 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiT-4-RSVQA: Lightweight Transformer-based Visual Question Answering in Remote Sensing
Jun 02, 2023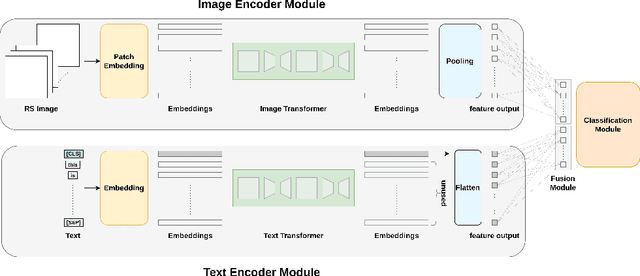
Visual question answering (VQA) methods in remote sensing (RS) aim to answer natural language questions with respect to an RS image. Most of the existing methods require a large amount of computational resources, which limits their application in operational scenarios in RS. To address this issue, in this paper we present an effective lightweight transformer-based VQA in RS (LiT-4-RSVQA) architecture for efficient and accurate VQA in RS. Our architecture consists of: i) a lightweight text encoder module; ii) a lightweight image encoder module; iii) a fusion module; and iv) a classification module. The experimental results obtained on a VQA benchmark dataset demonstrate that our proposed LiT-4-RSVQA architecture provides accurate VQA results while significantly reducing the computational requirements on the executing hardware. Our code is publicly available at https://git.tu-berlin.de/rsim/lit4rsvqa.
Multi-Modal Fusion Transformer for Visual Question Answering in Remote Sensing
Oct 10, 2022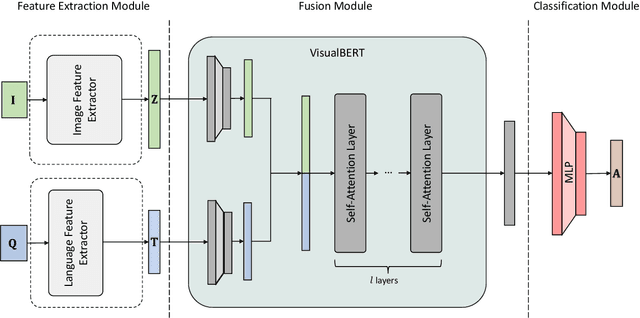
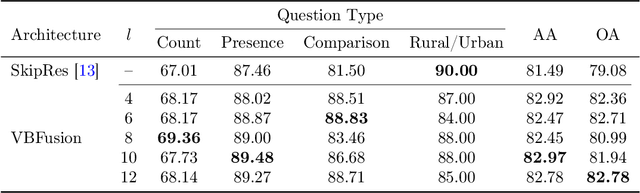
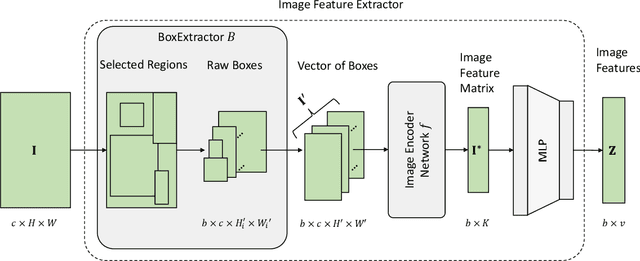
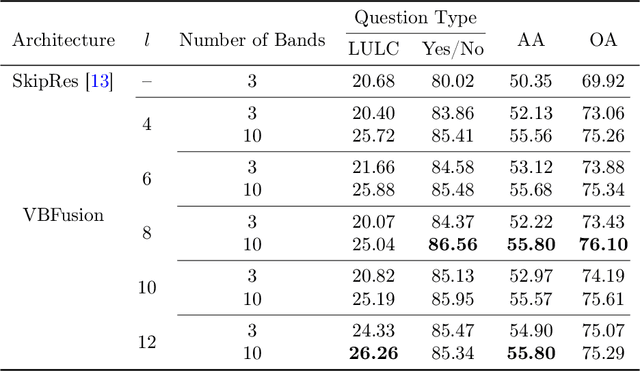
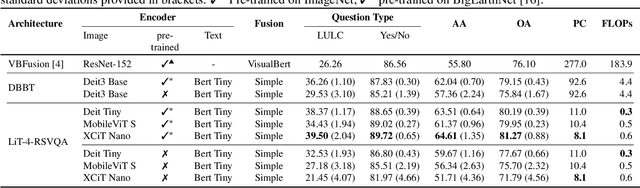
With the new generation of satellite technologies, the archives of remote sensing (RS) images are growing very fast. To make the intrinsic information of each RS image easily accessible, visual question answering (VQA) has been introduced in RS. VQA allows a user to formulate a free-form question concerning the content of RS images to extract generic information. It has been shown that the fusion of the input modalities (i.e., image and text) is crucial for the performance of VQA systems. Most of the current fusion approaches use modality-specific representations in their fusion modules instead of joint representation learning. However, to discover the underlying relation between both the image and question modality, the model is required to learn the joint representation instead of simply combining (e.g., concatenating, adding, or multiplying) the modality-specific representations. We propose a multi-modal transformer-based architecture to overcome this issue. Our proposed architecture consists of three main modules: i) the feature extraction module for extracting the modality-specific features; ii) the fusion module, which leverages a user-defined number of multi-modal transformer layers of the VisualBERT model (VB); and iii) the classification module to obtain the answer. Experimental results obtained on the RSVQAxBEN and RSVQA-LR datasets (which are made up of RGB bands of Sentinel-2 images) demonstrate the effectiveness of VBFusion for VQA tasks in RS. To analyze the importance of using other spectral bands for the description of the complex content of RS images in the framework of VQA, we extend the RSVQAxBEN dataset to include all the spectral bands of Sentinel-2 images with 10m and 20m spatial resolution.
Advanced Deep Learning Architectures for Accurate Detection of Subsurface Tile Drainage Pipes from Remote Sensing Images
Oct 06, 2022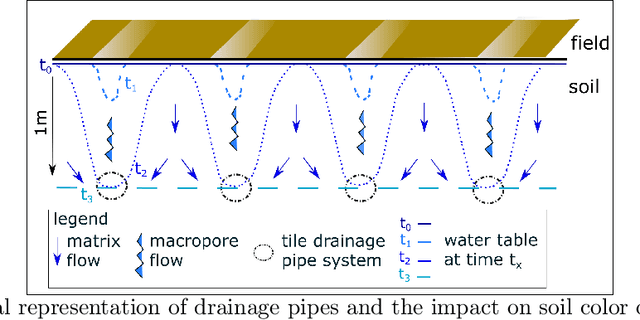
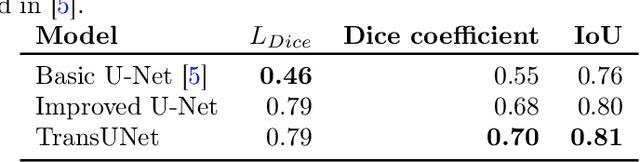
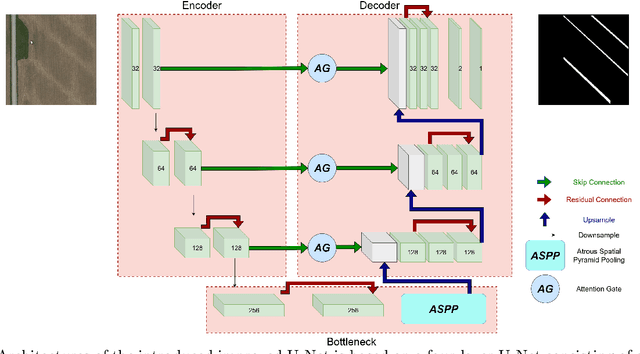
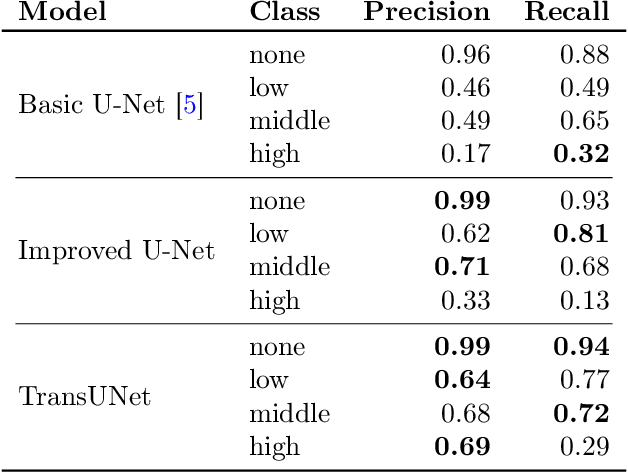
Subsurface tile drainage pipes provide agronomic, economic and environmental benefits. By lowering the water table of wet soils, they improve the aeration of plant roots and ultimately increase the productivity of farmland. They do however also provide an entryway of agrochemicals into subsurface water bodies and increase nutrition loss in soils. For maintenance and infrastructural development, accurate maps of tile drainage pipe locations and drained agricultural land are needed. However, these maps are often outdated or not present. Different remote sensing (RS) image processing techniques have been applied over the years with varying degrees of success to overcome these restrictions. Recent developments in deep learning (DL) techniques improve upon the conventional techniques with machine learning segmentation models. In this study, we introduce two DL-based models: i) improved U-Net architecture; and ii) Visual Transformer-based encoder-decoder in the framework of tile drainage pipe detection. Experimental results confirm the effectiveness of both models in terms of detection accuracy when compared to a basic U-Net architecture. Our code and models are publicly available at https://git.tu-berlin.de/rsim/drainage-pipes-detection.
On the Effects of Different Types of Label Noise in Multi-Label Remote Sensing Image Classification
Jul 28, 2022


The development of accurate methods for multi-label classification (MLC) of remote sensing (RS) images is one of the most important research topics in RS. To address MLC problems, the use of deep neural networks that require a high number of reliable training images annotated by multiple land-cover class labels (multi-labels) have been found popular in RS. However, collecting such annotations is time-consuming and costly. A common procedure to obtain annotations at zero labeling cost is to rely on thematic products or crowdsourced labels. As a drawback, these procedures come with the risk of label noise that can distort the learning process of the MLC algorithms. In the literature, most label noise robust methods are designed for single label classification (SLC) problems in computer vision (CV), where each image is annotated by a single label. Unlike SLC, label noise in MLC can be associated with: 1) subtractive label-noise (a land cover class label is not assigned to an image while that class is present in the image); 2) additive label-noise (a land cover class label is assigned to an image although that class is not present in the given image); and 3) mixed label-noise (a combination of both). In this paper, we investigate three different noise robust CV SLC methods and adapt them to be robust for multi-label noise scenarios in RS. During experiments we study the effects of different types of multi-label noise and evaluate the adapted methods rigorously. To this end, we also introduce a synthetic multi-label noise injection strategy that is more adequate to simulate operational scenarios compared to the uniform label noise injection strategy, in which the labels of absent and present classes are flipped at uniform probability. Further, we study the relevance of different evaluation metrics in MLC problems under noisy multi-labels.
Unsupervised Contrastive Hashing for Cross-Modal Retrieval in Remote Sensing
Apr 19, 2022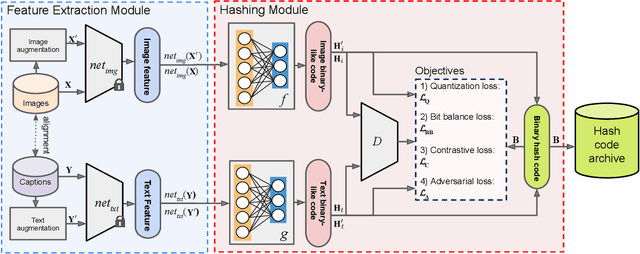
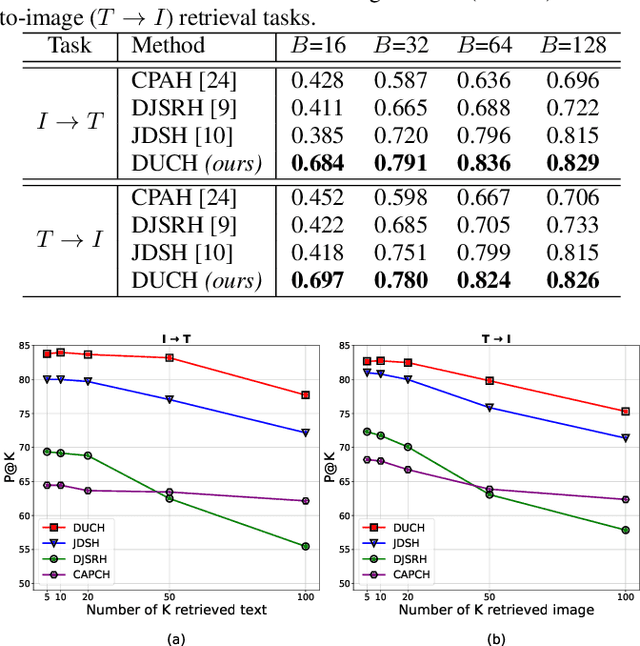

The development of cross-modal retrieval systems that can search and retrieve semantically relevant data across different modalities based on a query in any modality has attracted great attention in remote sensing (RS). In this paper, we focus our attention on cross-modal text-image retrieval, where queries from one modality (e.g., text) can be matched to archive entries from another (e.g., image). Most of the existing cross-modal text-image retrieval systems in RS require a high number of labeled training samples and also do not allow fast and memory-efficient retrieval. These issues limit the applicability of the existing cross-modal retrieval systems for large-scale applications in RS. To address this problem, in this paper we introduce a novel unsupervised cross-modal contrastive hashing (DUCH) method for text-image retrieval in RS. To this end, the proposed DUCH is made up of two main modules: 1) feature extraction module, which extracts deep representations of two modalities; 2) hashing module that learns to generate cross-modal binary hash codes from the extracted representations. We introduce a novel multi-objective loss function including: i) contrastive objectives that enable similarity preservation in intra- and inter-modal similarities; ii) an adversarial objective that is enforced across two modalities for cross-modal representation consistency; and iii) binarization objectives for generating hash codes. Experimental results show that the proposed DUCH outperforms state-of-the-art methods. Our code is publicly available at https://git.tu-berlin.de/rsim/duch.
An Unsupervised Cross-Modal Hashing Method Robust to Noisy Training Image-Text Correspondences in Remote Sensing
Feb 26, 2022
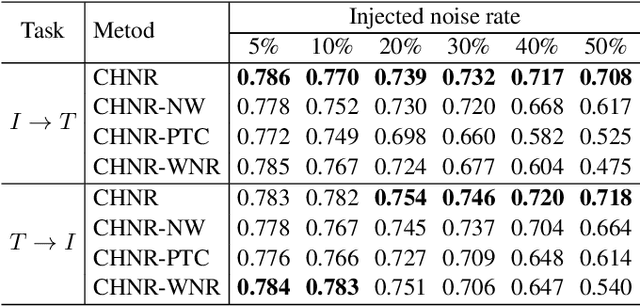
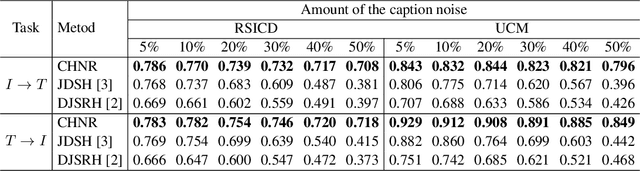
The development of accurate and scalable cross-modal image-text retrieval methods, where queries from one modality (e.g., text) can be matched to archive entries from another (e.g., remote sensing image) has attracted great attention in remote sensing (RS). Most of the existing methods assume that a reliable multi-modal training set with accurately matched text-image pairs is existing. However, this assumption may not always hold since the multi-modal training sets may include noisy pairs (i.e., textual descriptions/captions associated to training images can be noisy), distorting the learning process of the retrieval methods. To address this problem, we propose a novel unsupervised cross-modal hashing method robust to the noisy image-text correspondences (CHNR). CHNR consists of three modules: 1) feature extraction module, which extracts feature representations of image-text pairs; 2) noise detection module, which detects potential noisy correspondences; and 3) hashing module that generates cross-modal binary hash codes. The proposed CHNR includes two training phases: i) meta-learning phase that uses a small portion of clean (i.e., reliable) data to train the noise detection module in an adversarial fashion; and ii) the main training phase for which the trained noise detection module is used to identify noisy correspondences while the hashing module is trained on the noisy multi-modal training set. Experimental results show that the proposed CHNR outperforms state-of-the-art methods. Our code is publicly available at https://git.tu-berlin.de/rsim/chnr
Deep Unsupervised Contrastive Hashing for Large-Scale Cross-Modal Text-Image Retrieval in Remote Sensing
Jan 20, 2022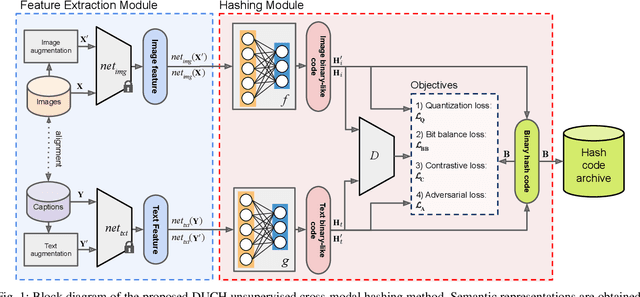
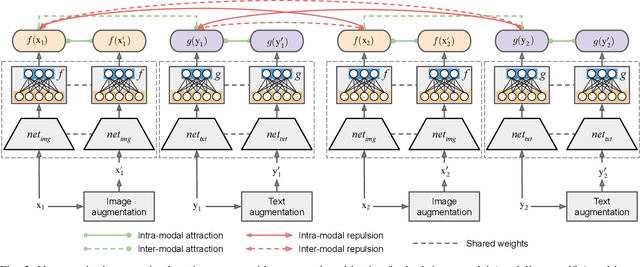

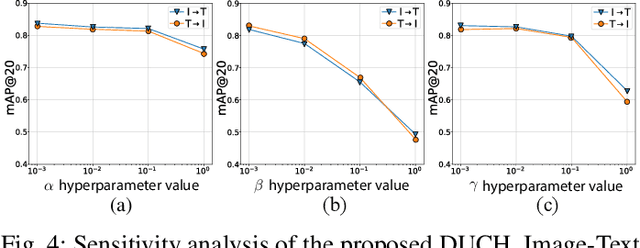
Due to the availability of large-scale multi-modal data (e.g., satellite images acquired by different sensors, text sentences, etc) archives, the development of cross-modal retrieval systems that can search and retrieve semantically relevant data across different modalities based on a query in any modality has attracted great attention in RS. In this paper, we focus our attention on cross-modal text-image retrieval, where queries from one modality (e.g., text) can be matched to archive entries from another (e.g., image). Most of the existing cross-modal text-image retrieval systems require a high number of labeled training samples and also do not allow fast and memory-efficient retrieval due to their intrinsic characteristics. These issues limit the applicability of the existing cross-modal retrieval systems for large-scale applications in RS. To address this problem, in this paper we introduce a novel deep unsupervised cross-modal contrastive hashing (DUCH) method for RS text-image retrieval. The proposed DUCH is made up of two main modules: 1) feature extraction module (which extracts deep representations of the text-image modalities); and 2) hashing module (which learns to generate cross-modal binary hash codes from the extracted representations). Within the hashing module, we introduce a novel multi-objective loss function including: i) contrastive objectives that enable similarity preservation in both intra- and inter-modal similarities; ii) an adversarial objective that is enforced across two modalities for cross-modal representation consistency; iii) binarization objectives for generating representative hash codes. Experimental results show that the proposed DUCH outperforms state-of-the-art unsupervised cross-modal hashing methods on two multi-modal (image and text) benchmark archives in RS. Our code is publicly available at https://git.tu-berlin.de/rsim/duch.
A Novel Uncertainty-aware Collaborative Learning Method for Remote Sensing Image Classification Under Multi-Label Noise
May 12, 2021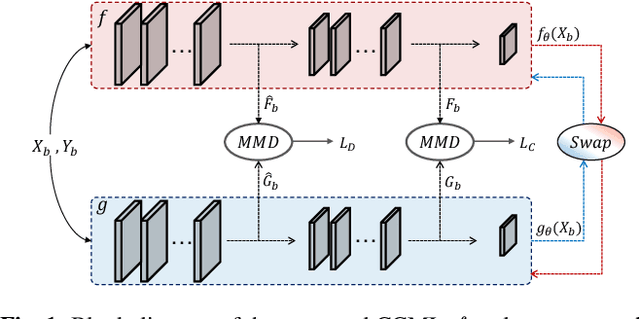
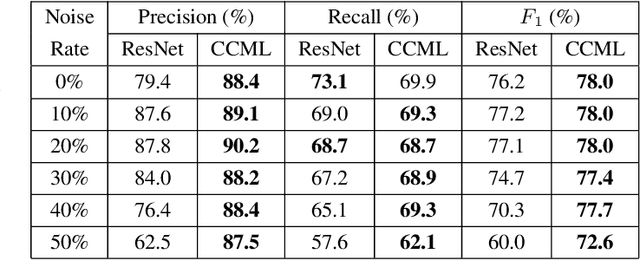
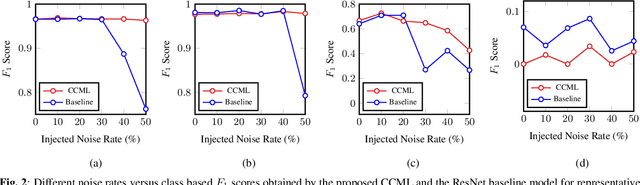
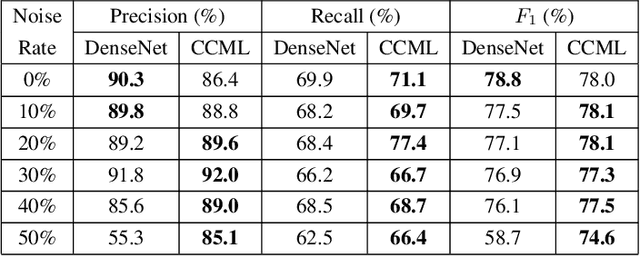
In remote sensing (RS), collecting a large number of reliable training images annotated by multiple land-cover class labels for multi-label classification (MLC) is time-consuming and costly. To address this problem, the publicly available thematic products are often used for annotating RS images with zero-labeling cost. However, in this case the training set can include noisy multi-labels that distort the learning process, resulting in inaccurate predictions. This paper proposes an architect-independent Consensual Collaborative Multi-Label Learning (CCML) method to train deep classifiers under input-dependent (heteroscedastic) multi-label noise in the MLC problems. The proposed CCML identifies, ranks, and corrects noisy multi-label images through four main modules: 1) group lasso module; 2) discrepancy module; 3) flipping module; and 4) swap module. The group lasso module detects the potentially noisy labels by estimating the label uncertainty based on the aggregation of two collaborative networks. The discrepancy module ensures that the two networks learn diverse features, while obtaining the same predictions. The flipping module corrects the identified noisy labels, and the swap module exchanges the ranking information between the two networks. The experiments conducted on the multi-label RS image archive IR-BigEarthNet confirm the robustness of the proposed CCML under extreme multi-label noise rates.
A Novel Triplet Sampling Method for Multi-Label Remote Sensing Image Search and Retrieval
May 08, 2021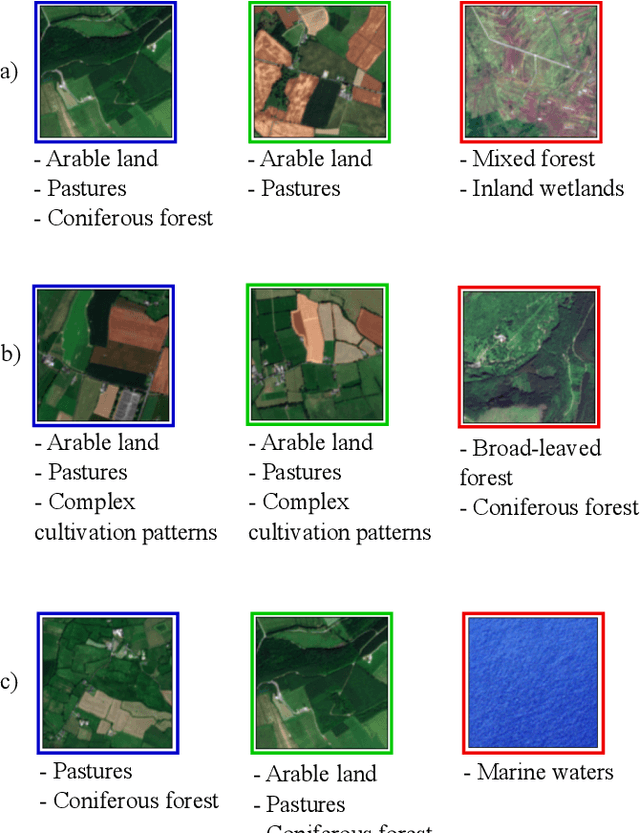
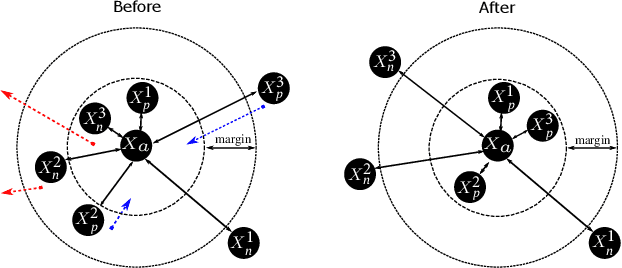
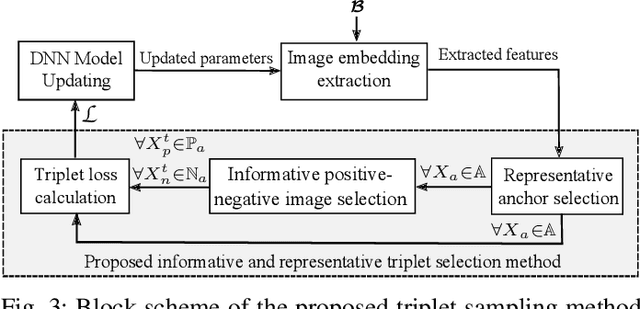

Learning the similarity between remote sensing (RS) images forms the foundation for content based RS image retrieval (CBIR). Recently, deep metric learning approaches that map the semantic similarity of images into an embedding space have been found very popular in RS. A common approach for learning the metric space relies on the selection of triplets of similar (positive) and dissimilar (negative) images to a reference image called as an anchor. Choosing triplets is a difficult task particularly for multi-label RS CBIR, where each training image is annotated by multiple class labels. To address this problem, in this paper we propose a novel triplet sampling method in the framework of deep neural networks (DNNs) defined for multi-label RS CBIR problems. The proposed method selects a small set of the most representative and informative triplets based on two main steps. In the first step, a set of anchors that are diverse to each other in the embedding space is selected from the current mini-batch using an iterative algorithm. In the second step, different sets of positive and negative images are chosen for each anchor by evaluating relevancy, hardness, and diversity of the images among each other based on a novel ranking strategy. Experimental results obtained on two multi-label benchmark achieves show that the selection of the most informative and representative triplets in the context of DNNs results in: i) reducing the computational complexity of the training phase of the DNNs without any significant loss on the performance; and ii) an increase in learning speed since informative triplets allow fast convergence. The code of the proposed method is publicly available at https://git.tu-berlin.de/rsim/image-retrieval-from-triplets.
CCML: A Novel Collaborative Learning Model for Classification of Remote Sensing Images with Noisy Multi-Labels
Dec 27, 2020
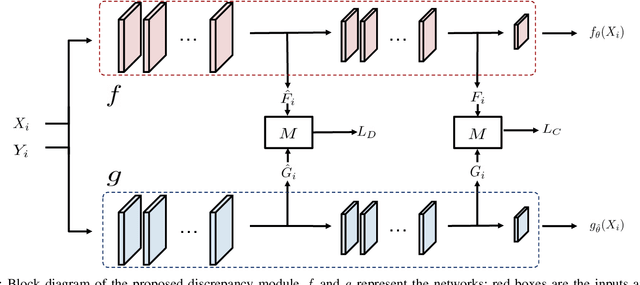
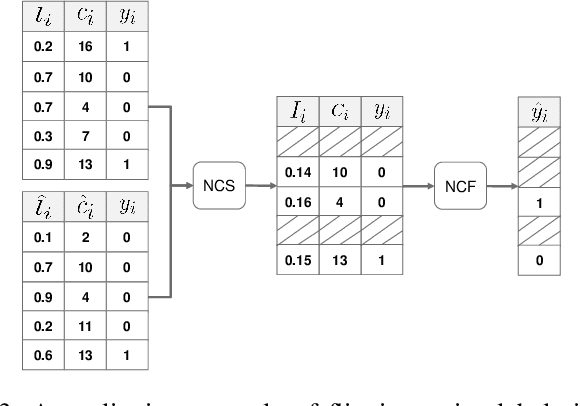
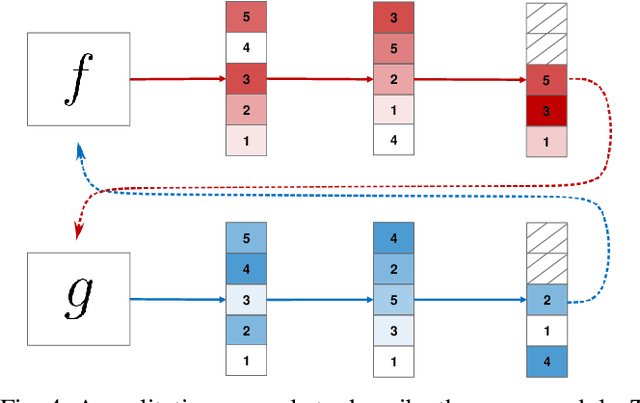
The development of accurate methods for multi-label classification (MLC) of remote sensing (RS) images is one of the most important research topics in RS. Deep Convolutional Neural Networks (CNNs) based methods have triggered substantial performance gains in RS MLC problems, requiring a large number of reliable training images annotated by multiple land-cover class labels. Collecting such data is time-consuming and costly. To address this problem, the publicly available thematic products, which can include noisy labels, can be used for annotating RS images with zero-labeling cost. However, multi-label noise (which can be associated with wrong as well as missing label annotations) can distort the learning process of the MLC algorithm, resulting in inaccurate predictions. The detection and correction of label noise are challenging tasks, especially in a multi-label scenario, where each image can be associated with more than one label. To address this problem, we propose a novel Consensual Collaborative Multi-Label Learning (CCML) method to alleviate the adverse effects of multi-label noise during the training phase of the CNN model. CCML identifies, ranks, and corrects noisy multi-labels in RS images based on four main modules: 1) group lasso module; 2) discrepancy module; 3) flipping module; and 4) swap module. The task of the group lasso module is to detect the potentially noisy labels assigned to the multi-labeled training images, and the discrepancy module ensures that the two collaborative networks learn diverse features, while obtaining the same predictions. The flipping module is designed to correct the identified noisy multi-labels, while the swap module task is devoted to exchanging the ranking information between two networks. Our code is publicly available online: http://www.noisy-labels-in-rs.org