 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREPEAT: Improving Uncertainty Estimation in Representation Learning Explainability
Dec 11, 2024Incorporating uncertainty is crucial to provide trustworthy explanations of deep learning models. Recent works have demonstrated how uncertainty modeling can be particularly important in the unsupervised field of representation learning explainable artificial intelligence (R-XAI). Current R-XAI methods provide uncertainty by measuring variability in the importance score. However, they fail to provide meaningful estimates of whether a pixel is certainly important or not. In this work, we propose a new R-XAI method called REPEAT that addresses the key question of whether or not a pixel is \textit{certainly} important. REPEAT leverages the stochasticity of current R-XAI methods to produce multiple estimates of importance, thus considering each pixel in an image as a Bernoulli random variable that is either important or unimportant. From these Bernoulli random variables we can directly estimate the importance of a pixel and its associated certainty, thus enabling users to determine certainty in pixel importance. Our extensive evaluation shows that REPEAT gives certainty estimates that are more intuitive, better at detecting out-of-distribution data, and more concise.
Explaining time series models using frequency masking
Jun 19, 2024Time series data is fundamentally important for describing many critical domains such as healthcare, finance, and climate, where explainable models are necessary for safe automated decision-making. To develop eXplainable AI (XAI) in these domains therefore implies explaining salient information in the time series. Current methods for obtaining saliency maps assumes localized information in the raw input space. In this paper, we argue that the salient information of a number of time series is more likely to be localized in the frequency domain. We propose FreqRISE, which uses masking based methods to produce explanations in the frequency and time-frequency domain, which shows the best performance across a number of tasks.
View it like a radiologist: Shifted windows for deep learning augmentation of CT images
Nov 25, 2023Deep learning has the potential to revolutionize medical practice by automating and performing important tasks like detecting and delineating the size and locations of cancers in medical images. However, most deep learning models rely on augmentation techniques that treat medical images as natural images. For contrast-enhanced Computed Tomography (CT) images in particular, the signals producing the voxel intensities have physical meaning, which is lost during preprocessing and augmentation when treating such images as natural images. To address this, we propose a novel preprocessing and intensity augmentation scheme inspired by how radiologists leverage multiple viewing windows when evaluating CT images. Our proposed method, window shifting, randomly places the viewing windows around the region of interest during training. This approach improves liver lesion segmentation performance and robustness on images with poorly timed contrast agent. Our method outperforms classical intensity augmentations as well as the intensity augmentation pipeline of the popular nn-UNet on multiple datasets.
* 6 pages, 3 figures, accepted to MLSP 2023
The Meta-Evaluation Problem in Explainable AI: Identifying Reliable Estimators with MetaQuantus
Feb 14, 2023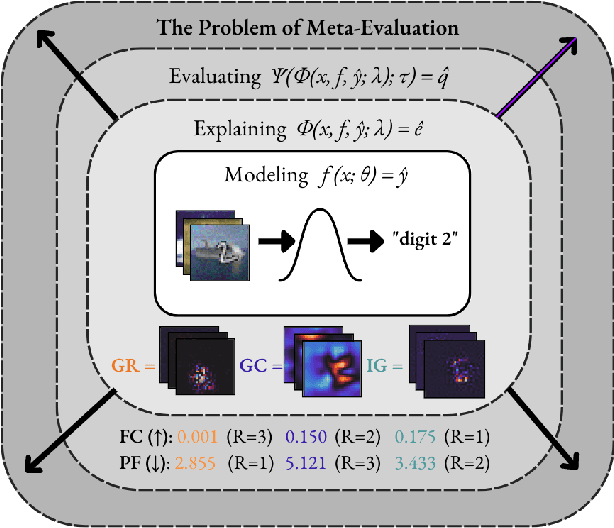



Explainable AI (XAI) is a rapidly evolving field that aims to improve transparency and trustworthiness of AI systems to humans. One of the unsolved challenges in XAI is estimating the performance of these explanation methods for neural networks, which has resulted in numerous competing metrics with little to no indication of which one is to be preferred. In this paper, to identify the most reliable evaluation method in a given explainability context, we propose MetaQuantus -- a simple yet powerful framework that meta-evaluates two complementary performance characteristics of an evaluation method: its resilience to noise and reactivity to randomness. We demonstrate the effectiveness of our framework through a series of experiments, targeting various open questions in XAI, such as the selection of explanation methods and optimisation of hyperparameters of a given metric. We release our work under an open-source license to serve as a development tool for XAI researchers and Machine Learning (ML) practitioners to verify and benchmark newly constructed metrics (i.e., ``estimators'' of explanation quality). With this work, we provide clear and theoretically-grounded guidance for building reliable evaluation methods, thus facilitating standardisation and reproducibility in the field of XAI.
RELAX: Representation Learning Explainability
Dec 19, 2021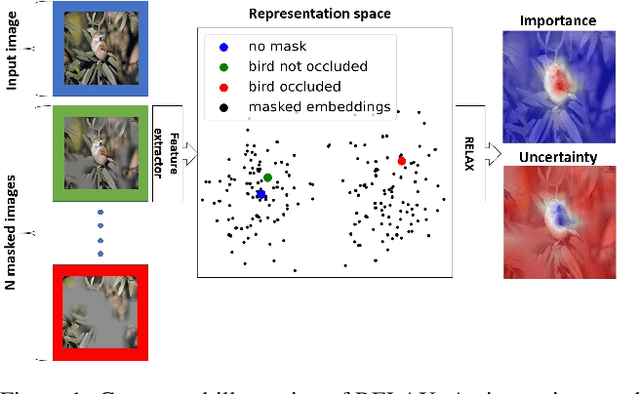

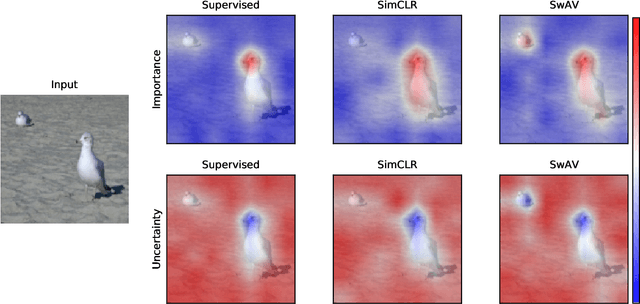
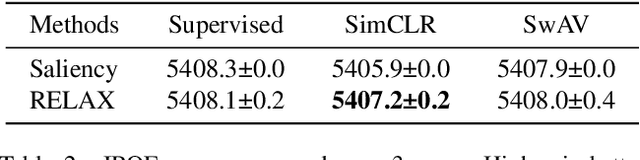
Despite the significant improvements that representation learning via self-supervision has led to when learning from unlabeled data, no methods exist that explain what influences the learned representation. We address this need through our proposed approach, RELAX, which is the first approach for attribution-based explanations of representations. Our approach can also model the uncertainty in its explanations, which is essential to produce trustworthy explanations. RELAX explains representations by measuring similarities in the representation space between an input and masked out versions of itself, providing intuitive explanations and significantly outperforming the gradient-based baseline. We provide theoretical interpretations of RELAX and conduct a novel analysis of feature extractors trained using supervised and unsupervised learning, providing insights into different learning strategies. Finally, we illustrate the usability of RELAX in multi-view clustering and highlight that incorporating uncertainty can be essential for providing low-complexity explanations, taking a crucial step towards explaining representations.