 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effects of Self-supervision and Contrastive Alignment in Deep Multi-view Clustering
Mar 17, 2023



Self-supervised learning is a central component in recent approaches to deep multi-view clustering (MVC). However, we find large variations in the development of self-supervision-based methods for deep MVC, potentially slowing the progress of the field. To address this, we present DeepMVC, a unified framework for deep MVC that includes many recent methods as instances. We leverage our framework to make key observations about the effect of self-supervision, and in particular, drawbacks of aligning representations with contrastive learning. Further, we prove that contrastive alignment can negatively influence cluster separability, and that this effect becomes worse when the number of views increases. Motivated by our findings, we develop several new DeepMVC instances with new forms of self-supervision. We conduct extensive experiments and find that (i) in line with our theoretical findings, contrastive alignments decreases performance on datasets with many views; (ii) all methods benefit from some form of self-supervision; and (iii) our new instances outperform previous methods on several datasets. Based on our results, we suggest several promising directions for future research. To enhance the openness of the field, we provide an open-source implementation of DeepMVC, including recent models and our new instances. Our implementation includes a consistent evaluation protocol, facilitating fair and accurate evaluation of methods and components.
Hubs and Hyperspheres: Reducing Hubness and Improving Transductive Few-shot Learning with Hyperspherical Embeddings
Mar 16, 2023



Distance-based classification is frequently used in transductive few-shot learning (FSL). However, due to the high-dimensionality of image representations, FSL classifiers are prone to suffer from the hubness problem, where a few points (hubs) occur frequently in multiple nearest neighbour lists of other points. Hubness negatively impacts distance-based classification when hubs from one class appear often among the nearest neighbors of points from another class, degrading the classifier's performance. To address the hubness problem in FSL, we first prove that hubness can be eliminated by distributing representations uniformly on the hypersphere. We then propose two new approaches to embed representations on the hypersphere, which we prove optimize a tradeoff between uniformity and local similarity preservation -- reducing hubness while retaining class structure. Our experiments show that the proposed methods reduce hubness, and significantly improves transductive FSL accuracy for a wide range of classifiers.
RELAX: Representation Learning Explainability
Dec 19, 2021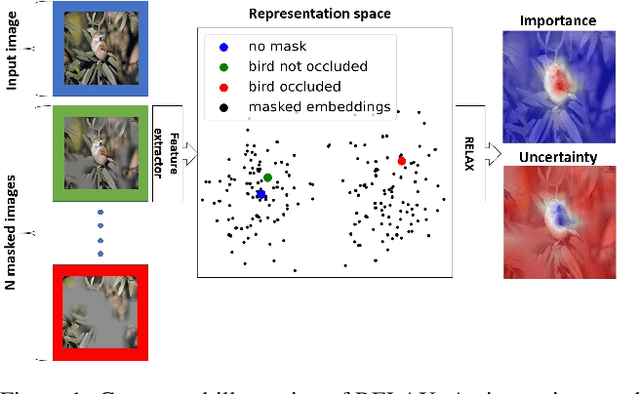

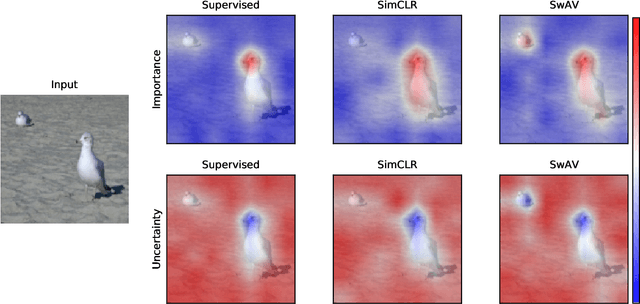
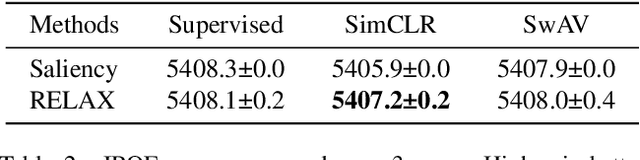
Despite the significant improvements that representation learning via self-supervision has led to when learning from unlabeled data, no methods exist that explain what influences the learned representation. We address this need through our proposed approach, RELAX, which is the first approach for attribution-based explanations of representations. Our approach can also model the uncertainty in its explanations, which is essential to produce trustworthy explanations. RELAX explains representations by measuring similarities in the representation space between an input and masked out versions of itself, providing intuitive explanations and significantly outperforming the gradient-based baseline. We provide theoretical interpretations of RELAX and conduct a novel analysis of feature extractors trained using supervised and unsupervised learning, providing insights into different learning strategies. Finally, we illustrate the usability of RELAX in multi-view clustering and highlight that incorporating uncertainty can be essential for providing low-complexity explanations, taking a crucial step towards explaining representations.
Reconsidering Representation Alignment for Multi-view Clustering
Mar 13, 2021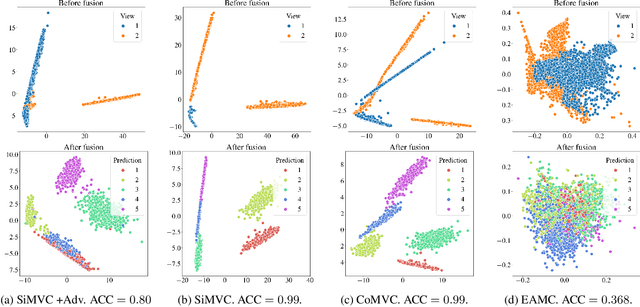
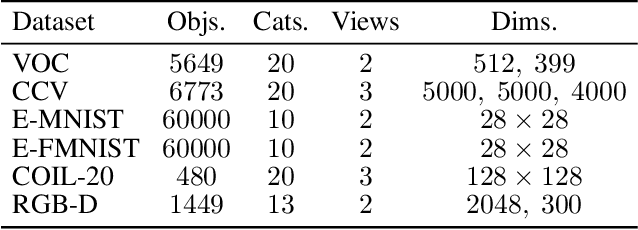
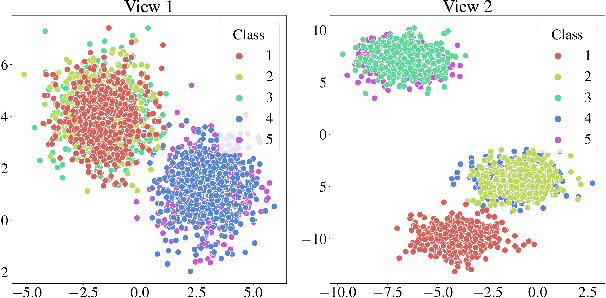
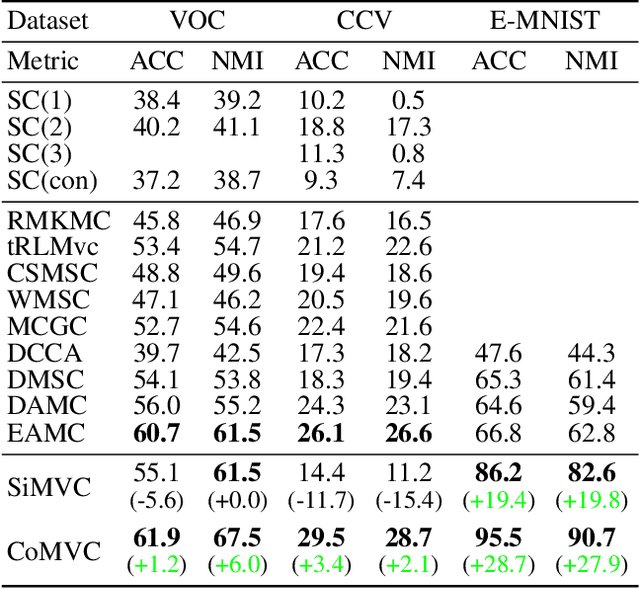
Aligning distributions of view representations is a core component of today's state of the art models for deep multi-view clustering. However, we identify several drawbacks with na\"ively aligning representation distributions. We demonstrate that these drawbacks both lead to less separable clusters in the representation space, and inhibit the model's ability to prioritize views. Based on these observations, we develop a simple baseline model for deep multi-view clustering. Our baseline model avoids representation alignment altogether, while performing similar to, or better than, the current state of the art. We also expand our baseline model by adding a contrastive learning component. This introduces a selective alignment procedure that preserves the model's ability to prioritize views. Our experiments show that the contrastive learning component enhances the baseline model, improving on the current state of the art by a large margin on several datasets.
Deep Image Clustering with Tensor Kernels and Unsupervised Companion Objectives
Jan 20, 2020
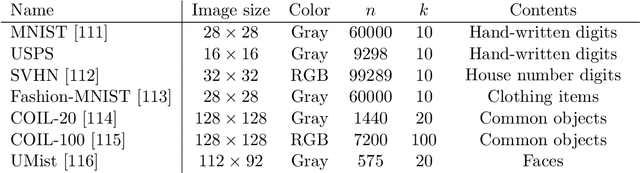
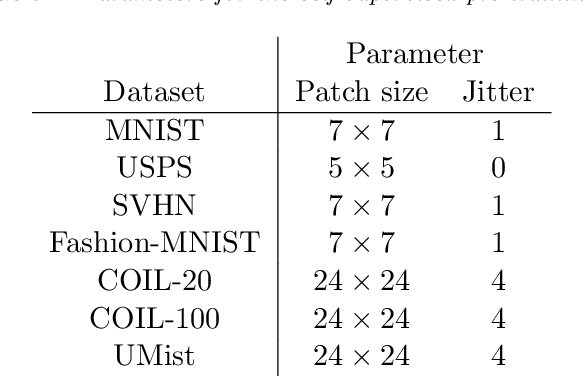
In this paper we develop a new model for deep image clustering, using convolutional neural networks and tensor kernels. The proposed Deep Tensor Kernel Clustering (DTKC) consists of a convolutional neural network (CNN), which is trained to reflect a common cluster structure at the output of its intermediate layers. Encouraging a consistent cluster structure throughout the network has the potential to guide it towards meaningful clusters, even though these clusters might appear to be nonlinear in the input space. The cluster structure is enforced through the idea of unsupervised companion objectives, where separate loss functions are attached to layers in the network. These unsupervised companion objectives are constructed based on a proposed generalization of the Cauchy-Schwarz (CS) divergence, from vectors to tensors of arbitrary rank. Generalizing the CS divergence to tensor-valued data is a crucial step, due to the tensorial nature of the intermediate representations in the CNN. Several experiments are conducted to thoroughly assess the performance of the proposed DTKC model. The results indicate that the model outperforms, or performs comparable to, a wide range of baseline algorithms. We also empirically demonstrate that our model does not suffer from objective function mismatch, which can be a problematic artifact in autoencoder-based clustering models.
Recurrent Deep Divergence-based Clustering for simultaneous feature learning and clustering of variable length time series
Nov 29, 2018
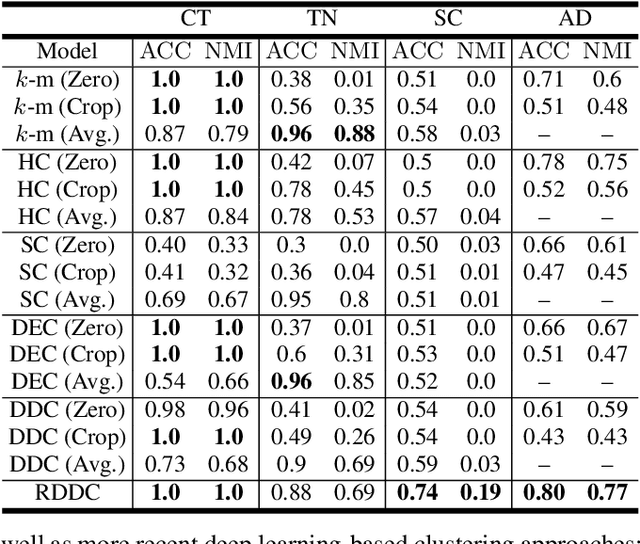
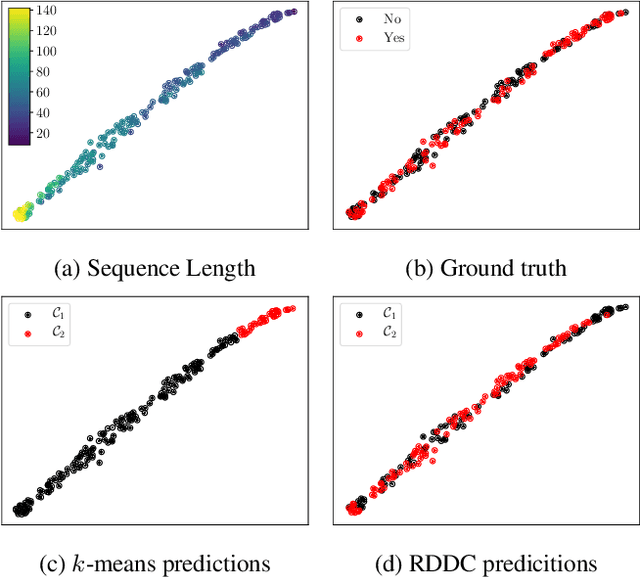

The task of clustering unlabeled time series and sequences entails a particular set of challenges, namely to adequately model temporal relations and variable sequence lengths. If these challenges are not properly handled, the resulting clusters might be of suboptimal quality. As a key solution, we present a joint clustering and feature learning framework for time series based on deep learning. For a given set of time series, we train a recurrent network to represent, or embed, each time series in a vector space such that a divergence-based clustering loss function can discover the underlying cluster structure in an end-to-end manner. Unlike previous approaches, our model inherently handles multivariate time series of variable lengths and does not require specification of a distance-measure in the input space. On a diverse set of benchmark datasets we illustrate that our proposed Recurrent Deep Divergence-based Clustering approach outperforms, or performs comparable to, previous approaches.