 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDORA: Exploring outlier representations in Deep Neural Networks
Paper and Code
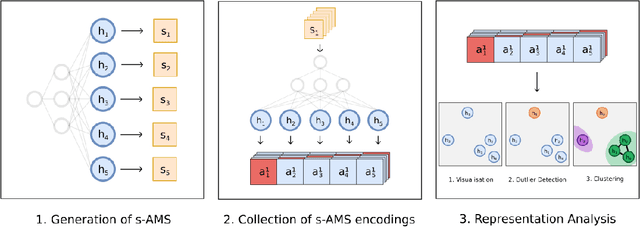
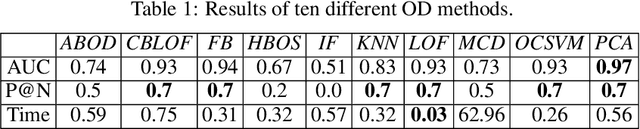
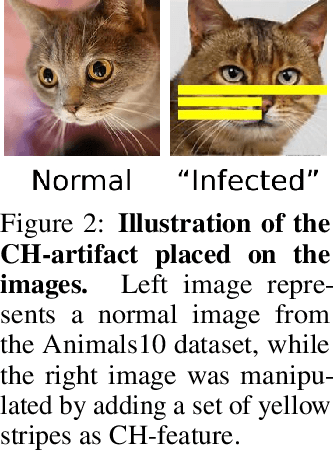
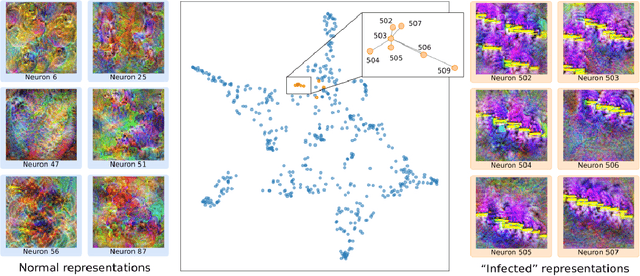
Deep Neural Networks (DNNs) draw their power from the representations they learn. In recent years, however, researchers have found that DNNs, while being incredibly effective in learning complex abstractions, also tend to be infected with artifacts, such as biases, Clever Hanses (CH), or Backdoors, due to spurious correlations inherent in the training data. So far, existing methods for uncovering such artifactual and malicious behavior in trained models focus on finding artifacts in the input data, which requires both availabilities of a data set and human intervention. In this paper, we introduce DORA (Data-agnOstic Representation Analysis): the first automatic data-agnostic method for the detection of potentially infected representations in Deep Neural Networks. We further show that contaminated representations found by DORA can be used to detect infected samples in any given dataset. We qualitatively and quantitatively evaluate the performance of our proposed method in both, controlled toy scenarios, and in real-world settings, where we demonstrate the benefit of DORA in safety-critical applications.