 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRELAX: Representation Learning Explainability
Paper and Code
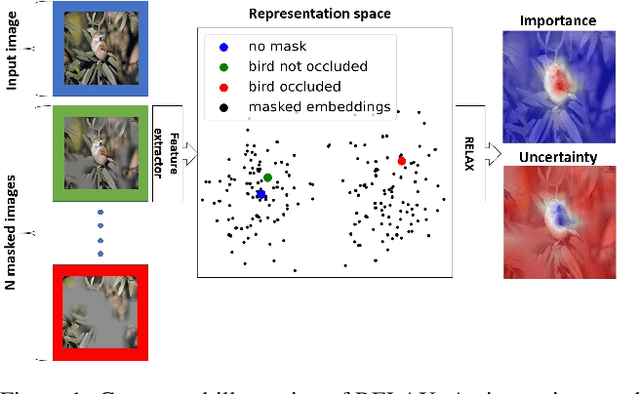

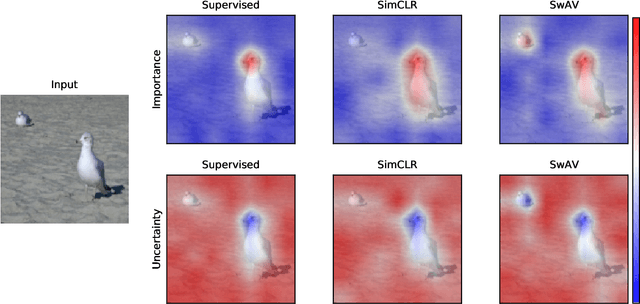
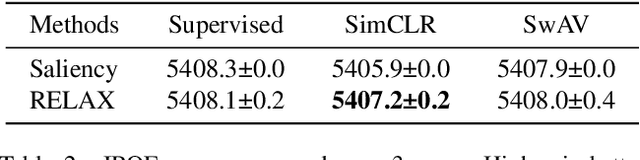
Despite the significant improvements that representation learning via self-supervision has led to when learning from unlabeled data, no methods exist that explain what influences the learned representation. We address this need through our proposed approach, RELAX, which is the first approach for attribution-based explanations of representations. Our approach can also model the uncertainty in its explanations, which is essential to produce trustworthy explanations. RELAX explains representations by measuring similarities in the representation space between an input and masked out versions of itself, providing intuitive explanations and significantly outperforming the gradient-based baseline. We provide theoretical interpretations of RELAX and conduct a novel analysis of feature extractors trained using supervised and unsupervised learning, providing insights into different learning strategies. Finally, we illustrate the usability of RELAX in multi-view clustering and highlight that incorporating uncertainty can be essential for providing low-complexity explanations, taking a crucial step towards explaining representations.