 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoisoning Behavioral Malware Clustering
Nov 25, 2018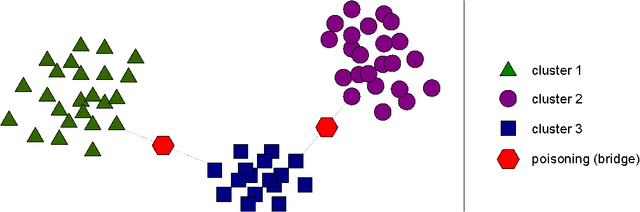

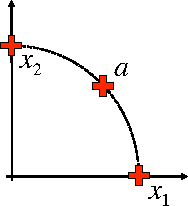
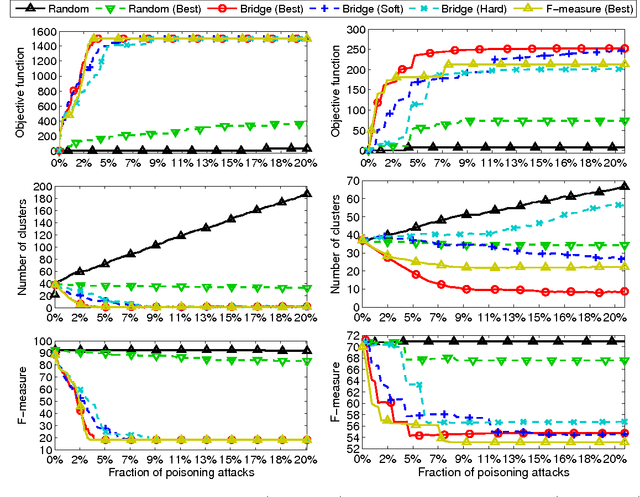
Clustering algorithms have become a popular tool in computer security to analyze the behavior of malware variants, identify novel malware families, and generate signatures for antivirus systems. However, the suitability of clustering algorithms for security-sensitive settings has been recently questioned by showing that they can be significantly compromised if an attacker can exercise some control over the input data. In this paper, we revisit this problem by focusing on behavioral malware clustering approaches, and investigate whether and to what extent an attacker may be able to subvert these approaches through a careful injection of samples with poisoning behavior. To this end, we present a case study on Malheur, an open-source tool for behavioral malware clustering. Our experiments not only demonstrate that this tool is vulnerable to poisoning attacks, but also that it can be significantly compromised even if the attacker can only inject a very small percentage of attacks into the input data. As a remedy, we discuss possible countermeasures and highlight the need for more secure clustering algorithms.
Evasion Attacks against Machine Learning at Test Time
Aug 21, 2017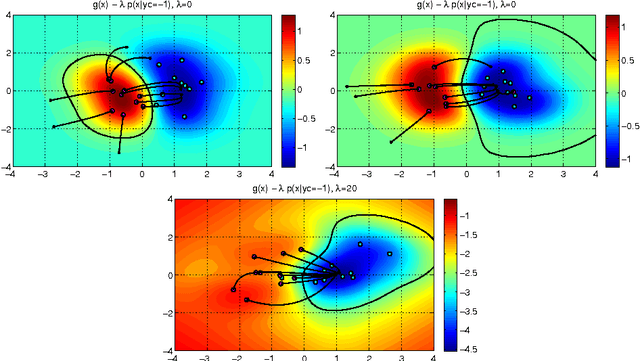
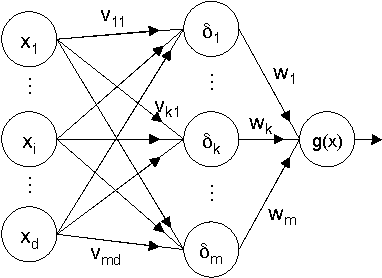
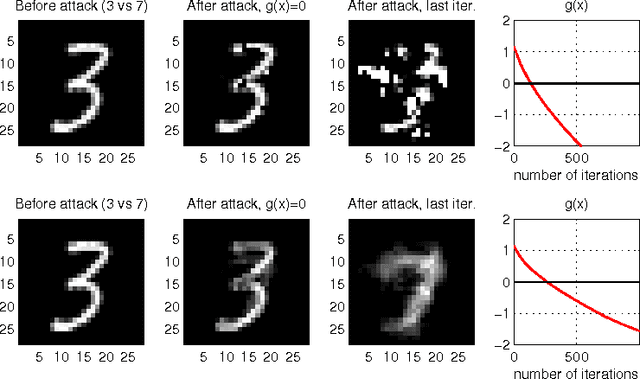
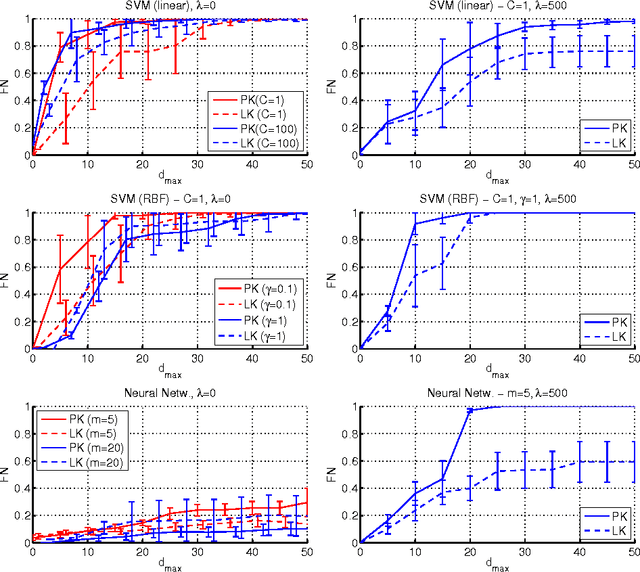
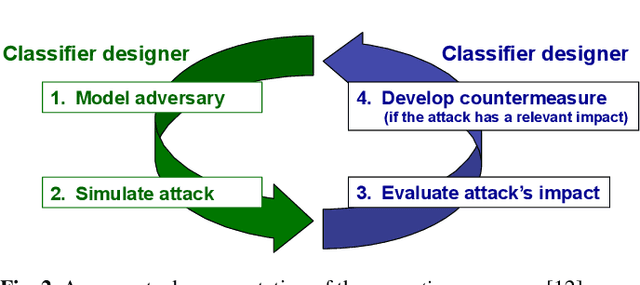
In security-sensitive applications, the success of machine learning depends on a thorough vetting of their resistance to adversarial data. In one pertinent, well-motivated attack scenario, an adversary may attempt to evade a deployed system at test time by carefully manipulating attack samples. In this work, we present a simple but effective gradient-based approach that can be exploited to systematically assess the security of several, widely-used classification algorithms against evasion attacks. Following a recently proposed framework for security evaluation, we simulate attack scenarios that exhibit different risk levels for the classifier by increasing the attacker's knowledge of the system and her ability to manipulate attack samples. This gives the classifier designer a better picture of the classifier performance under evasion attacks, and allows him to perform a more informed model selection (or parameter setting). We evaluate our approach on the relevant security task of malware detection in PDF files, and show that such systems can be easily evaded. We also sketch some countermeasures suggested by our analysis.
* In this paper, in 2013, we were the first to introduce the notion of evasion attacks (adversarial examples) created with high confidence (instead of minimum-distance misclassifications), and the notion of surrogate learners (substitute models). These two concepts are now widely re-used in developing attacks against deep networks (even if not always referring to the ideas reported in this work). arXiv admin note: text overlap with arXiv:1401.7727
AdversariaLib: An Open-source Library for the Security Evaluation of Machine Learning Algorithms Under Attack
Nov 15, 2016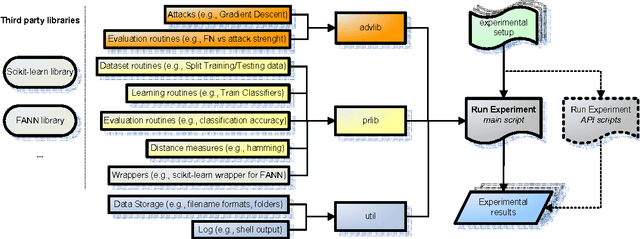

We present AdversariaLib, an open-source python library for the security evaluation of machine learning (ML) against carefully-targeted attacks. It supports the implementation of several attacks proposed thus far in the literature of adversarial learning, allows for the evaluation of a wide range of ML algorithms, runs on multiple platforms, and has multi-processing enabled. The library has a modular architecture that makes it easy to use and to extend by implementing novel attacks and countermeasures. It relies on other widely-used open-source ML libraries, including scikit-learn and FANN. Classification algorithms are implemented and optimized in C/C++, allowing for a fast evaluation of the simulated attacks. The package is distributed under the GNU General Public License v3, and it is available for download at http://sourceforge.net/projects/adversarialib.
Security Evaluation of Support Vector Machines in Adversarial Environments
Jan 30, 2014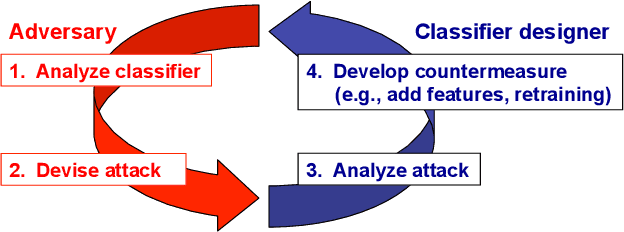
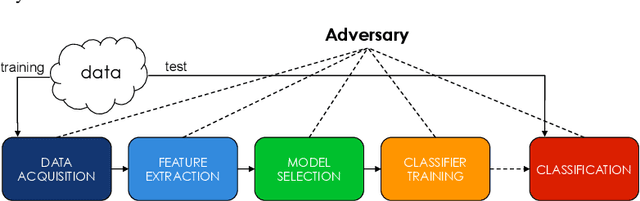
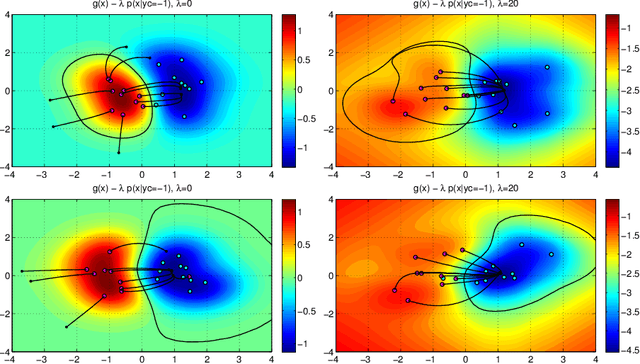
Support Vector Machines (SVMs) are among the most popular classification techniques adopted in security applications like malware detection, intrusion detection, and spam filtering. However, if SVMs are to be incorporated in real-world security systems, they must be able to cope with attack patterns that can either mislead the learning algorithm (poisoning), evade detection (evasion), or gain information about their internal parameters (privacy breaches). The main contributions of this chapter are twofold. First, we introduce a formal general framework for the empirical evaluation of the security of machine-learning systems. Second, according to our framework, we demonstrate the feasibility of evasion, poisoning and privacy attacks against SVMs in real-world security problems. For each attack technique, we evaluate its impact and discuss whether (and how) it can be countered through an adversary-aware design of SVMs. Our experiments are easily reproducible thanks to open-source code that we have made available, together with all the employed datasets, on a public repository.