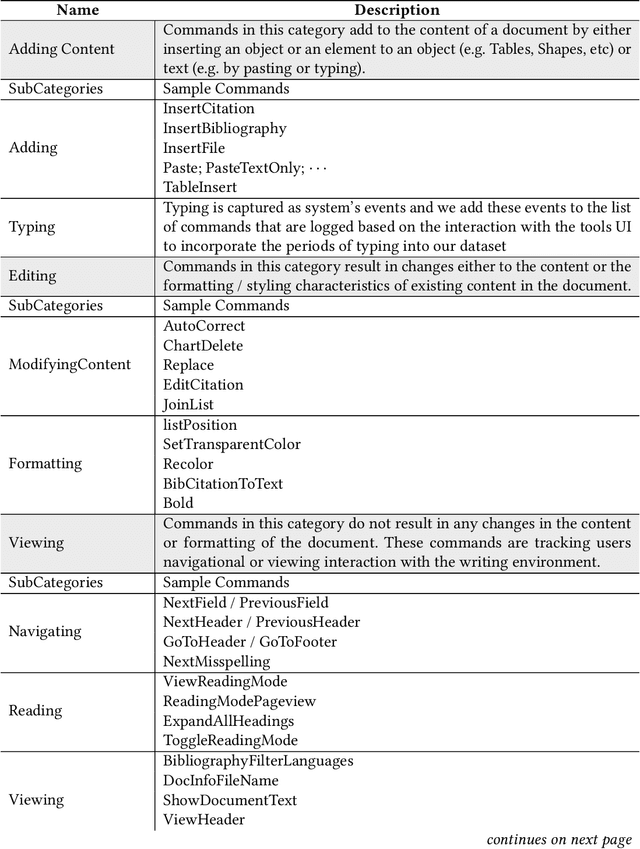
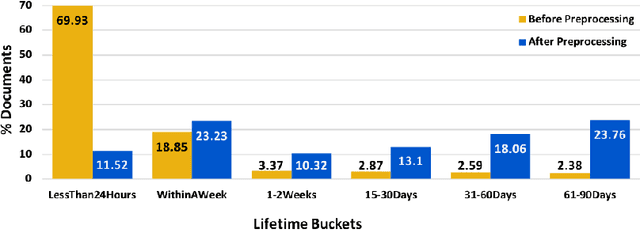
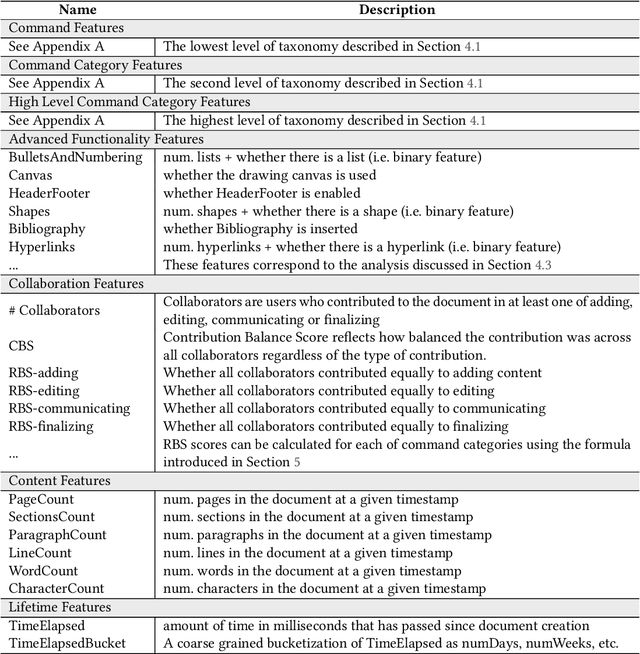
Writing is a complex non-linear process that begins with a mental model of intent, and progresses through an outline of ideas, to words on paper (and their subsequent refinement). Despite past research in understanding writing, Web-scale consumer and enterprise collaborative digital writing environments are yet to greatly benefit from intelligent systems that understand the stages of document evolution, providing opportune assistance based on authors' situated actions and context. In this paper, we present three studies that explore temporal stages of document authoring. We first survey information workers at a large technology company about their writing habits and preferences, concluding that writers do in fact conceptually progress through several distinct phases while authoring documents. We also explore, qualitatively, how writing stages are linked to document lifespan. We supplement these qualitative findings with an analysis of the longitudinal user interaction logs of a popular digital writing platform over several million documents. Finally, as a first step towards facilitating an intelligent digital writing assistant, we conduct a preliminary investigation into the utility of user interaction log data for predicting the temporal stage of a document. Our results support the benefit of tools tailored to writing stages, identify primary tasks associated with these stages, and show that it is possible to predict stages from anonymous interaction logs. Together, these results argue for the benefit and feasibility of more tailored digital writing assistance.
* Accepted for publication at CSCW 2020
Smart To-Do : Automatic Generation of To-Do Items from Emails
May 05, 2020

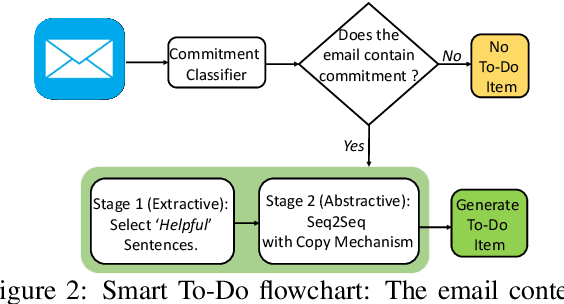
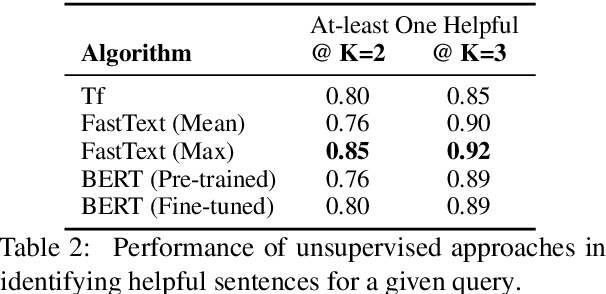
Intelligent features in email service applications aim to increase productivity by helping people organize their folders, compose their emails and respond to pending tasks. In this work, we explore a new application, Smart-To-Do, that helps users with task management over emails. We introduce a new task and dataset for automatically generating To-Do items from emails where the sender has promised to perform an action. We design a two-stage process leveraging recent advances in neural text generation and sequence-to-sequence learning, obtaining BLEU and ROUGE scores of 0:23 and 0:63 for this task. To the best of our knowledge, this is the first work to address the problem of composing To-Do items from emails.
Information Gathering in Networks via Active Exploration
May 06, 2015

How should we gather information in a network, where each node's visibility is limited to its local neighborhood? This problem arises in numerous real-world applications, such as surveying and task routing in social networks, team formation in collaborative networks and experimental design with dependency constraints. Often the informativeness of a set of nodes can be quantified via a submodular utility function. Existing approaches for submodular optimization, however, require that the set of all nodes that can be selected is known ahead of time, which is often unrealistic. In contrast, we propose a novel model where we start our exploration from an initial node, and new nodes become visible and available for selection only once one of their neighbors has been chosen. We then present a general algorithm NetExp for this problem, and provide theoretical bounds on its performance dependent on structural properties of the underlying network. We evaluate our methodology on various simulated problem instances as well as on data collected from social question answering system deployed within a large enterprise.
Stochastic Privacy
Apr 22, 2014

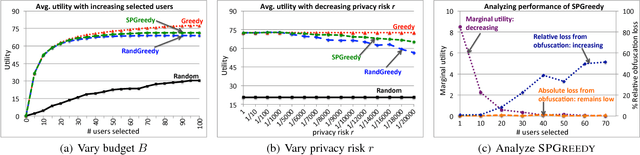
Online services such as web search and e-commerce applications typically rely on the collection of data about users, including details of their activities on the web. Such personal data is used to enhance the quality of service via personalization of content and to maximize revenues via better targeting of advertisements and deeper engagement of users on sites. To date, service providers have largely followed the approach of either requiring or requesting consent for opting-in to share their data. Users may be willing to share private information in return for better quality of service or for incentives, or in return for assurances about the nature and extend of the logging of data. We introduce \emph{stochastic privacy}, a new approach to privacy centering on a simple concept: A guarantee is provided to users about the upper-bound on the probability that their personal data will be used. Such a probability, which we refer to as \emph{privacy risk}, can be assessed by users as a preference or communicated as a policy by a service provider. Service providers can work to personalize and to optimize revenues in accordance with preferences about privacy risk. We present procedures, proofs, and an overall system for maximizing the quality of services, while respecting bounds on allowable or communicated privacy risk. We demonstrate the methodology with a case study and evaluation of the procedures applied to web search personalization. We show how we can achieve near-optimal utility of accessing information with provable guarantees on the probability of sharing data.