 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Few Labeled Nodes via Augmented Graph Self-Training
Paper and Code
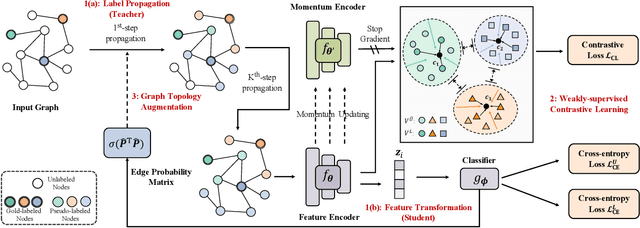
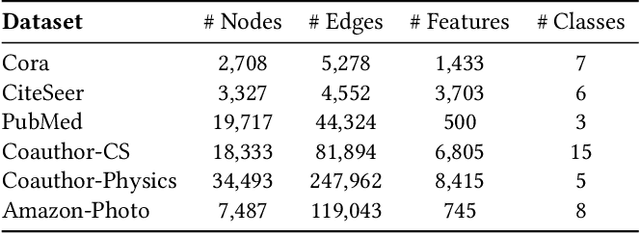
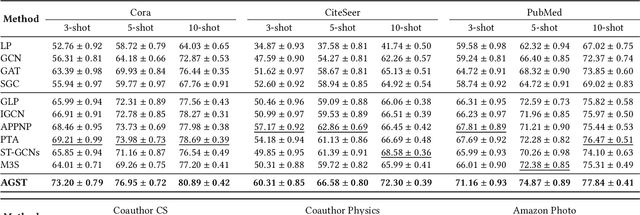
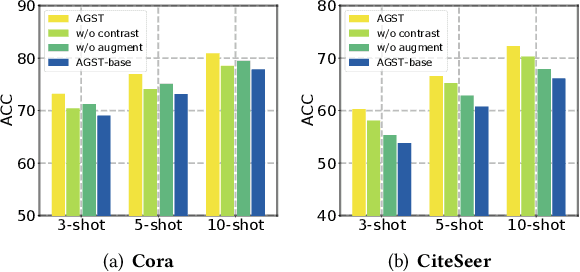
It is well known that the success of graph neural networks (GNNs) highly relies on abundant human-annotated data, which is laborious to obtain and not always available in practice. When only few labeled nodes are available, how to develop highly effective GNNs remains understudied. Though self-training has been shown to be powerful for semi-supervised learning, its application on graph-structured data may fail because (1) larger receptive fields are not leveraged to capture long-range node interactions, which exacerbates the difficulty of propagating feature-label patterns from labeled nodes to unlabeled nodes; and (2) limited labeled data makes it challenging to learn well-separated decision boundaries for different node classes without explicitly capturing the underlying semantic structure. To address the challenges of capturing informative structural and semantic knowledge, we propose a new graph data augmentation framework, AGST (Augmented Graph Self-Training), which is built with two new (i.e., structural and semantic) augmentation modules on top of a decoupled GST backbone. In this work, we investigate whether this novel framework can learn an effective graph predictive model with extremely limited labeled nodes. We conduct comprehensive evaluations on semi-supervised node classification under different scenarios of limited labeled-node data. The experimental results demonstrate the unique contributions of the novel data augmentation framework for node classification with few labeled data.