 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-View Cross-Modal Unsupervised Domain Adaptation for Driver Monitoring System
Nov 15, 2025


Driver distraction remains a leading cause of road traffic accidents, contributing to thousands of fatalities annually across the globe. While deep learning-based driver activity recognition methods have shown promise in detecting such distractions, their effectiveness in real-world deployments is hindered by two critical challenges: variations in camera viewpoints (cross-view) and domain shifts such as change in sensor modality or environment. Existing methods typically address either cross-view generalization or unsupervised domain adaptation in isolation, leaving a gap in the robust and scalable deployment of models across diverse vehicle configurations. In this work, we propose a novel two-phase cross-view, cross-modal unsupervised domain adaptation framework that addresses these challenges jointly on real-time driver monitoring data. In the first phase, we learn view-invariant and action-discriminative features within a single modality using contrastive learning on multi-view data. In the second phase, we perform domain adaptation to a new modality using information bottleneck loss without requiring any labeled data from the new domain. We evaluate our approach using state-of-the art video transformers (Video Swin, MViT) and multi modal driver activity dataset called Drive&Act, demonstrating that our joint framework improves top-1 accuracy on RGB video data by almost 50% compared to a supervised contrastive learning-based cross-view method, and outperforms unsupervised domain adaptation-only methods by up to 5%, using the same video transformer backbone.
CoLa-DCE -- Concept-guided Latent Diffusion Counterfactual Explanations
Jun 03, 2024



Recent advancements in generative AI have introduced novel prospects and practical implementations. Especially diffusion models show their strength in generating diverse and, at the same time, realistic features, positioning them well for generating counterfactual explanations for computer vision models. Answering "what if" questions of what needs to change to make an image classifier change its prediction, counterfactual explanations align well with human understanding and consequently help in making model behavior more comprehensible. Current methods succeed in generating authentic counterfactuals, but lack transparency as feature changes are not directly perceivable. To address this limitation, we introduce Concept-guided Latent Diffusion Counterfactual Explanations (CoLa-DCE). CoLa-DCE generates concept-guided counterfactuals for any classifier with a high degree of control regarding concept selection and spatial conditioning. The counterfactuals comprise an increased granularity through minimal feature changes. The reference feature visualization ensures better comprehensibility, while the feature localization provides increased transparency of "where" changed "what". We demonstrate the advantages of our approach in minimality and comprehensibility across multiple image classification models and datasets and provide insights into how our CoLa-DCE explanations help comprehend model errors like misclassification cases.
Locally Testing Model Detections for Semantic Global Concepts
May 29, 2024Ensuring the quality of black-box Deep Neural Networks (DNNs) has become ever more significant, especially in safety-critical domains such as automated driving. While global concept encodings generally enable a user to test a model for a specific concept, linking global concept encodings to the local processing of single network inputs reveals their strengths and limitations. Our proposed framework global-to-local Concept Attribution (glCA) uses approaches from local (why a specific prediction originates) and global (how a model works generally) eXplainable Artificial Intelligence (xAI) to test DNNs for a predefined semantical concept locally. The approach allows for conditioning local, post-hoc explanations on predefined semantic concepts encoded as linear directions in the model's latent space. Pixel-exact scoring concerning the global concept usage assists the tester in further understanding the model processing of single data points for the selected concept. Our approach has the advantage of fully covering the model-internal encoding of the semantic concept and allowing the localization of relevant concept-related information. The results show major differences in the local perception and usage of individual global concept encodings and demand for further investigations regarding obtaining thorough semantic concept encodings.
GCPV: Guided Concept Projection Vectors for the Explainable Inspection of CNN Feature Spaces
Nov 24, 2023



For debugging and verification of computer vision convolutional deep neural networks (CNNs) human inspection of the learned latent representations is imperative. Therefore, state-of-the-art eXplainable Artificial Intelligence (XAI) methods globally associate given natural language semantic concepts with representing vectors or regions in the CNN latent space supporting manual inspection. Yet, this approach comes with two major disadvantages: They are locally inaccurate when reconstructing a concept label and discard information about the distribution of concept instance representations. The latter, though, is of particular interest for debugging, like finding and understanding outliers, learned notions of sub-concepts, and concept confusion. Furthermore, current single-layer approaches neglect that information about a concept may be spread over the CNN depth. To overcome these shortcomings, we introduce the local-to-global Guided Concept Projection Vectors (GCPV) approach: It (1) generates local concept vectors that each precisely reconstruct a concept segmentation label, and then (2) generalizes these to global concept and even sub-concept vectors by means of hiearchical clustering. Our experiments on object detectors demonstrate improved performance compared to the state-of-the-art, the benefit of multi-layer concept vectors, and robustness against low-quality concept segmentation labels. Finally, we demonstrate that GCPVs can be applied to find root causes for confusion of concepts like bus and truck, and reveal interesting concept-level outliers. Thus, GCPVs pose a promising step towards interpretable model debugging and informed data improvement.
Quantified Semantic Comparison of Convolutional Neural Networks
Apr 30, 2023



The state-of-the-art in convolutional neural networks (CNNs) for computer vision excels in performance, while remaining opaque. But due to safety regulations for safety-critical applications, like perception for automated driving, the choice of model should also take into account how candidate models represent semantic information for model transparency reasons. To tackle this yet unsolved problem, our work proposes two methods for quantifying the similarity between semantic information in CNN latent spaces. These allow insights into both the flow and similarity of semantic information within CNN layers, and into the degree of their similitude between different networks. As a basis, we use renown techniques from the field of explainable artificial intelligence (XAI), which are used to obtain global vector representations of semantic concepts in each latent space. These are compared with respect to their activation on test inputs. When applied to three diverse object detectors and two datasets, our methods reveal the findings that (1) similar semantic concepts are learned \emph{regardless of the CNN architecture}, and (2) similar concepts emerge in similar \emph{relative} layer depth, independent of the total number of layers. Finally, our approach poses a promising step towards informed model selection and comprehension of how CNNs process semantic information.
Evaluating the Stability of Semantic Concept Representations in CNNs for Robust Explainability
Apr 28, 2023



Analysis of how semantic concepts are represented within Convolutional Neural Networks (CNNs) is a widely used approach in Explainable Artificial Intelligence (XAI) for interpreting CNNs. A motivation is the need for transparency in safety-critical AI-based systems, as mandated in various domains like automated driving. However, to use the concept representations for safety-relevant purposes, like inspection or error retrieval, these must be of high quality and, in particular, stable. This paper focuses on two stability goals when working with concept representations in computer vision CNNs: stability of concept retrieval and of concept attribution. The guiding use-case is a post-hoc explainability framework for object detection (OD) CNNs, towards which existing concept analysis (CA) methods are successfully adapted. To address concept retrieval stability, we propose a novel metric that considers both concept separation and consistency, and is agnostic to layer and concept representation dimensionality. We then investigate impacts of concept abstraction level, number of concept training samples, CNN size, and concept representation dimensionality on stability. For concept attribution stability we explore the effect of gradient instability on gradient-based explainability methods. The results on various CNNs for classification and object detection yield the main findings that (1) the stability of concept retrieval can be enhanced through dimensionality reduction via data aggregation, and (2) in shallow layers where gradient instability is more pronounced, gradient smoothing techniques are advised. Finally, our approach provides valuable insights into selecting the appropriate layer and concept representation dimensionality, paving the way towards CA in safety-critical XAI applications.
Knowledge Augmented Machine Learning with Applications in Autonomous Driving: A Survey
May 10, 2022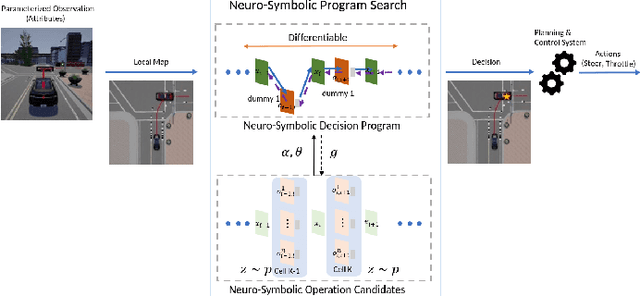
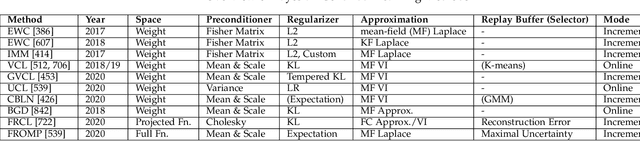
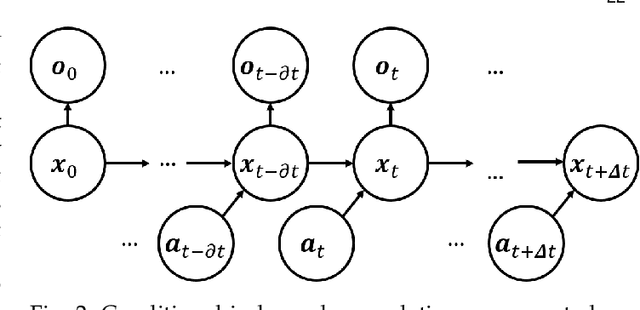
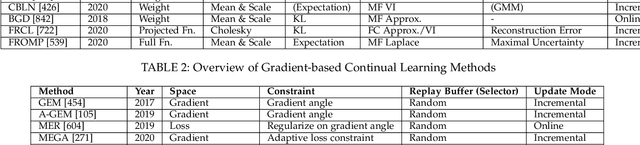
The existence of representative datasets is a prerequisite of many successful artificial intelligence and machine learning models. However, the subsequent application of these models often involves scenarios that are inadequately represented in the data used for training. The reasons for this are manifold and range from time and cost constraints to ethical considerations. As a consequence, the reliable use of these models, especially in safety-critical applications, is a huge challenge. Leveraging additional, already existing sources of knowledge is key to overcome the limitations of purely data-driven approaches, and eventually to increase the generalization capability of these models. Furthermore, predictions that conform with knowledge are crucial for making trustworthy and safe decisions even in underrepresented scenarios. This work provides an overview of existing techniques and methods in the literature that combine data-based models with existing knowledge. The identified approaches are structured according to the categories integration, extraction and conformity. Special attention is given to applications in the field of autonomous driving.
Artificial Intelligence Methods in In-Cabin Use Cases: A Survey
Jan 06, 2021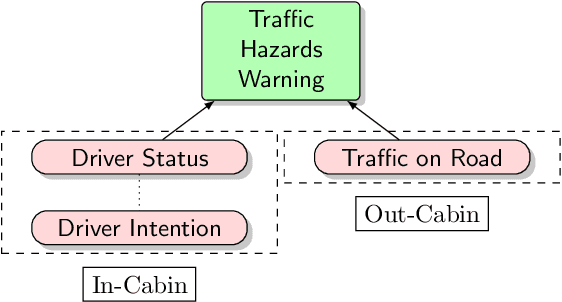
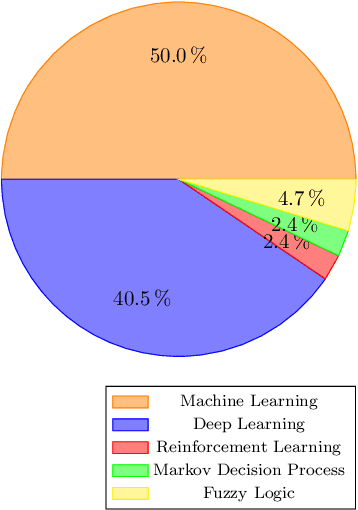
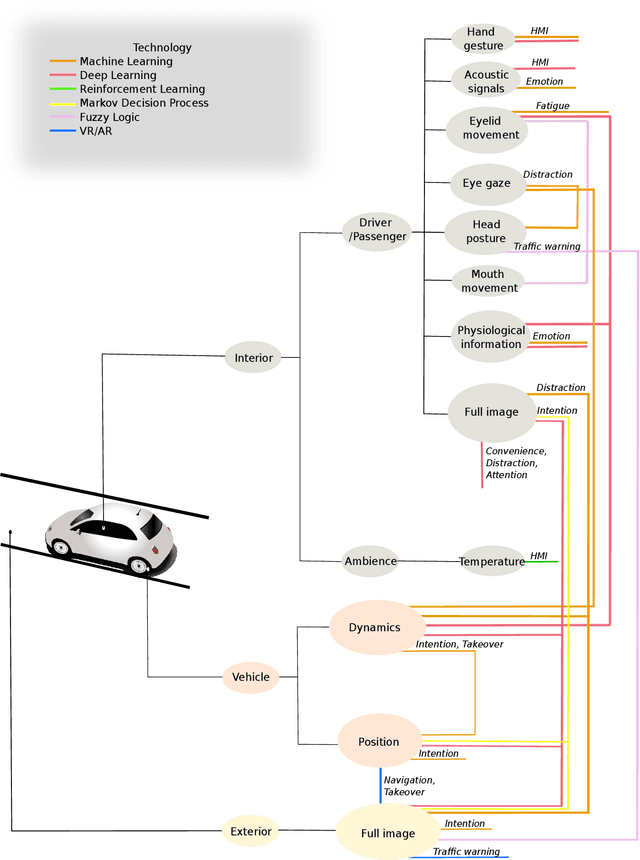
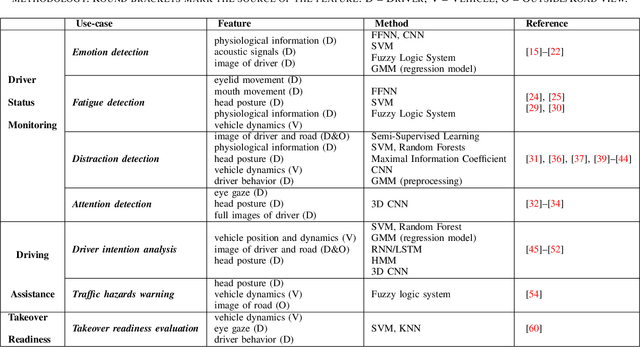
As interest in autonomous driving increases, efforts are being made to meet requirements for the high-level automation of vehicles. In this context, the functionality inside the vehicle cabin plays a key role in ensuring a safe and pleasant journey for driver and passenger alike. At the same time, recent advances in the field of artificial intelligence (AI) have enabled a whole range of new applications and assistance systems to solve automated problems in the vehicle cabin. This paper presents a thorough survey on existing work that utilizes AI methods for use-cases inside the driving cabin, focusing, in particular, on application scenarios related to (1) driving safety and (2) driving comfort. Results from the surveyed works show that AI technology has a promising future in tackling in-cabin tasks within the autonomous driving aspect.