 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining time series models using frequency masking
Jun 19, 2024Time series data is fundamentally important for describing many critical domains such as healthcare, finance, and climate, where explainable models are necessary for safe automated decision-making. To develop eXplainable AI (XAI) in these domains therefore implies explaining salient information in the time series. Current methods for obtaining saliency maps assumes localized information in the raw input space. In this paper, we argue that the salient information of a number of time series is more likely to be localized in the frequency domain. We propose FreqRISE, which uses masking based methods to produce explanations in the frequency and time-frequency domain, which shows the best performance across a number of tasks.
Multi-view self-supervised learning for multivariate variable-channel time series
Jul 20, 2023



Labeling of multivariate biomedical time series data is a laborious and expensive process. Self-supervised contrastive learning alleviates the need for large, labeled datasets through pretraining on unlabeled data. However, for multivariate time series data, the set of input channels often varies between applications, and most existing work does not allow for transfer between datasets with different sets of input channels. We propose learning one encoder to operate on all input channels individually. We then use a message passing neural network to extract a single representation across channels. We demonstrate the potential of this method by pretraining our model on a dataset with six EEG channels and then fine-tuning it on a dataset with two different EEG channels. We compare models with and without the message passing neural network across different contrastive loss functions. We show that our method, combined with the TS2Vec loss, outperforms all other methods in most settings.
Synthetic data shuffling accelerates the convergence of federated learning under data heterogeneity
Jun 23, 2023In federated learning, data heterogeneity is a critical challenge. A straightforward solution is to shuffle the clients' data to homogenize the distribution. However, this may violate data access rights, and how and when shuffling can accelerate the convergence of a federated optimization algorithm is not theoretically well understood. In this paper, we establish a precise and quantifiable correspondence between data heterogeneity and parameters in the convergence rate when a fraction of data is shuffled across clients. We prove that shuffling can quadratically reduce the gradient dissimilarity with respect to the shuffling percentage, accelerating convergence. Inspired by the theory, we propose a practical approach that addresses the data access rights issue by shuffling locally generated synthetic data. The experimental results show that shuffling synthetic data improves the performance of multiple existing federated learning algorithms by a large margin.
Partial Variance Reduction improves Non-Convex Federated learning on heterogeneous data
Dec 05, 2022Data heterogeneity across clients is a key challenge in federated learning. Prior works address this by either aligning client and server models or using control variates to correct client model drift. Although these methods achieve fast convergence in convex or simple non-convex problems, the performance in over-parameterized models such as deep neural networks is lacking. In this paper, we first revisit the widely used FedAvg algorithm in a deep neural network to understand how data heterogeneity influences the gradient updates across the neural network layers. We observe that while the feature extraction layers are learned efficiently by FedAvg, the substantial diversity of the final classification layers across clients impedes the performance. Motivated by this, we propose to correct model drift by variance reduction only on the final layers. We demonstrate that this significantly outperforms existing benchmarks at a similar or lower communication cost. We furthermore provide proof for the convergence rate of our algorithm.
Raman Spectrum Matching with Contrastive Representation Learning
Feb 25, 2022
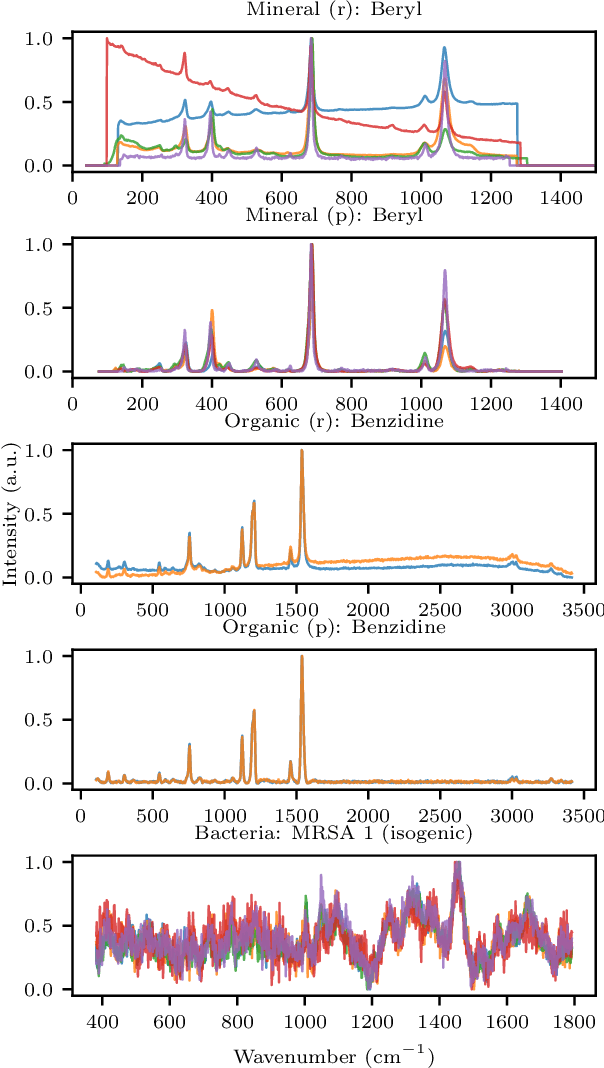


Raman spectroscopy is an effective, low-cost, non-intrusive technique often used for chemical identification. Typical approaches are based on matching observations to a reference database, which requires careful preprocessing, or supervised machine learning, which requires a fairly large number of training observations from each class. We propose a new machine learning technique for Raman spectrum matching, based on contrastive representation learning, that requires no preprocessing and works with as little as a single reference spectrum from each class. On three datasets we demonstrate that our approach significantly improves or is on par with the state of the art in prediction accuracy, and we show how to compute conformal prediction sets with specified frequentist coverage. Based on our findings, we believe contrastive representation learning is a promising alternative to existing methods for Raman spectrum matching.