 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding the Secrets of Machine Learning in Malware Classification: A Deep Dive into Datasets, Feature Extraction, and Model Performance
Jul 27, 2023



Many studies have proposed machine-learning (ML) models for malware detection and classification, reporting an almost-perfect performance. However, they assemble ground-truth in different ways, use diverse static- and dynamic-analysis techniques for feature extraction, and even differ on what they consider a malware family. As a consequence, our community still lacks an understanding of malware classification results: whether they are tied to the nature and distribution of the collected dataset, to what extent the number of families and samples in the training dataset influence performance, and how well static and dynamic features complement each other. This work sheds light on those open questions. by investigating the key factors influencing ML-based malware detection and classification. For this, we collect the largest balanced malware dataset so far with 67K samples from 670 families (100 samples each), and train state-of-the-art models for malware detection and family classification using our dataset. Our results reveal that static features perform better than dynamic features, and that combining both only provides marginal improvement over static features. We discover no correlation between packing and classification accuracy, and that missing behaviors in dynamically-extracted features highly penalize their performance. We also demonstrate how a larger number of families to classify make the classification harder, while a higher number of samples per family increases accuracy. Finally, we find that models trained on a uniform distribution of samples per family better generalize on unseen data.
"Real Attackers Don't Compute Gradients": Bridging the Gap Between Adversarial ML Research and Practice
Dec 29, 2022
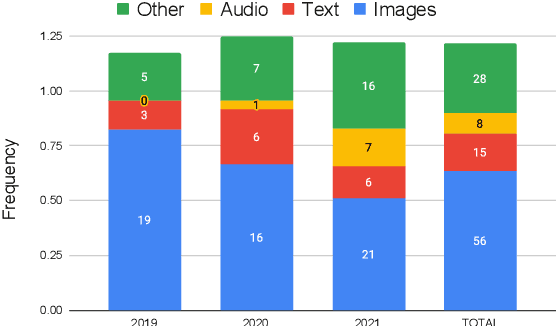
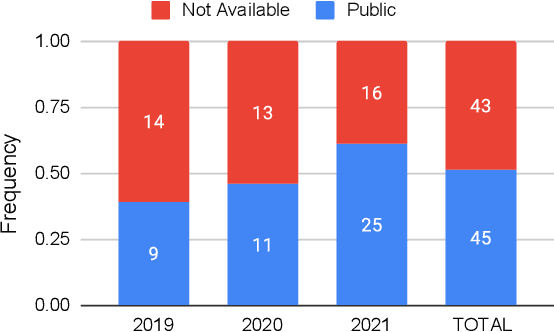
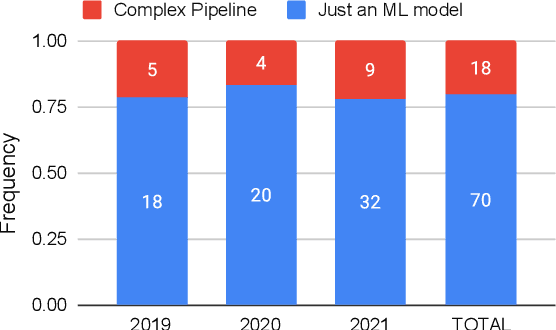
Recent years have seen a proliferation of research on adversarial machine learning. Numerous papers demonstrate powerful algorithmic attacks against a wide variety of machine learning (ML) models, and numerous other papers propose defenses that can withstand most attacks. However, abundant real-world evidence suggests that actual attackers use simple tactics to subvert ML-driven systems, and as a result security practitioners have not prioritized adversarial ML defenses. Motivated by the apparent gap between researchers and practitioners, this position paper aims to bridge the two domains. We first present three real-world case studies from which we can glean practical insights unknown or neglected in research. Next we analyze all adversarial ML papers recently published in top security conferences, highlighting positive trends and blind spots. Finally, we state positions on precise and cost-driven threat modeling, collaboration between industry and academia, and reproducible research. We believe that our positions, if adopted, will increase the real-world impact of future endeavours in adversarial ML, bringing both researchers and practitioners closer to their shared goal of improving the security of ML systems.