 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLens: Contrastive Captioning of Binary Functions using Ensemble Embedding
Sep 12, 2024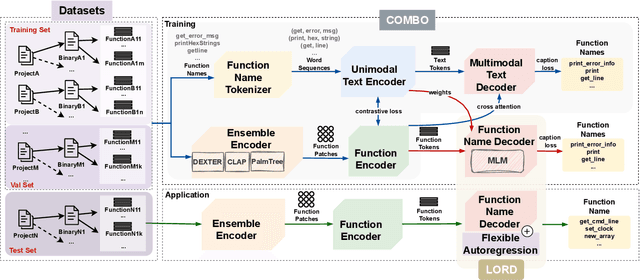

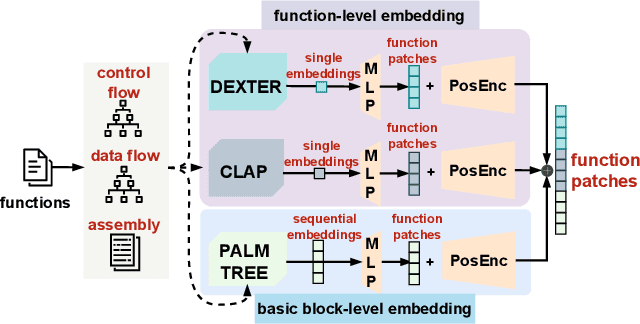

Function names can greatly aid human reverse engineers, which has spurred development of machine learning-based approaches to predicting function names in stripped binaries. Much current work in this area now uses transformers, applying a metaphor of machine translation from code to function names. Still, function naming models face challenges in generalizing to projects completely unrelated to the training set. In this paper, we take a completely new approach by transferring advances in automated image captioning to the domain of binary reverse engineering, such that different parts of a binary function can be associated with parts of its name. We propose BLens, which combines multiple binary function embeddings into a new ensemble representation, aligns it with the name representation latent space via a contrastive learning approach, and generates function names with a transformer architecture tailored for function names. In our experiments, we demonstrate that BLens significantly outperforms the state of the art. In the usual setting of splitting per binary, we achieve an $F_1$ score of 0.77 compared to 0.67. Moreover, in the cross-project setting, which emphasizes generalizability, we achieve an $F_1$ score of 0.46 compared to 0.29.
XFL: eXtreme Function Labeling
Jul 28, 2021

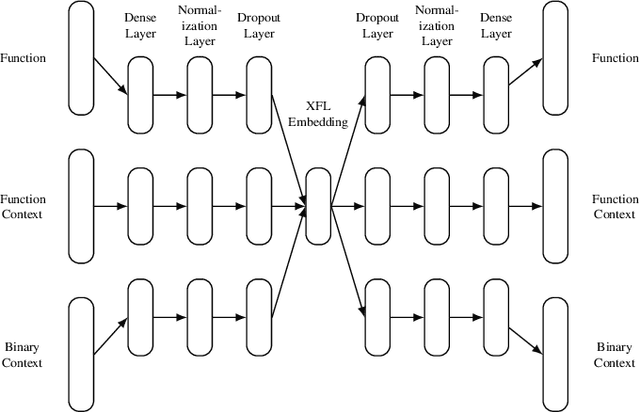

Reverse engineers would benefit from identifiers like function names, but these are usually unavailable in binaries. Training a machine learning model to predict function names automatically is promising but fundamentally hard due to the enormous number of classes. In this paper, we introduce eXtreme Function Labeling (XFL), an extreme multi-label learning approach to selecting appropriate labels for binary functions. XFL splits function names into tokens, treating each as an informative label akin to the problem of tagging texts in natural language. To capture the semantics of binary code, we introduce DEXTER, a novel function embedding that combines static analysis-based features with local context from the call graph and global context from the entire binary. We demonstrate that XFL outperforms state-of-the-art approaches to function labeling on a dataset of over 10,000 binaries from the Debian project, achieving a precision of 82.5%. We also study combinations of XFL with different published embeddings for binary functions and show that DEXTER consistently improves over the state of the art in information gain. As a result, we are able to show that binary function labeling is best phrased in terms of multi-label learning, and that binary function embeddings benefit from moving beyond just learning from syntax.