 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: The Pitfalls of Deep Reinforcement Learning for Cybersecurity
Feb 09, 2026Deep Reinforcement Learning (DRL) has achieved remarkable success in domains requiring sequential decision-making, motivating its application to cybersecurity problems. However, transitioning DRL from laboratory simulations to bespoke cyber environments can introduce numerous issues. This is further exacerbated by the often adversarial, non-stationary, and partially-observable nature of most cybersecurity tasks. In this paper, we identify and systematize 11 methodological pitfalls that frequently occur in DRL for cybersecurity (DRL4Sec) literature across the stages of environment modeling, agent training, performance evaluation, and system deployment. By analyzing 66 significant DRL4Sec papers (2018-2025), we quantify the prevalence of each pitfall and find an average of over five pitfalls per paper. We demonstrate the practical impact of these pitfalls using controlled experiments in (i) autonomous cyber defense, (ii) adversarial malware creation, and (iii) web security testing environments. Finally, we provide actionable recommendations for each pitfall to support the development of more rigorous and deployable DRL-based security systems.
DRMD: Deep Reinforcement Learning for Malware Detection under Concept Drift
Aug 26, 2025Malware detection in real-world settings must deal with evolving threats, limited labeling budgets, and uncertain predictions. Traditional classifiers, without additional mechanisms, struggle to maintain performance under concept drift in malware domains, as their supervised learning formulation cannot optimize when to defer decisions to manual labeling and adaptation. Modern malware detection pipelines combine classifiers with monthly active learning (AL) and rejection mechanisms to mitigate the impact of concept drift. In this work, we develop a novel formulation of malware detection as a one-step Markov Decision Process and train a deep reinforcement learning (DRL) agent, simultaneously optimizing sample classification performance and rejecting high-risk samples for manual labeling. We evaluated the joint detection and drift mitigation policy learned by the DRL-based Malware Detection (DRMD) agent through time-aware evaluations on Android malware datasets subject to realistic drift requiring multi-year performance stability. The policies learned under these conditions achieve a higher Area Under Time (AUT) performance compared to standard classification approaches used in the domain, showing improved resilience to concept drift. Specifically, the DRMD agent achieved a $5.18\pm5.44$, $14.49\pm12.86$, and $10.06\pm10.81$ average AUT performance improvement for the classification only, classification with rejection, and classification with rejection and AL settings, respectively. Our results demonstrate for the first time that DRL can facilitate effective malware detection and improved resiliency to concept drift in the dynamic environment of the Android malware domain.
One Pic is All it Takes: Poisoning Visual Document Retrieval Augmented Generation with a Single Image
Apr 02, 2025



Multimodal retrieval augmented generation (M-RAG) has recently emerged as a method to inhibit hallucinations of large multimodal models (LMMs) through a factual knowledge base (KB). However, M-RAG also introduces new attack vectors for adversaries that aim to disrupt the system by injecting malicious entries into the KB. In this work, we present a poisoning attack against M-RAG targeting visual document retrieval applications, where the KB contains images of document pages. Our objective is to craft a single image that is retrieved for a variety of different user queries, and consistently influences the output produced by the generative model, thus creating a universal denial-of-service (DoS) attack against the M-RAG system. We demonstrate that while our attack is effective against a diverse range of widely-used, state-of-the-art retrievers (embedding models) and generators (LMMs), it can also be ineffective against robust embedding models. Our attack not only highlights the vulnerability of M-RAG pipelines to poisoning attacks, but also sheds light on a fundamental weakness that potentially hinders their performance even in benign settings.
SoK: On Closing the Applicability Gap in Automated Vulnerability Detection
Dec 15, 2024



The frequent discovery of security vulnerabilities in both open-source and proprietary software underscores the urgent need for earlier detection during the development lifecycle. Initiatives such as DARPA's Artificial Intelligence Cyber Challenge (AIxCC) aim to accelerate Automated Vulnerability Detection (AVD), seeking to address this challenge by autonomously analyzing source code to identify vulnerabilities. This paper addresses two primary research questions: (RQ1) How is current AVD research distributed across its core components? (RQ2) What key areas should future research target to bridge the gap in the practical applicability of AVD throughout software development? To answer these questions, we conduct a systematization over 79 AVD articles and 17 empirical studies, analyzing them across five core components: task formulation and granularity, input programming languages and representations, detection approaches and key solutions, evaluation metrics and datasets, and reported performance. Our systematization reveals that the narrow focus of AVD research-mainly on specific tasks and programming languages-limits its practical impact and overlooks broader areas crucial for effective, real-world vulnerability detection. We identify significant challenges, including the need for diversified problem formulations, varied detection granularities, broader language support, better dataset quality, enhanced reproducibility, and increased practical impact. Based on these findings we identify research directions that will enhance the effectiveness and applicability of AVD solutions in software security.
TESSERACT: Eliminating Experimental Bias in Malware Classification across Space and Time (Extended Version)
Feb 02, 2024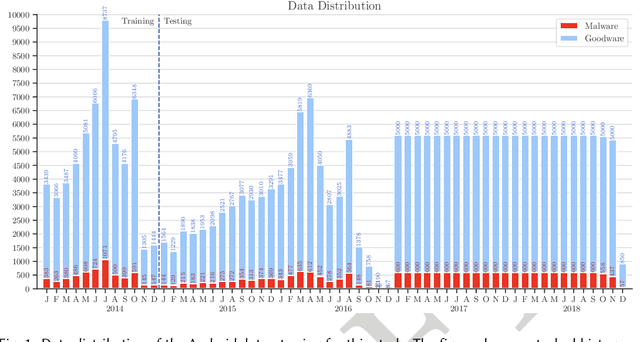
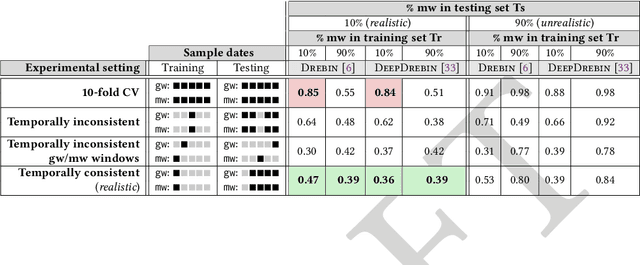
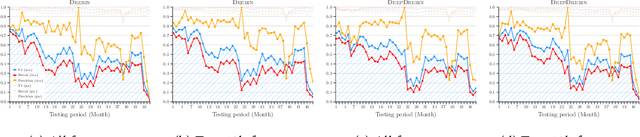
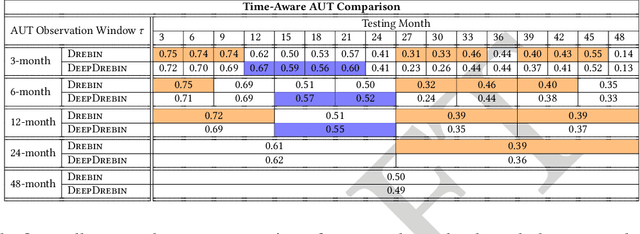
Machine learning (ML) plays a pivotal role in detecting malicious software. Despite the high F1-scores reported in numerous studies reaching upwards of 0.99, the issue is not completely solved. Malware detectors often experience performance decay due to constantly evolving operating systems and attack methods, which can render previously learned knowledge insufficient for accurate decision-making on new inputs. This paper argues that commonly reported results are inflated due to two pervasive sources of experimental bias in the detection task: spatial bias caused by data distributions that are not representative of a real-world deployment; and temporal bias caused by incorrect time splits of data, leading to unrealistic configurations. To address these biases, we introduce a set of constraints for fair experiment design, and propose a new metric, AUT, for classifier robustness in real-world settings. We additionally propose an algorithm designed to tune training data to enhance classifier performance. Finally, we present TESSERACT, an open-source framework for realistic classifier comparison. Our evaluation encompasses both traditional ML and deep learning methods, examining published works on an extensive Android dataset with 259,230 samples over a five-year span. Additionally, we conduct case studies in the Windows PE and PDF domains. Our findings identify the existence of biases in previous studies and reveal that significant performance enhancements are possible through appropriate, periodic tuning. We explore how mitigation strategies may support in achieving a more stable and better performance over time by employing multiple strategies to delay performance decay.