 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Unsupervised Contrastive Hashing for Large-Scale Cross-Modal Text-Image Retrieval in Remote Sensing
Paper and Code
Jan 20, 2022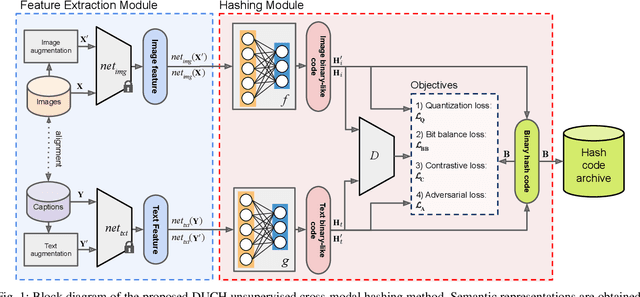
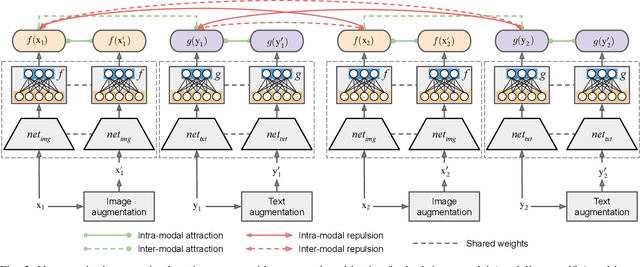

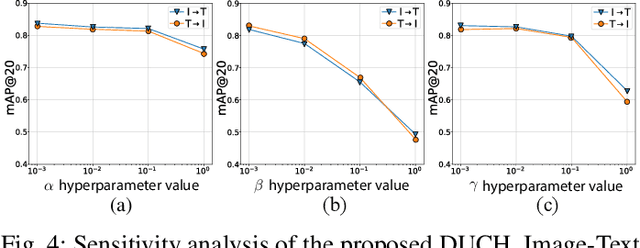
Due to the availability of large-scale multi-modal data (e.g., satellite images acquired by different sensors, text sentences, etc) archives, the development of cross-modal retrieval systems that can search and retrieve semantically relevant data across different modalities based on a query in any modality has attracted great attention in RS. In this paper, we focus our attention on cross-modal text-image retrieval, where queries from one modality (e.g., text) can be matched to archive entries from another (e.g., image). Most of the existing cross-modal text-image retrieval systems require a high number of labeled training samples and also do not allow fast and memory-efficient retrieval due to their intrinsic characteristics. These issues limit the applicability of the existing cross-modal retrieval systems for large-scale applications in RS. To address this problem, in this paper we introduce a novel deep unsupervised cross-modal contrastive hashing (DUCH) method for RS text-image retrieval. The proposed DUCH is made up of two main modules: 1) feature extraction module (which extracts deep representations of the text-image modalities); and 2) hashing module (which learns to generate cross-modal binary hash codes from the extracted representations). Within the hashing module, we introduce a novel multi-objective loss function including: i) contrastive objectives that enable similarity preservation in both intra- and inter-modal similarities; ii) an adversarial objective that is enforced across two modalities for cross-modal representation consistency; iii) binarization objectives for generating representative hash codes. Experimental results show that the proposed DUCH outperforms state-of-the-art unsupervised cross-modal hashing methods on two multi-modal (image and text) benchmark archives in RS. Our code is publicly available at https://git.tu-berlin.de/rsim/duch.